Измерение количества информации
И ее кодирование
Изфизики известно, что за единицу измерения любой физической величины принимается ее количество, равное эталонной мере. Длину измеряют отрезком длины в 1 м, массу тела измеряют единицей массы в 1 кг и т. д.
Аналогично измеряют и информацию. Наиболее известны объемный и энтропийный* способы измерения информации. Информация – величина случайная. Количество информации зависит от вероятности события, о котором идет речь в сообщении. Пусть, например, по радио 4 августа сообщают в прогнозе погоды следующее: "Завтра осадков в виде снега не ожидается ". Количество информации в этом сообщении практически равно нулю, так как вероятность снега 5 августа практически равна нулю. Если же вместо снега сообщали бы о дожде, то такое сообщение несло бы определенное количество информации, так как вероятность дождя может быть достаточно большой.
Наиболее распространен объемный способ. Объемное понятие количества информации было введено в 1928 году американским инженером Р. Хартли. Он предложил определять количество информации как логарифм числа возможных сообщений N с одинаковым числом символов n из определенного алфавита с количеством символов m:
I = loga N = loga mn = n ·loga m
Выбор основания логарифма может быть любым и скажется только на единицах измерения количества информации. При а =10 количество информации измеряется в десятичных единицах, при а=2, как принято в технических средствах информационных систем, количество информации измеряется в двоичных единицах. Формула Хартли дает I=1 при а=2, m=2 и n=1, то есть информацией в 1 двоичную единицу будет обладать сообщение, составленное из одного символа двоичного алфавита. Это элементарная информация, передаваемая сообщением об одном из двух равновероятных исходов события. Такая информация называется двоичной,илибит(от binary digit). Если на какой-то вопрос в равной мере вероятны ответы “да” и “нет”, то, услышав, например, положительный ответ “да”, мы получаем информацию в один бит.
Измерение информации в двоичных единицах особенно удобно для технических приложений, так как в системах, хранящих и преобразующих информацию, проще всего оперировать с величинами, выраженными в двоичной системе счисления, а одна двоичная единица информации есть как раз то количество ее, которое необходимо для указания одной двоичной цифры. Этот же принцип используется в нервной системе человека и животных (два состояния нервной клетки – возбуждение и торможение, то есть релейная система передачи нервного импульса “замкнуто/разомкнуто”). Кроме того, одна двоичная единица информации есть количество информации, необходимое для задания одного значения булевой функции,что удобно для математико-логического анализа вопросов переработки информации. Функции Буля изучает алгебра логики, которая кратко будет рассмотрена дальше. Основной единицей измерять физические величины не всегда удобно, поэтому вводятся производные единицы от основной, например, для измерения длины – 1 мм, 1 см, 1 км и т.д. Точно так же и для измерения информации 1 бит – слишком маленькая единица измерения, поэтому введены более крупные единицы, но кратные не 10, как мы привыкли, а кратные двум: 1байт= 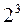 =8 бит, 1Килобайт (Кб)=
=8 бит, 1Килобайт (Кб)= 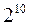 =1024 байта, 1Мегабайт (Мб)=
=1024 байта, 1Мегабайт (Мб)= 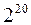 = 1024 Кбайт, 1Гигабайт (Гб)=
= 1024 Кбайт, 1Гигабайт (Гб)= 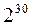 =1024 Мбайт и т.д. В этих единицах измеряется объем оперативной и внешней памяти компьютеров, размеры компьютерных документов – файлов и количество передаваемой информации по каналам связи.
=1024 Мбайт и т.д. В этих единицах измеряется объем оперативной и внешней памяти компьютеров, размеры компьютерных документов – файлов и количество передаваемой информации по каналам связи.
Для представления в компьютерах и передачи по каналам связи любая информация кодируется, то есть преобразуется в специальную систему символов – код. Кодами являются числа. Поставим в соответствие символам русского алфавита цифры: АÞ0, БÞ1, ВÞ2, ГÞ3, ДÞ4 и т.д. Распознавание техническим устройством даже десяти цифр – задача довольно сложная. Поэтому для упрощения задачи распознавания такой системой символов являются две двоичные цифры 0 и 1, то есть любая информация в компьютере представляется в виде двоичных чисел. Устройствам компьютера распознавать нужно только две цифры, соответствующие состояниям электронного переключателя.
В общем случае код можно рассматривать двояко. Во-первых, код (от слова “кодекс"-code) является правилом, описывающим отображение одного набора знаков в другой набор знаков (или слов). Во-вторых, код – это набор знаков, который выступает в качестве множества образов при кодировании. Другими словами, некоторое множество слов одного алфавита можно называть кодом, если оно поставлено во взаимно однозначное соответствие с множеством слов другого алфавита.
По ходу заметим, что если каждый образ при кодировании является отдельным знаком, то такое отображение называют шифровкой, а образы –шифрами.Например, вместо слова ИНФОРМАТИКА можно получить его шифр – МРЧСУПГХМНГ, записывая взамен каждой буквы этого слова следующую за ней в алфавите третью букву.
Код называется различимым, если существует взаимно однозначное соответствие между множествами всех последовательностей слов данного кода и всех последовательностей слов первоначального алфавита, то есть последовательностей элементов сообщений. Каждое слово, входящее в код, называется кодовой комбинацией, например совокупность двоичных цифр, образующих двоичное число, которое соответствует какому-либо символу русского алфавита или знаку. Одну двоичную цифру (0 или 1), входящую в кодовую комбинацию, называют элементом кода. Число элементов кода в кодовой комбинации называется ее длиной и определяет значность кода: 5-значный, 7-значный и т.д. Кодовые комбинации для разных символов одного и того же алфавита могут быть различной длины. Такой код будет неравномерным. В качестве примера приведем код Морзе:
А ·- Б -··· В ·-- Г --· Д -·· Е ·
Ж ···- З --·· И ·· Й ·--- К -·- Л ·-··
М -- Н -· О --- П ·--· Р ·-· С ···
Т - У ··- Ф ··-· Х ···· Ц -·-· Ч ---·
Ш ---- Щ --·- Ь,Ъ-··- Ы -·-- Э ··-·· Ю ··--
Я ·-·- 1 ·---- 2 ··--- 3 ···-- 4 ····- 5 ·····
6 -···· 7 --··· 8 ---·· 9 ----· 0 -----
В коде Морзе для обозначения букв, цифр, знаков препинания и различных служебных сигналов используются комбинации точек и тире. Кодовому знаку “точка” соответствует сигнал, состоящий из посылки (импульса) тока и паузы одинаковой длительности, а кодовому знаку “тире” соответствует сигнал из посылки тока тройной длительности и паузы. Кодовые комбинации отделяются друг от друга специальным разделительным знаком, представляющим собой двойную паузу. Как видно, код Морзе неравномерный. Здесь применен принцип частоты использования букв в английском алфавите (чем чаще используется буква, тем короче ее код).
Чтобы уменьшить значность кода для передачи большого числа символов, их делают многопрограммными. Примером может служить международный телеграфный код Бодо – равномерный пятизначный двоичный код. Число различных кодовых комбинаций в коде Бодо, следовательно, равно 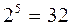 , что недостаточно для передачи всех букв, цифр, знаков препинания и т.д. Поэтому код Бодо является двухпрограммным. Одна из программ (буквенный регистр) объединяет все буквы за исключением ъ,э,й,щ, а другая–оставшиеся буквы, цифры, знаки препинания и т. д. (цифровой регистр). При передаче данных выбор регистра принимаемым аппаратом осуществляется автоматически по кодовой комбинации, передаваемой перед сообщением. В коде Бодо кодовая комбинация 11110 соответствует первой программе, а кодовая комбинация 11101 – второй программе.
, что недостаточно для передачи всех букв, цифр, знаков препинания и т.д. Поэтому код Бодо является двухпрограммным. Одна из программ (буквенный регистр) объединяет все буквы за исключением ъ,э,й,щ, а другая–оставшиеся буквы, цифры, знаки препинания и т. д. (цифровой регистр). При передаче данных выбор регистра принимаемым аппаратом осуществляется автоматически по кодовой комбинации, передаваемой перед сообщением. В коде Бодо кодовая комбинация 11110 соответствует первой программе, а кодовая комбинация 11101 – второй программе.
При кодировании и передаче информации по каналам связи очень существенное значение имеет помехозащищенность и помехоустойчивостькода, так как в каналах связи всегда имеются помехи, которые могут искажать передаваемые коды. Если в кодовой комбинации пропадет одна единица или появится лишняя, то сообщение искажается, так как вместо одного символа появляется другой. С целью повышения помехоустойчивости код усложняют: к информационным знакам добавляют дополнительные знаки - проверочные. Для этого выбирают из общего возможного числа кодовых комбинаций лишь те, которые отличаются друг от друга не менее чем двумя элементами. В этом случае искажение сигнала в одном элементе легко обнаруживается, вследствие чего наступает защитный отказ. Например, из всех 16 кодовых комбинаций, состоящих из 4 элементов, выделим для кодирования только те, которые содержат по две единицы: 0011, 0101, 0110, 1001, 1010, 1100. Здесь искажение любого кода в одном элементе приводит к образованию недопустимой кодовой комбинации, что ведет к наступлению защитного отказа.
Приведем другой пример: система пятиэлементных кодовых комбинаций, отличающихся друг от друга не менее чем тремя элементами. Полезную информацию несут второй и третий элемент справа. В этом случае появляется возможность автоматически обнаруживать и корректировать искаженный в одном элементе код и реализовать его как правильный.
1) 01001 Пусть принята недопустимая кодовая комбинация 01011.
2) 11010 Сравнивая ее с приведенными, видим, что она отличается от
3) 10101 первой комбинации одним элементом, от второй – двумя,
4) 00110 от третьей – четырьмя и от четвертой – тремя элементами.
Какой же код был передан? Скорее всего, первый, так как искажение в одном элементе наиболее вероятно. Вероятность искажения других комбинаций значительно меньше – они отличаются в двух и больше элементах. Специальные схемы это определят и скорректируют код под первую комбинацию.
Принципиально возможно применение кодов, обеспечивающих исправление нескольких ошибок, но такие коды практической ценности не представляют, так как повышение помехоустойчивости ведет к избыточному увеличению элементов кода и, как следствие, к увеличению времени передачи информации, усложнению аппаратуры и снижению ее надежности.
Избыточность широко применяется и в обиходе для повышения надежности и достоверности передаваемых сообщений. Например, текст телеграммы составлен так: "Вылетаю 3 марта, вторник, рейсом 523 восемь тридцать пять утра". Этот текст содержит избыточную информацию: получившему телеграмму и так известно, что 3 марта – вторник и что самолет рейсом 523 вылетает в 8 час. 35 минут утра. Однако при возникновении ошибки телеграфа при передаче телеграммы дополнительные сведения позволят получить нужную информацию.
По такому принципу строятся коды обнаружения и исправления ошибки, например, код Хэмминга. Корректирующие коды строятся так, что появление или потеря единицы вследствие помех в любой кодовой комбинации приводит к появлению недопустимой в данном коде комбинации, которая сразу же обнаруживается или исправляется.
Рассмотрим кодирование информации в компьютерах. В компьютере любая информация не может быть физически записана по-другому, кроме как в двоичной системе счисления в виде двоичного кода (двоичных чисел).
Кодирование текстового сообщенияпроизводится заменой каждого символа соответствующим числом – двоичным кодом. Количество символов, кодируемых n разрядами двоичного числа, равно 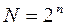 . Если взять восемь двоичных разрядов (один байт), то с их помощью можно закодировать
. Если взять восемь двоичных разрядов (один байт), то с их помощью можно закодировать 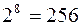 различных символов. Этого вполне достаточно, чтобы закодировать 66 прописных и строчных букв русского алфавита (кириллицы), 52 прописные и строчные буквы латинского алфавита, 10 арабских цифр, 9 знаков препинания, знаки арифметических операций и т.д.
различных символов. Этого вполне достаточно, чтобы закодировать 66 прописных и строчных букв русского алфавита (кириллицы), 52 прописные и строчные буквы латинского алфавита, 10 арабских цифр, 9 знаков препинания, знаки арифметических операций и т.д.
Таким образом, каждый знак в компьютере кодируется одним байтом – равномерным восьмизначным кодом, что очень удобно для записи в память, так как стандартом, введенным фирмой IBM, вся память представляется в виде восьмибитовых ячеек. Кроме перечисленных выше знаков, из 256 двоичных комбинаций выделяют коды для кодирования знаков псевдографики и специальных управляющих знаков. Примеры: ╬=11001110, Ж=10000110, 7=00110111, № =11111100. Подчеркнем, что десятичные цифры, как и любые символы, представляются не их значениями в двоичной системе счисления, а двоичными кодами (сравните: значение семи равно 111, а код семи равен 00110111). Закодируем, например, слово “студент”: 11100001 11100010 11000111 01001001 01001011 01011011 11100010 или в шестнадцатеричной записи: E1E2E3A4A5ADE2h.
Так оно будет записано в памяти компьютера, так запишется на диске, так будет передаваться по каналам связи.
Возникает вопрос: почему, например, буква А кодируется комбинацией из 0 и 1 в виде 10000000, а не какой-то другой? Очевидно, что разработчики вычислительной техники договорились о том, как кодировать символы. Иначе было бы “вавилонское столпотворение” и информацией между различными компьютерами обмениваться было бы нельзя. Так было на первых ЭВМ, каждый тип из которых имел свою кодировку, так случилось и в конце 80-х годов прошлого века, когда появившиеся советские персональные компьютеры типа “Искра 1030”, "Нейрон", ЕС-1840 . . . ЕС-1849, Поиск-2 и другие имели одну (ГОСТ) кодировку, а IBM-совместимые – другую. Пользователям пришлось разрабатывать специальные программы перекодировки информации и предварительно использовать их при переходе на другой тип компьютера. Иначе информация, перенесенная с PC IBM на “Искру 1030”, на экране последней представлялась в виде “пляшущих человечков” Шерлока Холмса.
Еще и сейчас в мире существует множество 8-битовых кодов (КОИ-8, МIC, ДКОИ-8 и др.). Это создает, естественно, дополнительные трудности в работе из-за необходимости разработки специальных программ перекодировки информации при переходе с одного типа компьютера на другой.
В 1961 году в США разработали “Универсальный стандартный код обмена информацией” – ASCII (American Standard Code for Information Interchange). Этот код сейчас и принят за стандарт для всех персональных компьютеров. Таблица этого кода хранится в памяти каждого компьютера. Таблица состоит из двух частей.
Общая часть: содержит от 0 до 31 – управляющие коды, от 32 до 127 – стандартные коды десятичных цифр, прописных и строчных латинских букв, специальных символов (клавиш) и т.д. Управляющие коды первоначально были разработаны в виде команд, сообщающих печатающему устройству, как форматировать печатную страницу и как распознавать конец файла. К таким командам относились, например, команды "конец строки" в печатаемом тексте или "перевод каретки" печатающего устройства в начало следующей строки.
Теперь их назначение распространено на все устройства вывода, особенно на сетевые. Например, код 17 используется для возобновления передачи данных между двумя компьютерами при асинхронной передаче после прекращения передачи. Код 19 используется для временного прекращения передачи данных, при полном заполнении приемного буфера – генерируется принимающим компьютером. Код 21 – контрольный код, посылаемый компьютером, принимающим данные по сети (отсутствие подтверждения приема пакета, например, при сбое передачи) – требует повторить передачу данного пакета.
Большинство знаков с этими кодами можно переслать на экран, однако их действие может быть различно и зависит от используемого языка программирования. Знаки с шестнадцатеричными кодами 00 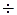 06 и 0Е 1В всегда могут быть пересланы на экран с заранее предсказуемым результатом, чего нельзя сказать об остальных управляющих кодах. Для примера приведем несколько кодов: 07 – звуковой сигнал (при выдаче из машины этого кода подается звуковой сигнал); 0А – перевод строки и 0D – возврат каретки пишущей машинки (возврат печатающей головки принтера); 0C – очистка экрана; 04 –конец передачи по каналу связи и т.д.
06 и 0Е 1В всегда могут быть пересланы на экран с заранее предсказуемым результатом, чего нельзя сказать об остальных управляющих кодах. Для примера приведем несколько кодов: 07 – звуковой сигнал (при выдаче из машины этого кода подается звуковой сигнал); 0А – перевод строки и 0D – возврат каретки пишущей машинки (возврат печатающей головки принтера); 0C – очистка экрана; 04 –конец передачи по каналу связи и т.д.
Фактически общая часть представляет собой стандартный семизначный равномерный код, дополняемый нулем в старшем (восьмом) разряде.
Дополнительная часть: это коды от 128 до 255. Сюда входят символы для рисования рамок таблиц (псевдографика), буквы русского алфавита, специальные символы, такие, например, как FD – солнышко; F7 F9 – стрелки вверх, вниз, вправо и влево; FA – знак и т.д. Следует подчеркнуть, что большие и малые буквы как русского, так и латинского алфавитов имеют свои собственные коды, например Б - 81 и б - А1, L - 4C и l - 6C.
Дополнительная часть может изменяться в зависимости от типа операционной системы компьютера, страны использования и т.д. Фактически эта часть является расширением основного кода ASCII на основе международного стандарта ISO (International Standards Organization). Возможность замены дополнительной части кода ASCII делает компьютер пригодным для использования в любой стране мира, так как именно в этой части располагают, помимо кодов специальных символов, коды национальных алфавитов.
Пользователи IBM PC в разных странах вначале вынуждены были в MS-DOS дополнительную часть таблицы приспосабливать под особенности своей страны. Поэтому фирма Microsoft решила упорядочить этот процесс и обеспечить его стандартными средствами. Были введены средства, позволяющие загружать в знакогенератор компьютера кодировки символов для разных стран – кодовые страницы и переключаться между ними. Начиная с версии MS-DOS 6.22 такие средства были введены и для России.
Следует заметить, что коды символов русского алфавита (кириллицы) в дополнительной части таблицы для MS-DOS и Windows отличаются и зависят от используемой страницы. В MS-DOS используется 866 страница (символы кириллицы занимают коды 128¸175 и 224¸239), а в Windows – 1251 страница (символы кириллицы занимают коды 192¸255). Кодировка, используемая в Windows, называется ANSI-кодировкой. В Windows NT используется кодировка Unicode, в которой все символы кодируются шестнадцатизначными двоичными кодами, что позволяет закодировать 65536 символов. В большинстве шрифтов Windows NT заняты только 256 первых позиций кодировки Unicode, что позволяет вывести через Alt-набор символы кириллицы, переключившись на регистр кириллицы.Windows имеет встроенные средства, позволяющие ей преобразовывать символы из одной кодировки в другую, так что пользователь этого практически не замечает, работая с приложениями MS-DOS в среде Windows или переходя от одной версии Windows к другой.
Существует много программ, в которых встроена возможность просмотра на экране имеющейся в компьютере таблицы кодов. Для просмотра в MS-DOS можно использовать приведенную ниже простую программу на Бейсике. Если задать N=0, то будет напечатана основная часть таблицы, а при задании N=128 будет напечатана дополнительная часть таблицы. Таблица будет напечатана в 8 столбцов по 16 строк.
10 FOR I=0 TO 15 60 NEXT J
20 FOR J=0 TO 7 70 PRINT CHR$(13);
30 K=N+(J+I*8) 80 NEXT I
PRINT K; 90 END
50 PRINT “ “+CHR$ (K);
Ниже приведена дополнительная часть ASCII таблицы кодирования символов, распечатанная с помощью данной программы.
В Windows для просмотра символов и соответствующих им кодов можно воспользоваться программой Таблица символов из группы программ Стандартные. В нижнем углу окна таблицы при выделении символа появляется его код.
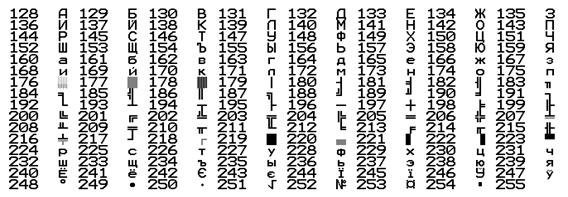
Для больших вычислительных систем существует другой международный стандарт: 8-битовый код EBCDIC (Extended Binary Coded Decimal Interchange Code) – расширенный двоично-кодированный десятичный код для обмена информацией.
Кодирование графической информации. Для кодирования графической информации в двоичные коды используется несколько способов.
 Кодирование изображения по точкам (растровый способ). На первом этапе вертикальными и горизонтальными линиями делят изображение на клетки одинакового размера. Чем меньше размер клетки (клетка превращается в точку) и чем их больше, тем точнее будет передано изображение и меньше потеря информации при кодировании. По ходу заметим, что при черно-белом изображении снимки в газете содержат 9 клеток в 1 мм
Кодирование изображения по точкам (растровый способ). На первом этапе вертикальными и горизонтальными линиями делят изображение на клетки одинакового размера. Чем меньше размер клетки (клетка превращается в точку) и чем их больше, тем точнее будет передано изображение и меньше потеря информации при кодировании. По ходу заметим, что при черно-белом изображении снимки в газете содержат 9 клеток в 1 мм  . Для наглядного представления рисунка 4 приведен увеличенный фрагмент изображения, взятый из окна графического редактора (каждая клеточка равна одному пикселю – наименьшей точке экрана), который в нормальном масштабе показан в верхнем левом углу.
. Для наглядного представления рисунка 4 приведен увеличенный фрагмент изображения, взятый из окна графического редактора (каждая клеточка равна одному пикселю – наименьшей точке экрана), который в нормальном масштабе показан в верхнем левом углу.
На втором этапе записывают в двоичном виде параметры каждой клетки: ее координаты по горизонтали и по вертикали, а также ее цвет. Эти описания каждой клетки и будут кодами графического изображения. Код изображения занимает очень большой объем памяти. Так, например, квадрат размером 10х10 точек, изображенный красной линией и залитый зеленым цветом, занимает ровно 1 Кб памяти.
Из физики известно, что любой цвет можно получить путем смешивания в различных пропорциях яркостей только трех цветов: красного (Red), зеленого (Green) и синего (Blue). В зависимости от используемой на компьютере видеосистемы яркость каждого из трех цветов разбивается на 16 256 градаций. Чем больше градаций яркости каждого цвета, тем качественнее изображение. При 256 градациях каждого из трех цветов можно получить примерно 16,78 млн различных оттенков цвета.
Пусть, например, мы имеем монитор с 16 градациями (4 двоичных разряда на градацию), тогда для указания цвета каждой клетки необходимо по 4´3=12 двоичных разрядов, а рисунок пусть содержит 250´200 клеток, тогда для последней клетки получим: 11111010_110010001011 1100 0011
Координаты клетки Признаки цвета R G B
(приведенные признаки цвета произвольны), то есть для каждой клетки требуется 28 двоичных разрядов. Кодирование всего изображения потребует 250*200*28=1400000 бит@1,335 Мб памяти.
Для задания 16,77 млн палитр цвета необходимо 24 двоичных разряда только для признака цвета клетки, поэтому графическая информация очень велика по объему. Это же изображение можно закодировать более экономично. Поскольку номера клеток идут по порядку, то при описании изображения можно координаты клеток не указывать, а задать лишь размеры изображения (количество клеток по вертикали и горизонтали) и адреса первой и последней клеток. Естественно, что существуют стандарты такой кодировки и различные алгоритмы, позволяющие уменьшить объем графической информации.
Тем не менее, обработка графической информации стала находить широкое применение только сейчас, когда память компьютеров стала исчисляться десятками и сотнями мегабайт, а дисковая – гигабайтами.
Таким образом, при растровом способе графическое изображение на экране однозначно отображается в памяти компьютера в виде определенной области с записанными двоичными кодами, описывающими каждую точку этого изображения. В памяти получается как бы слепок изображения. При линейном считывании памяти точки сканируются и с большой скоростью воспроизводятся на экране. Запись графической информации в память компьютера осуществляется автоматически, путем считывания с экрана координат и признаков цвета каждой точки изображения программой графического редактора, с помощью которого создается графическое изображение, или путем сканирования с листа специальным считывающим устройством – сканером. Растровый рисунок легко редактировать, он быстро воспроизводится на экране, но имеет и недостатки. Растровая графика хранится с фиксированным разрешением и определяется количеством и цветом пикселей. Растровый рисунок всегда привязан к конкретному устройству вывода информации. При изменении масштаба рисунка или выводе его на монитор, разрешение или цветовые возможности которого отличаются от параметров монитора, на котором рисунок создавался, возможны его искажения. Растровой графикой обычно пользуются для изображения очень мелких деталей или тонких оттенков в рисунке. Имеется множество растровых графических редакторов, например: Adobe Photoshop, Paint Shop Pro, Microsoft Image Composer, входящий в состав Microsoft FrontPage и др.
Следует отметить, что в недавно появившемся новом формате представления растровых рисунков DIB (device independent bitmap – аппаратно-независимый битовый массив) изображение растрового рисунка не зависит от аппаратуры. В этом формате совместно с изображением сохраняется информация об использованной цветовой палитре и разрешении исходного устройства.
Другим способом кодирования графической информации является векторный способ. В векторной графике рисунок составляется из векторных схем – простейших графических элементов: линий, овалов, прямоугольников, окружностей и т.д. Векторная графика включает совокупность команд рисования, которые описывают положение элемента, его размеры, форму, цвет и толщину линий, вид заполнения каждого простейшего графического элемента и т.д. Например, для кодирования треугольника задаются точки координат трех его вершин, толщина и цвет линий. При воспроизведении луч как бы идет за вершиной вектора и воспроизводит изображение. Таким образом, векторное изображение хранится в памяти машины в виде совокупности команд – программы, занимает значительно меньше места, но выводится медленнее, так как готового изображения в памяти нет, а оно формируется при выполнении команд, описывающих его. Такой рисунок при изменении масштаба или выводе на устройства с различной разрешающей способностью не искажается в силу того, что разрешение его не фиксировано и определяется только устройством вывода. К векторным графическим редакторам относятся: CorelDraw, Adobe Illustrator, Micrografx Designer and Micrografx Draw, редактор входящий в AutoCAD, Windows Enhanced Metafile и др.
В векторной графике создание рисунка очень похоже на рисование в текстовом редакторе Word.
На практике при создании графических изображений редакторы растровой, векторной и трехмерной графики часто комбинируют. Например, фотографии объектов обрабатываются и комбинируются в Adobe Photoshop, а на это накладываются надписи и иные рисунки, созданные с помощью Corel Draw, и виды трехмерных объектов, созданные в AutoDesk 3D Studio.
Кодирование графических изображений можно осуществлять и в виде описаний изображения в виде последовательности команд на языке программирования высокого уровня. Во всех языках имеются специальные операторы рисования графических примитивов таких, как прямая линия, овал или окружность, дуга и т.д. Нужно в операторах задать координаты начальной и конечной точек, толщину и направление линий, точки центров окружностей и другие параметры. Составляется программа рисования изображения, которая является кодом этого изображения. Приведем два примера кодирования изображений на языке программирования Турбо Бейсик.
Два вида эллипсов:Домик:
Дата добавления: 2018-11-25; просмотров: 700;