Индексы
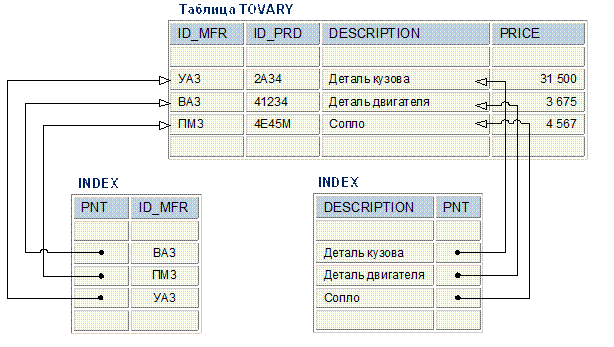
Одним из структурных элементов физической памяти, присутствующим в большинстве реляционных СУБД, является индекс. Индекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов. На Рис. 2.11 изображена таблица TOVARY и два созданных для нее индекса. Один из индексов обеспечивает быстрый доступ к таблице на основе столбца DESCRIPTION. Другой обеспечивает доступ на основе первичного ключа таблицы, представляющего собой комбинацию столбцов ID_MFR и ID_PRD.
СУБД пользуется индексом так же, как вы пользуетесь предметным указателем книги. В индексе хранятся значения данных и указатели на строки, где эти данные встречаются. Данные в индексе располагаются в убывающем или возрастающем порядке, чтобы СУБД могла быстро найти требуемое значение. Затем по указателю СУБД может быстро локализовать строку, содержащую искомое значение.
Наличие или отсутствие индекса совершенно незаметно для пользователя, обращающегося к таблице. Рассмотрим, например, такую инструкцию SELECT:
Найти количество и цену изделия 2А34.
SELECT COUNT, PRICE
FROM TOVARY
WHERE DESCRIPTION = `2А34`
|
| Рис. 2.11 - Множественные отношения предок/потомок в реляционной базе данных |
В инструкции ничего не говорится о том, имеется ли индекс для столбца Описание или нет, и СУБД выполнить запрос в любом случае.
Если бы индекса для столбца DESCRIPTION не существовало, то СУБД была бы вынуждена выполнять запрос путем последовательного «сканирования» таблицы TOVARY, строка за строкой, просматривая в каждой строке столбец DESCRIPTION. Для получения гарантии того, что она нашла все строки, удовлетворяющие условию отбора, СУБД должна просматривать каждую строку таблицы. Если таблица имеет тысячи и миллионы строк, то ее просмотр может занять минуты и даже часы.
Если для столбца DESCRIPTION имеется индекс, СУБД находит требуемые данные с гораздо меньшими усилиями. Она просматривает индекс, чтобы найти требуемое значение (изделие 2А34), а затем с помощью указателя находит требуемую строку (строки) таблицы. Поиск в индексе осуществляется достаточно быстро, так как индекс отсортирован и его строки очень короткие. Переход от индекса к строке (строкам) также происходит очень быстро, поскольку в индексе содержится информация о том, где на диске располагается эта строка.
Как видно из этого примера, индекс имеет то преимущество, что он в огромной степени ускоряет выполнение инструкций SQL с условиями отбора, имеющими ссылки на индексный столбец (столбцы). К недостаткам индекса относится то, что, во-первых, он занимает на диске дополнительное место и, во-вторых, индекс необходимо обновлять каждый раз, когда в таблицу добавляется строка или обновляется индексный столбец таблицы. Это требует дополнительных затрат на выполнение инструкций INSERT и UPDATE, которые обращаются к данной таблице.
В общем, полезно создавать индекс лишь для тех столбцов, которые часто используются в условиях отбора. Индексы удобны также в тех случаях, когда инструкции SELECT обращаются к таблице гораздо чаще, чем инструкции INSERT и UPDATE. СУБД всегда создает индекс для первичного ключа таблицы, так как ожидает, что доступ к таблице чаще всего будет осуществляться через первичный ключ.
Дата добавления: 2015-02-03; просмотров: 1222;