Инициализация весовых векторов Т
Из ранее рассмотренного примера обучения сети можно было видеть, что правило двух третей приводит к вычислению вектора С как функции И между входным вектором Х и выигравшим соревнование запомненным вектором Тj. Следовательно, любая компонента вектора С будет равна единице в том случае, если соответствующие компоненты обоих векторов равны единице. После обучения эти компоненты вектора Тj остаются единичными; все остальные устанавливаются в нуль.
Это объясняет, почему веса tij должны инициализироваться единичными значениями. Если бы они были проинициализированы нулевыми значениями, все компоненты вектора С были бы нулевыми независимо от значений компонент входного вектора, и обучающий алгоритм предохранял бы веса от изменения их нулевых значений.
Обучение может рассматриваться как процесс «сокращения» компонент запомненных векторов, которые не соответствуют входным векторам. Этот процесс необратим, если вес однажды установлен в нуль, обучающий алгоритм никогда не восстановит его единичное значение.
Это свойство имеет важное отношение к процессу обучения. Предположим, что группа точно соответствующих векторов должна быть классифицирована к одной категории, определяемой возбуждением одного нейрона в слое распознавания. Если эти вектора последовательно предъявляются сети, при предъявлении первого будет распределяться нейрон распознающего слоя, его веса будут обучены с целью соответствия входному вектору. Обучение при предъявлении остальных векторов будет приводить к обнулению весов в тех позициях, которые имеют нулевые значения в любом из входных векторов. Таким образом, запомненный вектор представляет собой логическое пересечение всех обучающих векторов и может включать существенные характеристики данной категории весов. Новый вектор, включающий только существенные характеристики, будет соответствовать этой категории. Таким образом, сеть корректно распознает образ, никогда не виденный ранее, т. е. реализуется возможность, напоминающая процесс восприятия человека.
Настройка весовых векторов Вj
Выражение, описывающее процесс настройки весов (выражение (8.6) повторено здесь для справки) является центральным для описания процесса функционирования сетей APT.
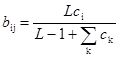 (8.6)
(8.6)
Сумма в знаменателе представляет собой количество единиц на выходе слоя сравнения. Эта величина может быть рассмотрена как «размер» этого вектора. В такой интерпретации «большие» векторы С производят более маленькие величины весов bij, чем «маленькие» вектора С. Это свойство самомасштабирования делает возможным разделение двух векторов в случае, когда один вектор является поднабором другого; т. е. когда набор единичных компонент одного вектора составляет подмножество единичных компонент другого.
Чтобы продемонстрировать проблему, возникающую при отсутствии масштабирования, используемого в выражении (8.6), предположим, что сеть обучена двум приведенным ниже входным векторам, при этом каждому распределен нейрон в слое распознавания.
Заметим, что Х1 является поднабором Х2. В отсутствие свойства масштабирования веса bij и tij получат значения, идентичные значениям входных векторов. Если начальные значения выбраны равными 1,0, веса образов будут иметь следующие значения:
Если Х прикладывается повторно, оба нейрона в слое распознавания получают одинаковые активации; следовательно, нейрон 2, ошибочный нейрон, выиграет конкуренцию.
Кроме выполнения некорректной классификации, может быть нарушен процесс обучения. Так как Т2 равно 1 1 1 0 0, только первая единица соответствует единице входного вектора, и С устанавливается в 1 0 0 0 0, критерий сходства удовлетворяется и алгоритм обучения устанавливает вторую и третью единицы векторов Т2 и В2 в нуль, разрушая запомненный образ.
Масштабирование весов bij предотвращает это нежелательное поведение. Предположим, что в выражении (8.2) используется значение L=2, тем самым определяя следующую формулу:
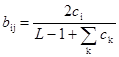
Значения векторов будут тогда стремиться к величинам
Подавая на вход сети вектор Х1 , получим возбуждающее воздействие 1,0 для нейрона 1 в слое распознавания и ½ для нейрона 2; таким образом, нейрон 1 (правильный) выиграет соревнование. Аналогично предъявление вектора Х2 вызовет уровень возбуждения 1,0 для нейрона 1 и 3/2 для нейрона 2, тем самым снова правильно выбирая победителя.
Инициализация весов bij
Инициализация весов bij малыми значениями является существенной для корректного функционирования систем APT. Если они слишком большие, входной вектора который ранее был запомнен, будет скорее активизировать несвязанный нейрон, чем ранее обученный. Выражение (8.1), определяющее начальные значения весов, повторяется здесь для справки
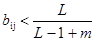 для всех i, j, (8.1)
для всех i, j, (8.1)
Установка этих весов в малые величины гарантирует, что несвязанные нейроны не будут получать возбуждения большего, чем обученные нейроны в слое распознавания. Используя предыдущий пример с L=2, т=5 и bij<1/3, произвольно установим bij=1/6. С такими весами предъявление вектора, которому сеть была ранее обучена, приведет к более высокому уровню активации для правильно обученного нейрона в слое распознавания, чем для несвязанного нейрона. Например, для несвязанного нейрона Х1 будет производить возбуждение 1/6, в то время как Х2 будет производить возбуждение ½; и то и другое ниже возбуждения для обученных нейронов.
Поиск.Может показаться, что в описанных алгоритмах отсутствует необходимость наличия фазы поиска за исключением случая, когда для входного вектора должен быть распределен новый несвязанный нейрон. Это не совсем так; предъявление входного вектора, сходного, но не абсолютно идентичного одному из запомненных образов, может при первом испытании не обеспечить выбор нейрона слоя распознавания с уровнем сходства большим р, хотя такой нейрон будет существовать.
Как и в предыдущем примере, предположим, что сеть обучается следующим двум векторам:
X1 = 1 0 0 0 0
X2 = 1 1 1 0 0
с векторами весовВi, обученными следующим образом
B1 = 1 0 0 0 0
B2 = ½ ½ ½ 0 0
Теперь приложим входной вектор X3 = 1 1 0 0 0. В этом случае возбуждение нейрона 1 в слое распознавания будет 1,0, а нейрона 2 только 2/3. Нейрон 1 выйдет победителем (хотя он не лучшим образом соответствует входному вектору), вектор С получит значение 1 1 0 0 0, S будет равно ½. Если уровень сходства установлен в 3/4, нейрон 1 будет заторможен и нейрон 2 выиграет состязание. С станет равным 1 1 0 0 0, S станет равным 1, критерий сходства будет удовлетворен и поиск закончится.
Дата добавления: 2015-04-03; просмотров: 1012;