Какое значение приняла случайная величина X?
Если случайная величина Х дискретна, т. е. имеет значения х1, x2, ..., xk с вероятностями р1, р2, ..., pk, то, очевидно, случай сводится к предыдущему. Теперь рассмотрим случай, когда случайная величина непрерывна и имеет заданную плотность вероятности f(x). Чтобы разыграть ее значение, достаточно осуществить следующую процедуру: перейти от плотности вероятности f(x) к функции распределения F(r) по формуле
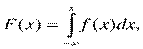 (23.1)
(23.1)
затем найти для функции ^ F обратную ей функцию Ψ. Затем разыграть случайное число R от 0 до 1 и взять от него эту обратную функцию:
X=Ψ(R). (23.2)
Можно доказать (мы этого делать не будем), что полученное значение Х имеет как раз нужное нам распределение f(x).
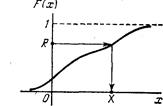
Графически процедура розыгрыша значения Х показана на рис. 23.3. Разыгрывается число R от 0 до 1 и для него ищется такое значение X, при котором F(X) = R (это показано стрелками на рис. 23.3).
Рис. 23.3.
На практике часто приходится разыгрывать значение случайной величины, имеющей нормальное распределение. Для нее, как для любой непрерывной случайной величины, правило розыгрыша (23.2) остается справедливым, но можно поступать и иначе (проще). Известно, что (согласно центральной предельной теореме теории вероятностей) при сложении достаточно большого числа независимых случайных величин с одинаковыми распределениями получается случайная величина, имеющая приближенно нормальное распределение. На практике, чтобы получить нормальное распределение, достаточно сложить шесть экземпляров случайного числа от 0 до 1. Сумма этих шести чисел
Z = R1, + R2 + ... + R6 (23.3)
имеет распределение, настолько близкое к нормальному, что в большинстве практических задач им можно заменить нормальное. Для того чтобы математическое ожидание и среднее квадратическое отклонение этого нормального распределения были равны заданным mx, ơx, нужно подвергнуть величину Z линейному преобразованию и вычислить.
Х = 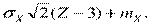 (23.4)
(23.4)
Это и будет нужная нам нормально распределенная случайная величина.
^ 4. Какую совокупность значений приняли случайные величины Х1, Х2,...,Хk? Если случайные величины независимы, то достаточно k раз повторить процедуру, описанную в предыдущем пункте. Если же они зависимы, то разыгрывать каждую последующую нужно на основе ее условного закона распределения при условии, что все предыдущие приняли те значения, которые дал розыгрыш (более подробно останавливаться на этом случае мы не будем).
Таким образом, мы рассмотрели все четыре варианта единичного жребия и убедились, что все они сводятся к розыгрышу (одно- или многократному) случайного числа R от 0 до 1.
Возникает вопрос: а как же разыгрывается это число R? Существует целый ряд разновидностей так называемых «датчиков случайных чисел», решающих эту задачу. Остановимся вкратце на некоторых из них.
Самый простой из датчиков случайных чисел — это вращающийся барабан, в котором перемешиваются перенумерованные шарики (или жетоны). Пусть, например, нам надо разыграть случайное число R от 0 до 1 с точностью до 0,001. Заложим в барабан 1000 перенумерованных шариков, приведем его во вращение и после остановки выберем первый попавшийся шарик, прочтем его номер и разделим на 1000.
Можно поступить и немного иначе: вместо 1000 шариков заложить в барабан только 10, с цифрами 0, 1,2,..., 9. Вынув один шарик, прочтем первый десятичный знак дроби. Вернем его обратно, снова покрутим барабан и возьмем второй шарик — это будет второй десятичный знак и т. д. Легко доказать (мы этого делать не будем), что полученная таким образом десятичная дробь будет иметь равномерное распределение от 0 до 1. Преимущество этого способа в том, что он никак не связан с числом знаков, с которым мы хотим знать R.
Отсюда один шаг до рационализаторского предложения: не разыгрывать число R каждый раз, когда это понадобится, а сделать это заранее, т. е. составить достаточно обширную таблицу, в которой все цифры 0, 1, 2, .... 9 встречаются случайным образом и с одинаковой вероятностью (частотой). До этого приема люди давно додумались: такие таблицы действительно составлены и применяются на практике. Они называются таблицами случайных чисел. Выдержки из таблиц случайных чисел приводятся во многих руководствах по теории вероятностей и математической статистике (например, [201]). Краткие выдержки из таблиц случайных чисел приведены и в популярной книжке автора [21], где, кстати, даны и примеры моделирования случайных процессов с помощью таблиц случайных чисел.
При ручном применении метода Монте-Карло таблицы случайных чисел — наилучший способ розыгрыша случайного числа R от 0 до 1. Если же моделирование осуществляется не вручную, а на ЭВМ, то пользование таблицами случайных чисел (как и вообще таблицами) нерационально — они слишком загрузили бы память. Для розыгрыша R на ЭВМ применяются специальные датчик и, которыми оснащены многие вычислительные машины. Это могут быть как «физические датчики», основанные на преобразовании случайных шумов, так и вычислительные алгоритмы, по которым сама машина вычисляет так называемые «псевдослучайные числа». Приставка «псевдо» означает «как бы», «якобы». И в самом деле, числа, вычисляемые с помощью таких алгоритмов, фактически случайными не являются, но практически ведут себя как случайные; все значения от 0 до 1 встречаются в среднем одинаково часто и, кроме того, связь между последовательными значениями получаемых чисел практически отсутствует. Существует ряд алгоритмов вычисления псевдослучайных чисел, различающихся между собой по простоте, равномерности и другим признакам (см. [22]). Один из самых простых алгоритмов вычисления псевдослучайных чисел состоит в следующем. Берут два произвольных n-значных двоичных числа а1 и a2, перемножают их и в полученном произведении берут п средних знаков; это будет число a3. Затем перемножают a1 и а2, в произведении снова берут п средних знаков и т. д. Полученные таким образом числа рассматривают как последовательность двоичных дробей с п знаками после запятой. Такая последовательность дробей ведет себя практически как ряд значения случайного числа R от 0 до 1. Существуют и другие алгоритмы, основанные' не на перемножении, а на «суммировании со сдвигом». Подробнее останавливаться на конкретных алгоритмах получения псевдослучайных чисел не имеет смысла: в настоящее время практически все ЭВМ снабжены либо датчиками случайных чисел, либо проверенными алгоритмами вычисления псевдослучайных1).
Дата добавления: 2014-12-03; просмотров: 1249;