Кластерный анализ
Знакомство с возможностями кластерного анализа в ППП Statistica приводится на примере анализа уровня жизни населения различных регионов. Задача состоит в том, чтобы разбить регионы на несколько групп, в которых регионы мало отличаются друг от друга (существенно меньше, чем в целом).
 Примечание Примечание
|
| Задача эта сложна, так как сравнивать регионы нужно не по какому-то одному параметру, а по несколькимпараметрам одновременно |
Кластерный анализ производится при помощи модуля «Statistics/Multivariate Exploratory/ Cluster Analysis». После выбора данного модуля отобразиться диалоговой окно выбора метода проведения кластерного анализа (рис.):
Рисунок 5.28
1.
2. В строке меню из пункта Статистика выберите модуль Многомерные исследовательские методы подмодуль Анализ кластеров (Cluster Analysis). Откроется стартовая панель модуля Анализ кластеров (Cluster Analysis):
Рис. 3.2. Стартовая панель модуля Кластерный анализ
3. Выберите метод. Для этого посмотрите на стартовую панель, в главной части которой находится список методов кластерного анализа, реализованных в STATISTICA 6.0. В списке методов выбрать k-means clustering (метод k-средних) и нажмите кнопку  в правом верхнем углу панели. Диалоговое окно метода k-meansпоявится на экране:
в правом верхнем углу панели. Диалоговое окно метода k-meansпоявится на экране:

Рис. 3.3. Диалоговое окно метода k-means
4. Выберите переменные для анализа. Нажмите кнопку Variables (Переменные) в левом верхнем углу текущего окна и откроется диалоговое окно: Select variables for the analysis (Выбор переменных для анализа). Нажмите вначале Shift и удерживая эту кнопку на клавиатуре выберите следующие параметры: DISPANCER(S), FIST LIFE(S), DEATH RATE(S), ALCOGOL(S), а затем нажмите кнопку .
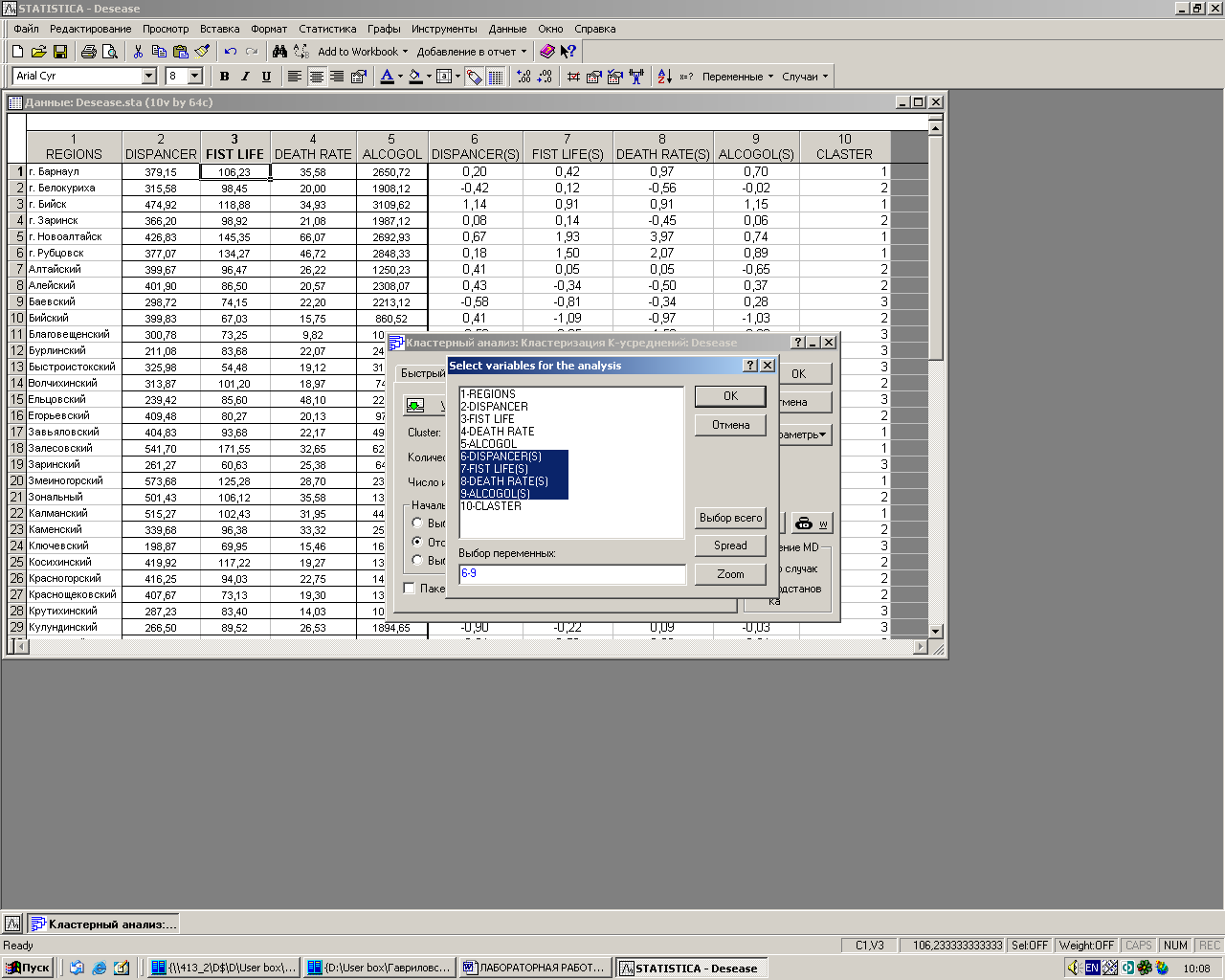
Рис. 3.4. Выбор переменных для Кластерного анализа
5. Установите начальные значения. Посмотрите на поле Cluster (Кластер), находящееся ниже кнопкиVariables (Переменные). Нажав на стрелку в этом поле, выберите пункт меню Cases(rows) (Случаи), так как кластеризуемые районы являются случаями в исходном файле данных.
· В поле Number of clusters (Число кластеров) нужно определить число групп, на которые хотим разбить районы. Запишите в этом поле число 3.
· В строке Number of(iterations) (Число итераций) задается максимальное число итераций, используемых при построении классов. Задайте, например, число 11.
· Группа опций Начальные центры кластера (Initial cluster centres) позволяет задать начальные центры кластеров. Выберете Отсортируйте расстояния и возьмите измерения в постоянных интервалах(Sort distances and take observations at constant intervals).
Вопрос: Изменится ли результаты классификации, если выбрать другие опции Начальные центры кластера (Initial cluster centres)? Проверьте это экспериментально, после того как разберете данный пример.
После того как все установки сделаны, нажмите кнопку в верхнем правом углу окнаk-means clustering (метод k-средних)и запустите вычислительную процедуру.
6. Просмотр результатов кластеризации. В окне результатов в верхней части приведена следующая информация:
· Количество переменных (Number of variables) – 4;
· Число регистров (Number of cases) – 64;
· K-means clustering of cases – Метод кластеризации k-means clustering;
· Количество групп (Number of cluster) – 3;
· Solution was obtained after 3 iterations – Решение найдено после 3 итераций.

Рис. 3.5. Окно результатов кластеризации районов по методу средних
Выберите закладку Расширенный (Advanced). Данное диалоговое окно состоит из двух частей: верхней – информационной, и нижней, где содержатся функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа.
· Функциональная кнопка Кластерные усреднения & евклидова расстояния (Cluster Means&Euclidean Distances) позволяет вывести таблицы, в первой из которых указаны средние для каждого кластера (усреднение производится внутри кластера):
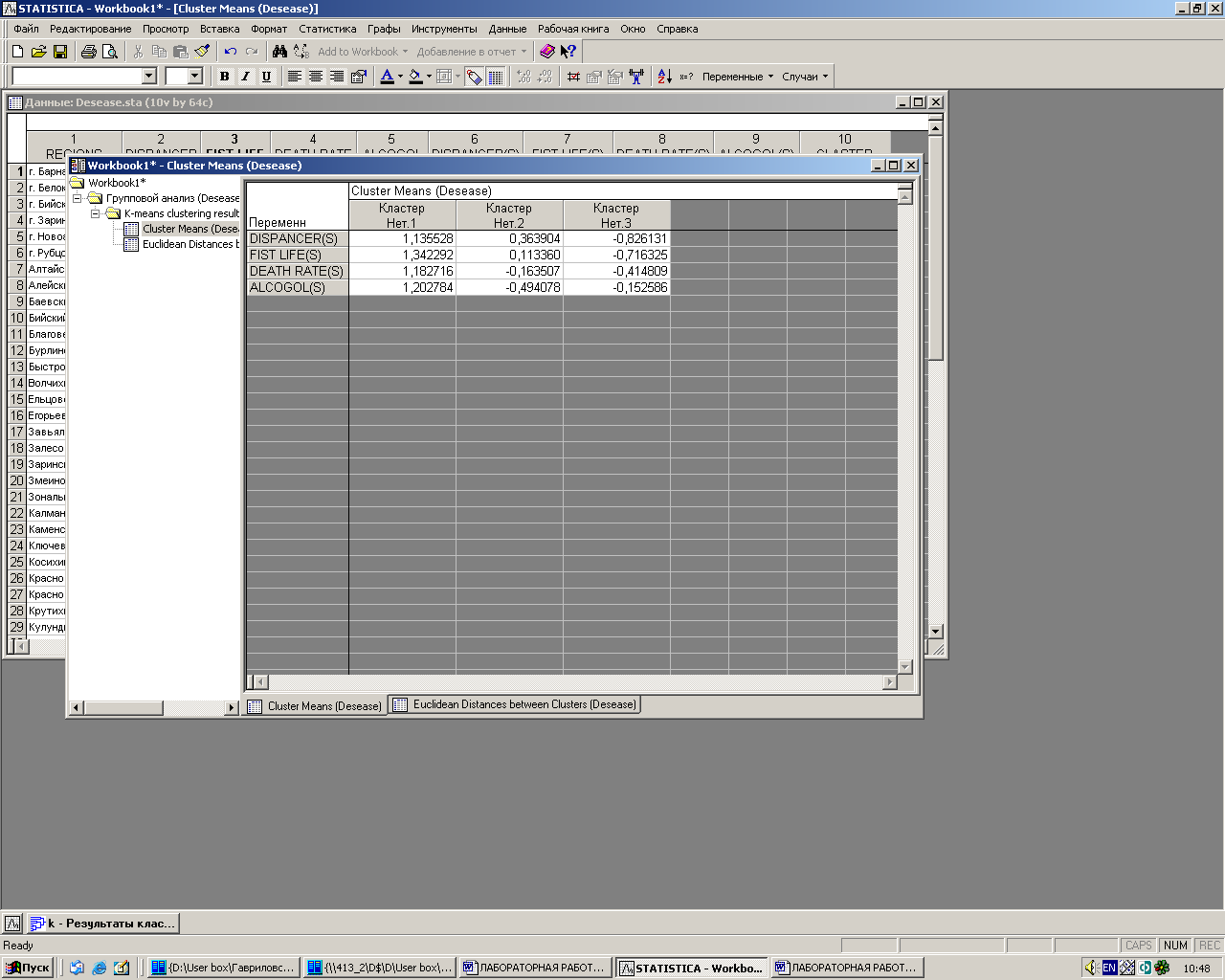
Рис. 3.6. Средние значения для каждого кластера
Во второй таблице указаны, евклидовы расстояния и квадраты евклидовых расстояний между кластерами.

Рис. 3.7. Евклидовы расстояния и квадраты евклидовых расстояний между кластерами
В данной таблице даны евклидовы расстояния между средними кластеров (по каждому из параметров внутри кластера вычисляется среднее, получается 3 точки в пятимерном пространстве, и между ними находится расстояние). Из таблицы видно, что расстояние между первым и вторым кластерами 1,303, а например, между вторым и третьим – 0,755. Над диагональю в таблице даны квадраты расстояний между кластерами.
· Кнопка Анализ дисперсии (Analysis of variation) позволяет просмотреть таблицу дисперсионного анализа, где например, Между SS – внутригрупповая дисперсия (изменчивость), Внутренняя SS – межгрупповая дисперсия.
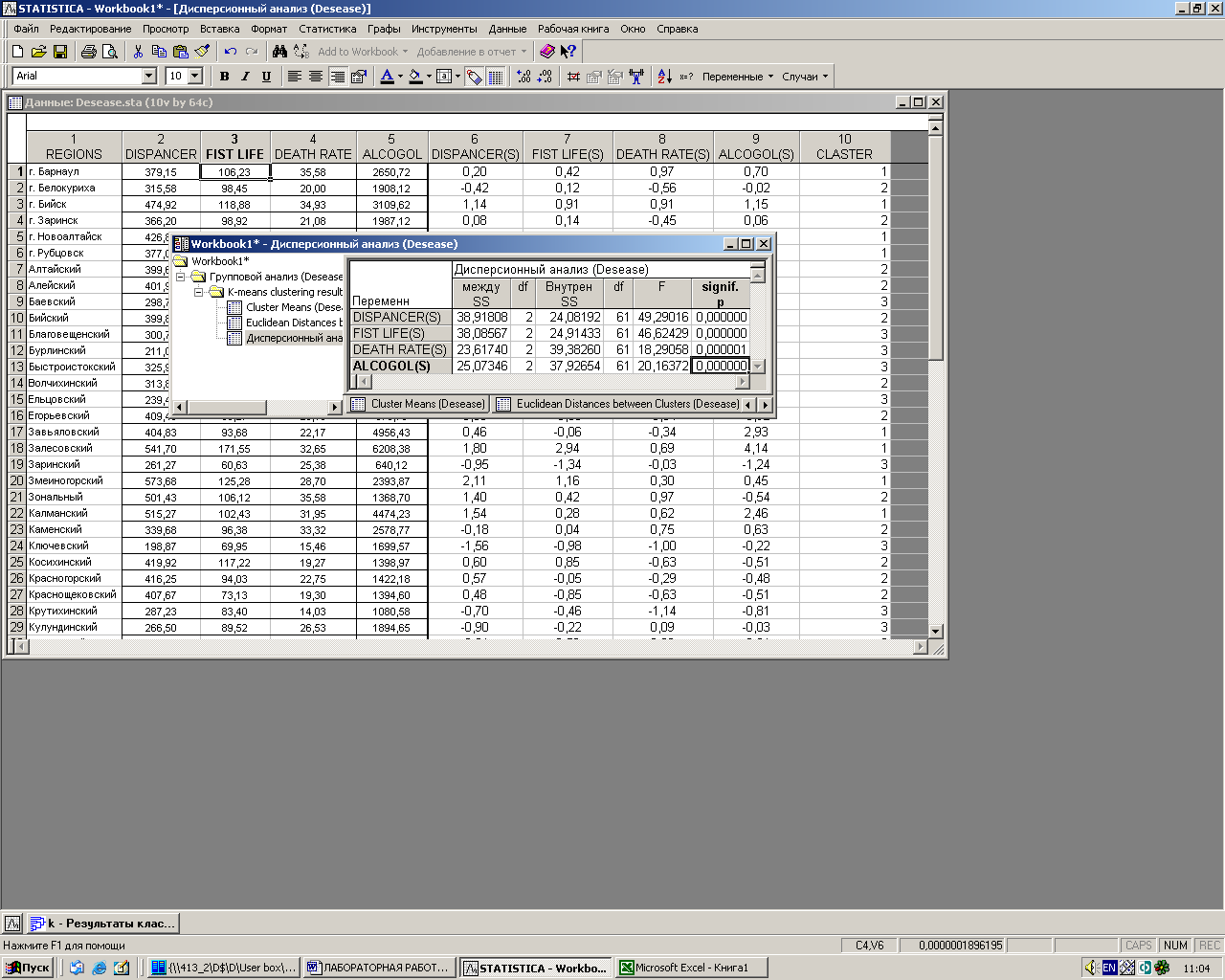
Рис. 3.8. Результаты дисперсионного анализа
· Функциональная кнопка Граф усреднений (Graph of means) позволяет посмотреть средние значения для каждого кластера на линейном графике (графики средних значений характеристик районов для каждого кластера).
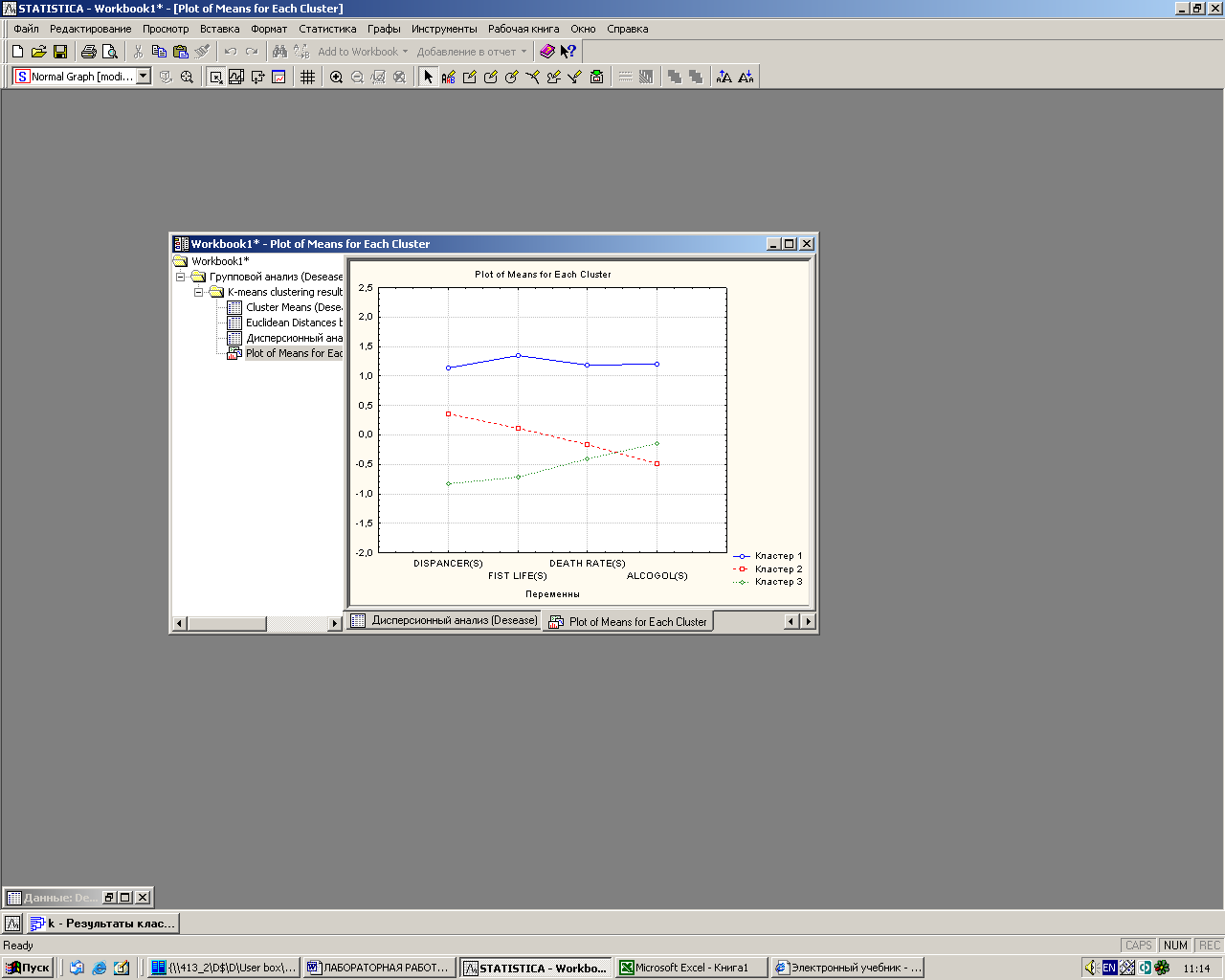
Рис. 3.9. График средних для каждого кластера
· Кнопка Описательная статистика для каждого кластера (Descriptive Statistics for each clusters) открывает электронные таблицы с описательными статистиками для каждого кластера (среднее, стандартное отклонение, дисперсия).
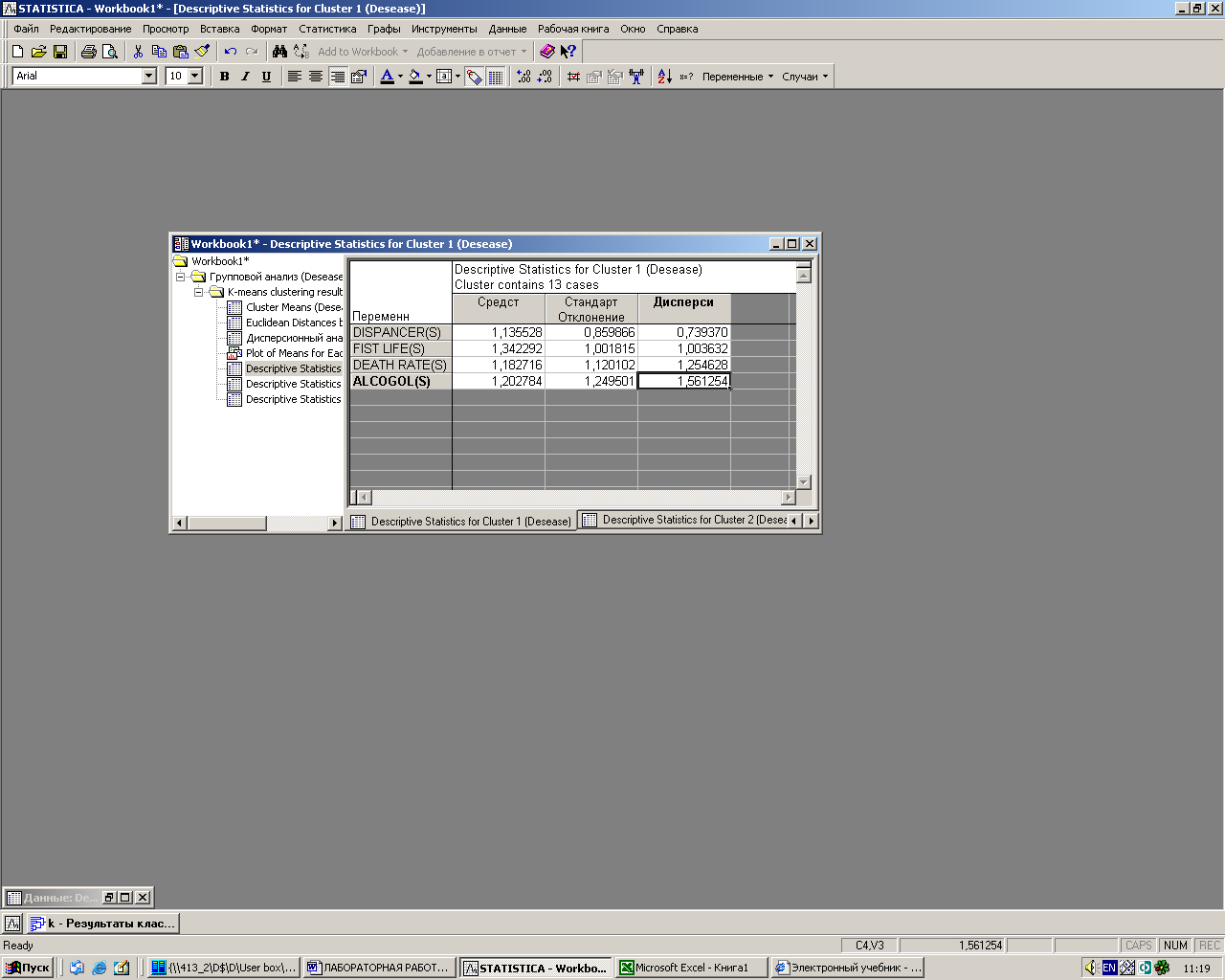
Рис. 3.10. Описательные статистики для первого кластера
· Чтобы посмотреть, как распределились районы по кластерам, нажмите кнопку Элементы каждого кластера & расстояния (Member of each cluster&distances). На экране появятся 3 электронные таблицы с номерами районов, отнесенных к определенным кластерам. В строках таблиц указано расстояние от каждой машины до центра кластера. Например, в первом кластер попало 13 районов с номерами 1, 3, 5, 6, 17,18 и т.д.

Рис. 3.11. Элементы первого кластера и расстояния
· Кнопка Сохранить классификации и расстояния (Save classifications and distances) позволяет сохранить результаты классификации в файле STATISTICAдля дальнейшего исследования, результаты анализа формируются в отдельную таблицу, в которой указаны номера кластеров, в который попал каждый случай (район), и расстояние от центра кластера до каждого случая (района.)
Теперь можно сохранить все полученные результаты в рабочей книге, которая формируется автоматически, для дальнейшей работе с полученными результатами.
7.Изменение числа переменных. Закройте рабочую книгу результатов и вернитесь в начальное окно метода k-means clustering. Нажмите кнопку Variables (Переменные)в левомверхнем углу текущего окна и откройте диалоговое окно Select variables for the analysis (Выбор переменных для анализа). Сделайте в нем установку трех последних параметров: FIST LIFE(S), DEATH RATE(S), ALCOGOL(S).Повторите действия, описанные ранее. Нажмите кнопку Graph of means (График средних),постойте графики средних значений характеристик районов для каждого кластера:
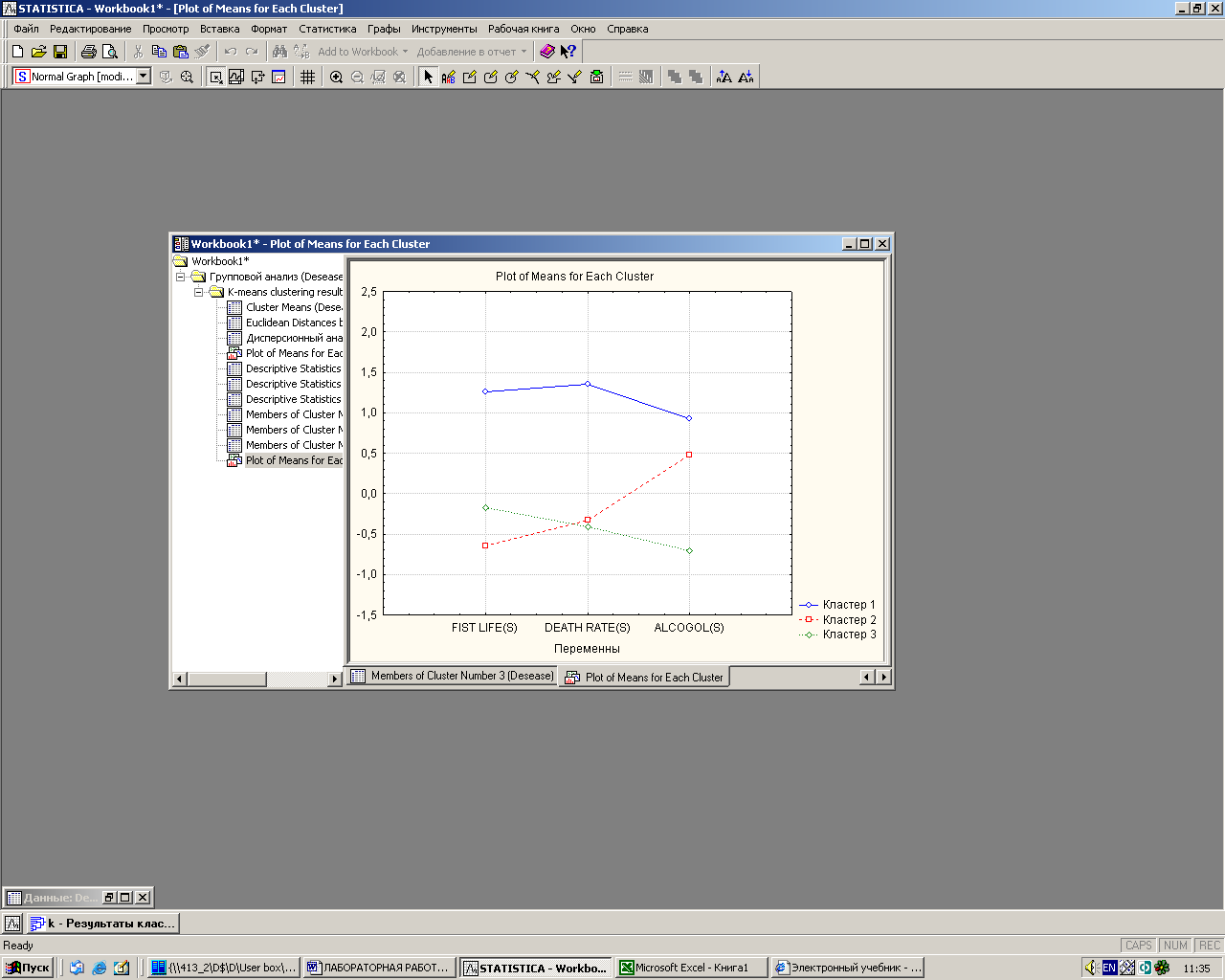
Рис. 3.12. График средних для новых кластеров
Заметьте, что состав групп изменился. Теперь районы более отчетливо группируются, так как изменилась размерность: сократилось число параметров и получилось более отчетливо выраженные группы.
Дата добавления: 2015-01-13; просмотров: 2465;