ТЕХНИКА СТОХАСТИЧЕСКОГО МОДЕЛИРОВАНИЯ
Понятие «случайный» - одно из самых фундаментальных как в математике, так и в повседневной жизни. Моделирование случайных процессов - мощнейшее направление в современном математическом моделировании.
Событие называется случайным, если оно достоверно непредсказуемо. Случайность окружает наш мир и чаще всего играет отрицательную роль в нашей жизни. Однако есть обстоятельства, в которых случайность может оказаться полезной.
В сложных вычислениях, когда искомый результат зависит от результатов многих факторов, моделей и измерений, можно сократить объем вычислений за счет случайных значений значащих цифр. Из теории эволюции следует, что случайность проявляет себя как конструктивный, позитивный фактор. В частности, естественный отбор реализует как бы метод проб и ошибок, отбирая в процессе развития особи с наиболее целесообразными свойствами организма. Далее случайность проявляется в множественности ее результатов, обеспечивая гибкость реакции популяции на изменения внешней среды.
В силу сказанного имеет смысл положить случайность в основу методов получения решения посредством проб и ошибок, путем случайного поиска.
Отметим, что выше, приведя пример имитационного моделирования - игру «Жизнь», мы уже имели по сути дела стохастическую модель. Теперь обсудим методологию такого моделирования более детально.
Итак, пусть в функционале модели значения некоторых входных параметров определены лишь в вероятностном смысле. В этом случае значительно меняется сам стиль работы с моделью.
При серьезном рассмотрении в обиходе появляются слова «распределение вероятностей», «достоверность», «статистическая выборка», «случайный процесс» и т.д.
При компьютерном математическом моделировании случайных процессов нельзя обойтись без наборов, так называемых, случайных чисел, удовлетворяющих заданному закону распределения. На самом деле эти числа генерирует компьютер по определенному алгоритму, т.е. они не являются вполне случайными хотя бы потому, что при повторном запуске программы с теми же параметрами последовательность повторится; такие числа называют «псевдослучайными».
Рассмотрим вначале генерацию чисел равновероятно распределенных на некотором отрезке. Большинство программ - генераторов случайных чисел - выдают последовательность, в которой предыдущее число используется для нахождения последующего. Первое из них - начальное значение. Все генераторы случайных чисел дают последовательности, повторяющиеся после некоторого количества членов, называемого периодом, что связано с конечной длиной машинного слова. Самый простой и наиболее распространенный метод - метод вычетов, или линейный конгруэнтный метод, в котором очередное случайное число xn определяется«отображением»
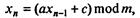 (1)
(1)
где a, с, m - натуральные числа, mod - так называемая, функция деления по модулю (остаток от деления одного числа на другое по модулю). Наибольший возможный период датчика (1) равен т; однако, он зависит от а и с. Ясно, что чем больше период, тем лучше; однако реально наибольшее m ограничено разрядной сеткой ЭВМ. В любом случае используемая в конкретной задаче выборка случайных чисел должна быть короче периода, иначе задача будет решена неверно. Заметим, что обычно генераторы выдают отношение 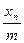 , которое всегда меньше 1, т.е. генерируют последовательность псевдослучайных чисел на отрезке [0,1].
, которое всегда меньше 1, т.е. генерируют последовательность псевдослучайных чисел на отрезке [0,1].
Вопрос о случайности конечной последовательности чисел гораздо сложнее, чем выглядит на первый взгляд. Существует несколько статистических критериев случайности, но все они не дают исчерпывающего ответа. Так, последовательно генерируемые псевдослучайные числа могут появляться не идеально равномерно, а проявлять тенденцию к образованию групп (т е. коррелировать) Один из тестов на равномерность состоит в делении отрезка [0, 1] на М равных частей - «корзин», и помещения каждого нового случайного числа в соответствующую «корзину». В итоге получается гистограмма, в которой высота каждого столбика пропорциональна количеству попавших в «корзину» случайных чисел (рис. 7.54).
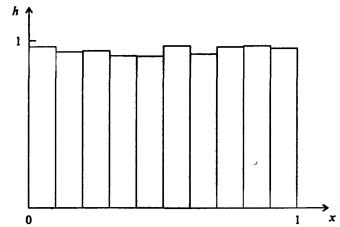
Рис. 7.54. Вид гистограммы для равномерно распределенных на отрезке [0,1] чисел при достаточно большой выборке
Понятно, что при большом числе испытаний высоты столбиков должны быть почти одинаковыми. Однако, этот критерий является необходимым, но не достаточным; например, он «не замечает» даже очень короткой периодичности. Для не слишком требовательного пользователя обычно достаточны возможности датчика (генератора) случайных чисел, встроенного в большинство языков программирования. Так, в PASCAL есть функция random, значения которой - случайные числа из диапазона [0, 1). Ее использованию обычно предшествует использование процедуры randomize, служащей для начальной «настройки» датчика, т.е. получения при каждом из обращений к датчику разных последовательностей случайных чисел. В BASICe есть функция rnd(), значения которой – случайные числа из диапазона (0,1). Для начальной «настройки» датчика, т.е. получения при каждом из обращений к генератору случайных чисел разных последовательностей, первый раз функцию rnd() используют с аргументом (-time). Или используют оператор randomize(timer) для инициализации генератора случайных чисел. Для задач, решение которых требует очень длинных некоррелированных последовательностей, вопрос осложняется и требует нестандартных решений Равномерно распределенные случайные числа - простейший случай. Располагая датчиком случайных чисел, генерирующим числа r Î (0, 1), легко получить числа из произвольного интервала [а, b].
X = a + (b - a)∙r.
Более сложные распределения часто строятся с помощью распределения равномерного. Упомянем здесь лишь один достаточно универсальный метод Неймана (часто называемый также методом отбора-отказа), в основе которого лежит простое геометрическое соображение. Допустим, что необходимо генерировать случайные числа с некоторой нормированной функцией распределения f(x) на интервале (а, b). Введем положительно определенную функцию сравнения w(x) такую, что w(x) = const и w(x) > f(x) на [а, b] (обычно w(x) равно максимальному значению f(x) на [а, b]). Поскольку площадь под кривой f(x) равна для интервала [х, х + dx]вероятности попадания х в этот интервал, можно следовать процедуре проб и ошибок. Генерируем два случайных числа, определяющих равновероятные координаты в прямоугольнике
A BCD с помощью датчика равномерно распределенных случайных чисел:
x = a + (b - a)∙r, y = w∙r
и если точка М(х, у) не попадает под кривую f(x), мы ее отбрасываем, а если попадает - оставляем (рис. 7.55). При этом множество координат х оставленных точек оказывается распределенным в соответствии с плотностью вероятности f(x).
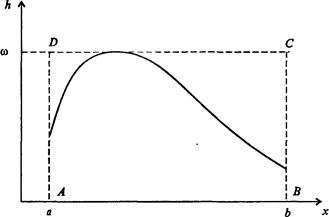
Рис. 7.55. Метод отбора-отказа. Функция w(x) = fmax
Этот метод для ряда распределений не самый эффективный, но он универсален, прост и понятен. Эффективен он тогда, когда функция сравнения w(x) близка к f(х). Заметим, что никто не заставляет нас брать w(x)= const на всем промежутке [а, b]. Если f(x) имеет быстро спадающие «крылья», то разумнее взять w(x) в виде ступенчатой функции.
Дата добавления: 2014-12-20; просмотров: 1608;