Моделирование программного текста системы
При разработке сложных систем программный текст (исходный код) разбросан по многим файлам исходного кода. При использовании Java исходный код сохраняется в .java-файлах, при использовании C++ — в заголовочных файлах (.h-фай-лах) и телах (.срр-файлах), при использовании Ada 95 — в спецификациях (.ads-файлах) и реализациях (.adb-файлах).
Между файлами существуют многочисленные зависимости компиляции. Если к этому добавить, что по мере разработки рождаются новые версии файлов, то становится очевидной необходимость управления конфигурацией системы, визуализации компиляционных зависимостей.
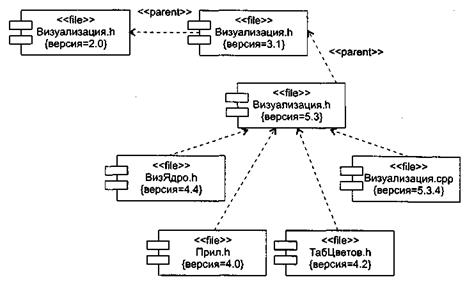
Рис. 13.10.Моделирование исходного кода
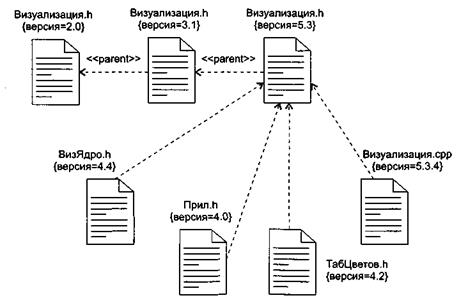
Рис. 13.11. Моделирование исходного кода с использованием пиктограмм
В качестве примера на рис. 13.10 приведена компонентная диаграмма, где изображены файлы исходного кода, используемые для построения библиотеки Визуализация.dll. Имеются четыре заголовочных файла (Визуализация.h, ВизЯдро.h, Прил.h, ТабЦветов.h), которые представляют исходный код для спецификации определенных классов. Файл реализации здесь один (Визуализация.срр), он является реализацией одного из заголовков. Отметим, что для каждого файла явно указана его версия, причем для файла Визуализация.h показаны три версии и история их появления. На рис. 13.11 повторяется та же диаграмма, но здесь для обозначения компонентов использованы специальные пиктограммы.
Дата добавления: 2015-03-07; просмотров: 862;