Теоретические основы. В задачах оптимизации, когда необходимо учитывать некоторый случайный фактор (элемент или явление), который невозможно описать аналитически
В задачах оптимизации, когда необходимо учитывать некоторый случайный фактор (элемент или явление), который невозможно описать аналитически, используют метод моделирования, называемый методом статистических испытаний или методом Монте-Карло [4,5]. С помощью этого метода может быть решена любая вероятностная задача. Однако использовать его целесообразно в том случае, если решить задачу этим методом проще, чем любым другим.
Суть метода состоит в том, что вместо описания случайных явлений аналитическими зависимостями проводится розыгрыш случайного явления с помощью некоторой процедуры, которая дает случайный результат. С помощью розыгрыша получают одну реализацию случайного явления. Осуществляя многократно такой розыгрыш, накапливают статистический материал (множество реализаций случайной величины), который можно обрабатывать статистическими методами. Рассмотрим этот метод на примерах.
Пример 1. Трость длиной L разламывается на три части. Расстояния от начала трости до двух точек перелома – непрерывные случайные величины с равномерным законом распределения. Найти вероятность того, что из получившихся частей можно собрать треугольник.
В теории вероятностей эта задачу называют задачей о «сломанной трости». Эту задачу можно решить методами теории вероятности.
Обозначим через x и y расстояния от левого конца трости первой и второй точек перелома (Рис.1).
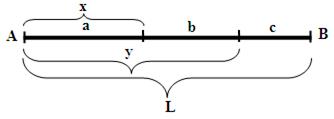
Рис.1. Условные обозначения для задачи о «сломанной трости»
Тогда длины сторон возможного треугольника выражаются через L, x и y следующим образом
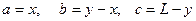
Длины сторон треугольника должны удовлетворять условию: сумма длин двух любых сторон больше (или в вырожденном случае равна) длине третьей стороны. Таким образом, имеем систему неравенств
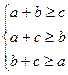
После подстановки длин сторон треугольника через L, x и y получим
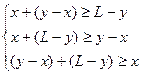
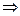
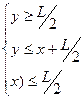
Решение полученной системы неравенств можно наглядно иллюстрировать на двухкоординатной плоскости. (Рис.2). Т.к. величины x и y имеют равномерное распределение на отрезке [0; L], то множеству точек со всевозможными координатами (x;y) соответствует квадрат OPRS со стороной L. Тогда точки, координаты которых удовлетворяют составленной системе неравенств с учётом условия 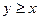 , принадлежат области, ограниченной треугольником ABC. Если провести аналогичные рассуждения для случая
, принадлежат области, ограниченной треугольником ABC. Если провести аналогичные рассуждения для случая 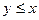 , то получим треугольник CDE.
, то получим треугольник CDE.
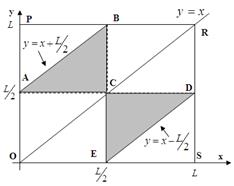
Рис. 2. Графическая иллюстрация решения задачи Примера 1.
Искомая вероятность равна доле суммарной площади треугольников от площади квадрата OPRS
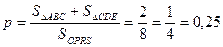
Решим эту задачу методом статистических испытаний. Для этого в приложении MS Excel создадим таблицу, как показано на Рис. 3.
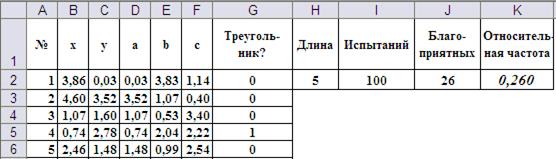
Рис.3. Структура таблицы для решения задачи Примера 1 методом статистических испытаний.
На Рис.4a-b показан ввод формул в ячейки листа для решения задачи Примера 1 методом статистических испытаний.

Рис.4a. Ввод формул для реализации случайного перелома трости и проверки возможности формирования треугольника.
 м
м
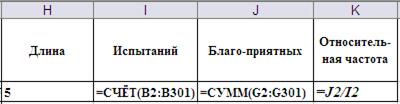
Рис.4b. Ввод формул для обработки серии испытаний.
Моделирование координат точек перелома x и y осуществляется по формулам «=Длина*СЛЧИС()»(см. формулы в ячейках B2 и C2). Встроенная функция СЛЧИС() генерирует случайную величину, равномерно распределённую на отрезке [0;1]. Выбор в качестве стороны a минимального значения 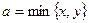 и расчёт сторон b и c по формулам
и расчёт сторон b и c по формулам
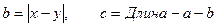
позволяет учесть оба случая, когда и (см. формулы в ячейках D2, E2 и F2).
С помощью логических суперпозиции логических функций ЕСЛИ() и И() в ячейке G2 обеспечивается поверка возможности собрать треугольник из фрагментов трости. При этом возможность кодируется единицей, а невозможность нулём. Такая кодировка позволяет просто подсчитать число благоприятных исходов с помощью функции СУММ() (ячейка J2)
Формулы в ячейках H2, I2, J2 и K2 обеспечивают подсчёт общего числа испытаний, числа благоприятных исходов и их долю в общем числе испытаний.
При каждом нажатии функциональной клавиши F9 Excel пересчитывает функции СЛЧИС() и, таким образом, моделирует новую серию испытаний. В каждой серии получается новое значение вероятности (на Рис. 3 она равна 0,26). В качестве оценки вероятности берут среднее арифметическое от нескольких серий. Усреднение десяти выборочных значений представлено в таблице:

Полученное среднее значение 0,247 близко к значению, рассчитанному теоретически 0,250. На практике такой точности вполне достаточно.
Таким образом, алгоритм метода статистических испытаний сводится к следующему.
· Определить, что собой будет представлять испытание или розыгрыш.
· Определить, какое испытание является успешным, а какое– нет.
· Провести большое количество испытаний.
· Обработать полученные результаты статистическими методами и рассчитать статистические оценки искомых величин.
При проведении статистических испытаний необходимо воспроизводить случайные величины с нужным законом распределения. Приложение MS Excel имеет для этого достаточное число средств. Простейшими является функция СЛЧИС() и СЛУЧМЕЖДУ(a,b). Первая функция генерирует случайное число с равномерным законом распределения на полуинтервале [0;1) (Рис. 5), вторая - случайное число с равномерным законом распределения на интервале (a;b) (Рис. 6).
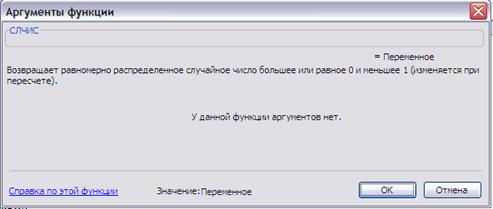
Рис.5. Конструктор функции СЛЧИС().
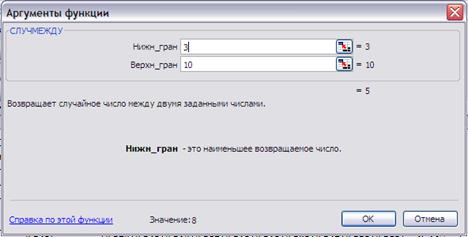
Рис.6. Конструктор функции СЛУЧМЕЖДУ(a;b).
Кроме того, MS Excel располагает надстройкой «Пакет анализа», которая содержит генератор случайных величин с различными функциями распределения (Рис.7).
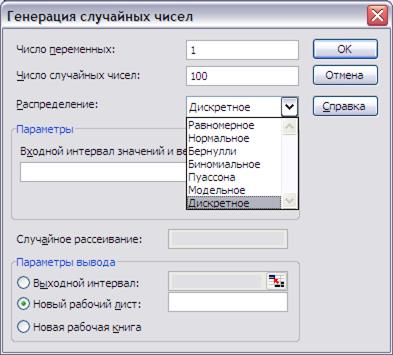
Рис.7. Диалоговое окно генератора случайных чисел.
Перечисленные средства предоставляют практически неограниченные возможности по моделированию случайных величин.
Моделирование события. Пусть необходимо смоделировать появление некоторого события А, вероятность наступления которого равняется Р(А)=Р. Это можно смоделировать суперпозицией функций:
=ЕСЛИ(СЛЧИС()<=P; “произошло событие А”; “событие А не произошло”)
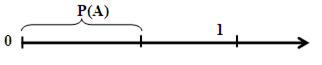
Рис. 8. Вероятность наступления события А
Моделирование группы несовместимых событий. Пусть есть группа несовместимых событий А1, А2,..,.Аk. Известны вероятности наступления событий Р(А1), Р(А2),..., Р(Аk). Тогда из-за несовместимости испытаний 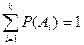 . На отрезке [0, 1] отложим эти вероятности (Рис. 9).
. На отрезке [0, 1] отложим эти вероятности (Рис. 9).
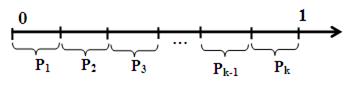
Рис. 9. Вероятности наступления группы несовместимых событий
Если число, сгенерированное функцией СЛЧИС() попало в i-ый интервал, то произошло событие Аi.
Моделирование условного события. Моделирование условного события B, которое происходит при условии, что наступило событие A с вероятностью Р(B/A), показано на рис. 10. Сначала моделируем событие A. Если событие A происходит, то моделируем наступление события B, если имеем 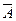 , то не моделируем наступление события B.
, то не моделируем наступление события B.
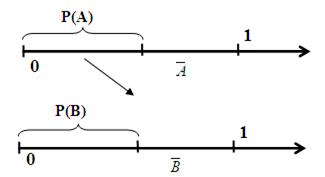
Рис. 10. Моделирование условного события B
Рассмотрим пример на моделирование условных событий.
Пример 2. В сборочный цех поступили детали с трех предприятий. На первом предприятии изготовлено 51% деталей от их общего количества, на втором предприятии 24% и на третьем 25%. При этом на первом предприятии было изготовлено 90% деталей первого сорта, на втором 80% и на третьем 70%. a) Какова вероятность того, что взятая наугад деталь окажется первого сорта? b) Какова условная вероятность того, что если взятая наугад деталь оказалась бракованной, она была изготовлена на первом предприятии?
Решение:Сначала решим задачу по формулам, используя соответствующие формулы теории вероятностей.
a) Пусть A - cобытие, состоящее в том, что взятая деталь окажется первого сорта, а H1, H2 и H3 - гипотезы, что она изготовлена соответственно на 1, 2 и 3 предприятии. Вероятности этих гипотез соответственно равны:
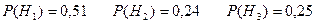
Далее, из условия задачи следует, что:

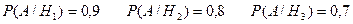
Используя формулу полной вероятности, получим искомую вероятность
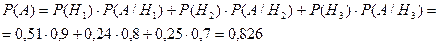
b) Изделие выбирается наудачу из всей произведённой продукции и оказывается бракованным. Рассмотрим три гипотезы: Hi – деталь изготовлена на i-ом предприятии i=1,2,3. Вероятности этих событий даны:
Пусть изделие оказалось бракованным. Условные вероятности этого по отдельным предприятиям:
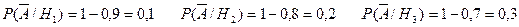
Тогда искомая условная вероятность считается как доля бракованных изделий первого предприятия относительно общего числа брака:
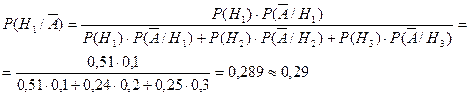
Итак, задача решена. Её решение потребовало знаний соответствующих разделов теории вероятностей, в частности, формул расчёта полной и условной вероятностей. При решении задачи методом статистических испытаний этих соотношений можно не знать.
Исходные данные рационально организовать, как показано на Рис.11. Таблицы вероятностей дополнены тремя столбцами «Просмотр», «Результат» и «Номер события». Это необходимо для реализации моделирования группы несовместимых событий и моделирования условных событий. На Рис.12 данный фрагмент листа представлен в режиме показа формул. В столбце «Просмотр» сформирована сумма вероятностей нарастающим итогом. Тем самым формируются границы событий согласно идее, представленной на Рис.9. Моделирование наступления одного из несовместимых событий реализуется по следующей схеме:
· моделирование с помощью функции СЛЧИС() случайной величины с равномерным законом распределения на полуинтервале [0;1);
· поиск полученного значения с помощью функции ПРОСМОТР() в столбце «Просмотр» и извлечение из таблицы названия события из столбца «Результат» или его условного номера из столбца «Номер события».
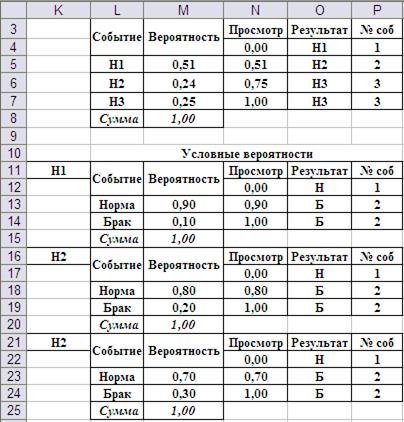
Рис. 11. Организация таблиц исходных данных
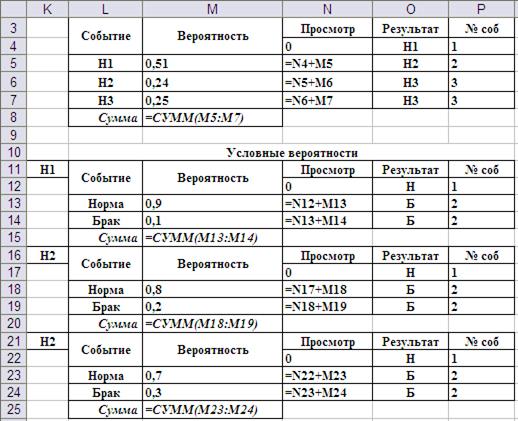
Рис. 12. Ввод формул в исходные таблицы данных
На Рис. 13-14a)-c) показаны, соответственно, общий вид таблицы статистического моделирования и введённые формулы. Выбор значений условных вероятностей брака и деталей первого сорта из таблиц осуществляется с помощью суперпозиции функций ПРОСМОТР() и СМЕЩ(). Первая осуществляет непосредственно выбор из таблицы, а обращение к нужной таблице в зависимости от номера смоделированного предприятия происходит с помощью функции СМЕЩ(). Для этого таблицы условных вероятностей должны располагаться с одинаковым шагом (в данном случае с шагом 5).
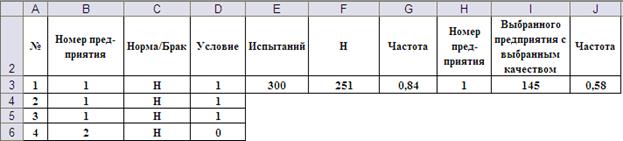
Рис. 13. Общий вид таблицы статистических испытаний

a)
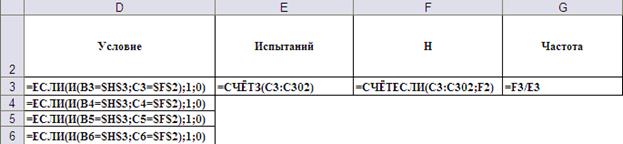
b)

c)
Рис. 14. Ввод формул в таблицу статистических испытаний
Усреднение результатов проведённого моделирования в соответствии с пунктами задания Примера 2 приведено в таблицах:


Отмечаем близость полученных результатов моделирования к теоретическим расчётам.
Метод статистических испытаний может успешно применяться для решения многих других задач, имеющих детерминистский характер. В частности, этим методом наглядно, правда приблизительно, решаются задачи линейного и нелинейного программирования, задачи построения множеств точек, координаты которых удовлетворяют системе неравенств.
Алгоритм решения сводится к следующему:
· моделирование случайного множества точек в n-мерном пространстве;
· выбор из сформированного множества подмножества точек, координаты которых удовлетворяют системе ограничений;
· выбор из полученного подмножества за счёт сортировки в нужном порядке точки, с максимальным или минимальным значением целевой функции;
· построение для двухмерного случая области ограничения на переменные.
На Рис. 15 показана полученная по этому алгоритму область ограничения на переменные X и Y при решении следующей нелинейной оптимизационной задачи:
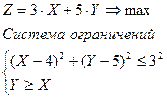
Оптимальное решение достигается в точке с координатами: X=5,53; Y=7,54, в которой целевая функция принимает значение Zmax=54,28. Точное решение, полученное с помощью средства «Поиск решения»: X=5,54; Y=7,57, Zmax=54,49. Иллюстрация точного решения показана на Рис.16. Как видим, погрешность удовлетворяет практическим требованиям.
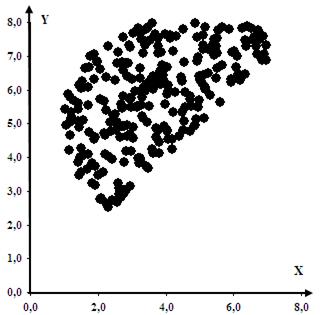
Рис. 15. Область ограничений, построенная методом статистических испытаний.
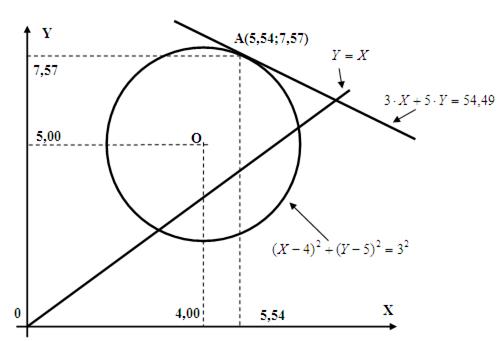
Рис. 16. Графическая иллюстрация точного решения задачи нелинейной оптимизации.
Дата добавления: 2015-02-19; просмотров: 1242;