Основные принципы настройки и ускорения программ в OpenMP
В этом разделе остановимся на основных стратегиях настройки и ускорения программ с использованием OpenMP.
В первую очередь следует отметить, что при настройке программ в OpenMP по возможности следует применять средства автоматизированного распараллеливания программ.
В настоящее время все основные компиляторы Fortran и C/C++, предназначенные для разработки параллельных программ с использованием OpenMP, имеют возможности автоматического распараллеливания[1].
Чтобы найти и локализовать наиболее трудоемкие участки программы, можно воспользоваться возможностью профилирования (profiling) программы.
В настоящее время этот процесс также в значительной степени автоматизирован. Существуют различные сервисные программы, позволяющие проводить профилирование разрабатываемых параллельных программ. Такие сервисные программы созданы различными производителями системного программного обеспечения, в том числе и компанией Intel. В состав набора программ Intel Threading Tools входит программа Intel Thread Profiler. В составе программы Intel VTune Performance Analyzer имеются и другие средства профилирования программ.
При профилировании программы важно выделить ее критический путь. Критический путь в многопоточной программе - это наиболее протяженный путь на диаграмме выполнения потоков. Для его определения необходимо провести анализ диаграммы выполнения потоков в многопоточной параллельной программе. Пример такой диаграммы приведен на рис.2.6.1.
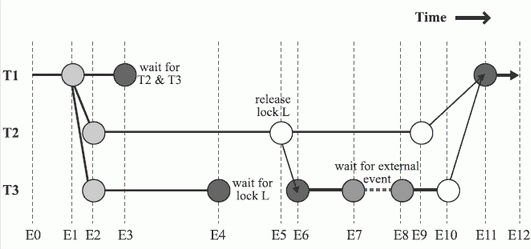
Рис. 2.6.1. Диаграмма потоков в многопоточной программе
На этом рисунке через T1, T2 и T3 обозначены потоки в программе, а через E1, E2, …, Е12 - события в программе. Длина отрезков на диаграмме соответствует времени выполнения потоков. Образование параллельных потоков требует определенных временных затрат, что и отражено на диаграмме.
После профилирования программы и анализа результатов в настраиваемую программу рекомендуется добавить инструкции OpenMP для распараллеливания наиболее затратных участков. В первую очередь это касается потоков, составляющих критический путь в программе.
В случае недостаточно эффективного распараллеливания программы с использованием OpenMP следует обратить самое пристальное внимание:
- на распараллеливание конструкции for. Надо обязательно учитывать высокую трудоемкость инициализации параллельных потоков;
- на неэффективность распараллеливания небольших циклов;
- на несбалансированность потоков;
- на недопустимость многочисленных ссылок к переменным в общей памяти;
- на ограниченный объем кэш-памяти;
- на высокую стоимость операции синхронизации;
- на значительные задержки доступа к удаленной общей памяти (на NUMA-компьютерах).
При распараллеливании вложенных циклов следует сначала распараллеливать внешние петли. Также следует иметь в виду, что петли циклов по объему вычислений могут быть зачастую "треугольными" и порождать несбалансированные параллельные потоки. Чтобы избежать несбалансированности при работе программы, следует правильно использовать возможности директивы OpenMP schedule.
Дата добавления: 2015-02-03; просмотров: 1161;