Knowledge-driven human-computer interaction
In human and computer interactions, there usually exists a semantic gap between human and computer's understandings towards mutual behaviors. Ontology (information science), as a formal representation of domain-specific knowledge, can be used to address this problem, through solving the semantic ambiguities between the two parties.[22]
Factors of change
Traditionally, as explained in a journal article discussing user modeling and user-adapted interaction, computer use was modeled as a human-computer dyad in which the two were connected by a narrow explicit communication channel, such as text-based terminals. Much work has been done to make the interaction between a computing system and a human. However, as stated in the introduction, there is much room for mishaps and failure. Because of this, human-computer interaction shifted focus beyond the interface (to respond to observations as articulated by D. Engelbart: "If ease of use was the only valid criterion, people would stick to tricycles and never try bicycles."[23]
The means by which humans interact with computers continues to evolve rapidly. Human–computer interaction is affected by the forces shaping the nature of future computing. These forces include:
· Decreasing hardware costs leading to larger memory and faster systems
· Miniaturization of hardware leading to portability
· Reduction in power requirements leading to portability
· New display technologies leading to the packaging of computational devices in new forms
· Specialized hardware leading to new functions
· Increased development of network communication and distributed computing
· Increasingly widespread use of computers, especially by people who are outside of the computing profession
· Increasing innovation in input techniques (e.g., voice, gesture, pen), combined with lowering cost, leading to rapid computerization by people formerly left out of the computer revolution.
· Wider social concerns leading to improved access to computers by currently disadvantaged groups
The future for HCI, based on current promising research, is expected[24] to include the following characteristics:
· Ubiquitous computing and communication. Computers are expected to communicate through high speed local networks, nationally over wide-area networks, and portably via infrared, ultrasonic, cellular, and other technologies. Data and computational services will be portably accessible from many if not most locations to which a user travels.
· High-functionality systems. Systems can have large numbers of functions associated with them. There are so many systems that most users, technical or non-technical, do not have time to learn them in the traditional way (e.g., through thick manuals).
· Mass availability of computer graphics. Computer graphics capabilities such as image processing, graphics transformations, rendering, and interactive animation are becoming widespread as inexpensive chips become available for inclusion in general workstations and mobile devices.
· Mixed media. Commercial systems can handle images, voice, sounds, video, text, formatted data. These are exchangeable over communication links among users. The separate fields of consumer electronics (e.g., stereo sets, VCRs, televisions) and computers are merging partly. Computer and print fields are expected to cross-assimilate.
· High-bandwidth interaction. The rate at which humans and machines interact is expected to increase substantially due to the changes in speed, computer graphics, new media, and new input/output devices. This can lead to some qualitatively different interfaces, such as virtual reality or computational video.
· Large and thin displays. New display technologies are finally maturing, enabling very large displays and displays that are thin, lightweight, and low in power use. This is having large effects on portability and will likely enable developing paper-like, pen-based computer interaction systems very different in feel from desktop workstations of the present.
· Information utilities. Public information utilities (such as home banking and shopping) and specialized industry services (e.g., weather for pilots) are expected to proliferate. The rate of proliferation can accelerate with the introduction of high-bandwidth interaction and the improvement in quality of interfaces.
Scientific conferences
One of the main conferences for new research in human-computer interaction is the annually held Association for Computing Machinery's (ACM) Conference on Human Factors in Computing Systems, usually referred to by its short name CHI (pronounced kai, or khai). CHI is organized by ACM Special Interest Group on Computer–Human Interaction (SIGCHI). CHI is a large conference, with thousands of attendants, and is quite broad in scope. It is attended by academics, practitioners and industry people, with company sponsors such as Google, Microsoft, and PayPal.
There are also dozens of other smaller, regional or specialized HCI-related conferences held around the world each year, including:[25]
· ASSETS: ACM International Conference on Computers and Accessibility
· CSCW: ACM conference on Computer Supported Cooperative Work
· CC: Aarhus decennial conference on Critical Computing
· DIS: ACM conference on Designing Interactive Systems
· ECSCW: European Conference on Computer-Supported Cooperative Work
· GROUP: ACM conference on supporting group work
· HRI: ACM/IEEE International Conference on Human–robot interaction
· ICMI: International Conference on Multimodal Interfaces
· ITS: ACM conference on Interactive Tabletops and Surfaces
· MobileHCI: International Conference on Human–Computer Interaction with Mobile Devices and Services
· NIME: International Conference on New Interfaces for Musical Expression
· OzCHI: Australian Conference on Human-Computer Interaction
· TEI: International Conference on Tangible, Embedded and Embodied Interaction
· Ubicomp: International Conference on Ubiquitous computing
· UIST: ACM Symposium on User Interface Software and Technology
· i-USEr: International Conference on User Science and Engineering
· INTERACT: IFIP TC13 Conference on Human-Computer Interaction
See also
· Outline of human–computer interaction
· Information design
· Experience design
· Information architecture
· Physiological interaction
· User experience design
· Mindfulness and technology
Footnotes
Lecture №. 5.
Subject: Database systems
What is a database?
A database is a tool for collecting and organizing information. Databases can store information about people, products, orders, or anything else. Many databases start as a list in a word-processing program or spreadsheet. As the list grows bigger, redundancies and inconsistencies begin to appear in the data. The data becomes hard to understand in list form, and there are limited ways of searching or pulling subsets of data out for review. Once these problems start to appear, it's a good idea to transfer the data to a database created by a database management system (DBMS), such as Access.
A computerized database is a container of objects. One database can contain more than one table. For example, an inventory tracking system that uses three tables is not three databases, but one database that contains three tables. Unless it has been specifically designed to use data or code from another source, an Access database stores its tables in a single file, along with other objects, such as forms, reports, macros, and modules. Databases created in the Access 2007 format (which is also used by Access, 2016, Access 2013 and Access 2010) have the file extension .accdb, and databases created in earlier Access formats have the file extension .mdb. You can use Access 2016, Access 2013, Access 2010, or Access 2007 to create files in earlier file formats (for example, Access 2000 and Access 2002-2003).
Using Access, you can:
· Add new data to a database, such as a new item in an inventory
· Edit existing data in the database, such as changing the current location of an item
· Delete information, perhaps if an item is sold or discarded
· Organize and view the data in different ways
· Share the data with others via reports, e-mail messages, an intranet , or the Internet
Top of the Document
The parts of an Access database
The following sections are short descriptions of the parts of a typical Access database.
Tables
Forms
Reports
Queries
Macros
Modules
Tables
 A database table is similar in appearance to a spreadsheet, in that data is stored in rows and columns. As a result, it is usually quite easy to import a spreadsheet into a database table. The main difference between storing your data in a spreadsheet and storing it in a database is in how the data is organized.
A database table is similar in appearance to a spreadsheet, in that data is stored in rows and columns. As a result, it is usually quite easy to import a spreadsheet into a database table. The main difference between storing your data in a spreadsheet and storing it in a database is in how the data is organized.
To get the most flexibility out of a database, the data needs to be organized into tables so that redundancies don't occur. For example, if you're storing information about employees, each employee should only need to be entered once in a table that is set up just to hold employee data. Data about products will be stored in its own table, and data about branch offices will be stored in another table. This process is called normalization.
Each row in a table is referred to as a record. Records are where the individual pieces of information are stored. Each record consists of one or more fields. Fields correspond to the columns in the table. For example, you might have a table named "Employees" where each record (row) contains information about a different employee, and each field (column) contains a different type of information, such as first name, last name, address, and so on. Fields must be designated as a certain data type, whether it's text, date or time, number, or some other type.
Another way to describe records and fields is to visualize a library's old-style card catalog. Each card in the cabinet corresponds to a record in the database. Each piece of information on an individual card (author, title, and so on) corresponds to a field in the database.
For more information about tables, see the article Introduction to tables.
Forms
 Forms allow you to create a user interface in which you can enter and edit your data. Forms often contain command buttons and other controls that perform various tasks. You can create a database without using forms by simply editing your data in the table datasheets. However, most database users prefer to use forms for viewing, entering, and editing data in the tables.
Forms allow you to create a user interface in which you can enter and edit your data. Forms often contain command buttons and other controls that perform various tasks. You can create a database without using forms by simply editing your data in the table datasheets. However, most database users prefer to use forms for viewing, entering, and editing data in the tables.
You can program command buttons to determine which data appears on the form, open other forms or reports, or perform a variety of other tasks. For example, you might have a form named "Customer Form" in which you work with customer data. The customer form might have a button which opens an order form where you can enter a new order for that customer.
Forms also allow you to control how other users interact with the data in the database. For example, you can create a form that shows only certain fields and allows only certain operations to be performed. This helps protect data and to ensure that the data is entered properly.
For more information about forms, see the article Introduction to forms.
Reports
 Reports are what you use to format, summarize and present data. A report usually answers a specific question, such as "How much money did we receive from each customer this year?" or "What cities are our customers located in?" Each report can be formatted to present the information in the most readable way possible.
Reports are what you use to format, summarize and present data. A report usually answers a specific question, such as "How much money did we receive from each customer this year?" or "What cities are our customers located in?" Each report can be formatted to present the information in the most readable way possible.
A report can be run at any time, and will always reflect the current data in the database. Reports are generally formatted to be printed out, but they can also be viewed on the screen, exported to another program, or sent as an attachment to an e-mail message.
For more information about reports, see the article Introduction to reports.
Queries
 Queries can perform many different functions in a database. Their most common function is to retrieve specific data from the tables. The data you want to see is usually spread across several tables, and queries allow you to view it in a single datasheet. Also, since you usually don't want to see all the records at once, queries let you add criteria to "filter" the data down to just the records you want.
Queries can perform many different functions in a database. Their most common function is to retrieve specific data from the tables. The data you want to see is usually spread across several tables, and queries allow you to view it in a single datasheet. Also, since you usually don't want to see all the records at once, queries let you add criteria to "filter" the data down to just the records you want.
Certain queries are "updateable," meaning you can edit the data in the underlying tables via the query datasheet. If you are working in an updateable query, remember that your changes are actually being made in the tables, not just in the query datasheet.
Queries come in two basic varieties: select queries and action queries. A select query simply retrieves the data and makes it available for use. You can view the results of the query on the screen, print it out, or copy it to the clipboard. Or, you can use the output of the query as the record source for a form or report.
An action query, as the name implies, performs a task with the data. Action queries can be used to create new tables, add data to existing tables, update data, or delete data.
For more information about queries, see the article Introduction to queries.
Macros
 Macros in Access can be thought of as a simplified programming language which you can use to add functionality to your database. For example, you can attach a macro to a command button on a form so that the macro runs whenever the button is clicked. Macros contain actions that perform tasks, such as opening a report, running a query, or closing the database. Most database operations that you do manually can be automated by using macros, so they can be great time-saving devices.
Macros in Access can be thought of as a simplified programming language which you can use to add functionality to your database. For example, you can attach a macro to a command button on a form so that the macro runs whenever the button is clicked. Macros contain actions that perform tasks, such as opening a report, running a query, or closing the database. Most database operations that you do manually can be automated by using macros, so they can be great time-saving devices.
For more information about macros, see the article Introduction to Access programming.
Modules
 Modules, like macros, are objects you can use to add functionality to your database. Whereas you create macros in Access by choosing from a list of macro actions, you write modules in the Visual Basic for Applications (VBA) programming language. A module is a collection of declarations, statements, and procedures that are stored together as a unit. A module can be either a class module or a standard module. Class modules are attached to forms or reports, and usually contain procedures that are specific to the form or report they're attached to. Standard modules contain general procedures that aren't associated with any other object. Standard modules are listed under Modules in the Navigation Pane, whereas class modules are not.
Modules, like macros, are objects you can use to add functionality to your database. Whereas you create macros in Access by choosing from a list of macro actions, you write modules in the Visual Basic for Applications (VBA) programming language. A module is a collection of declarations, statements, and procedures that are stored together as a unit. A module can be either a class module or a standard module. Class modules are attached to forms or reports, and usually contain procedures that are specific to the form or report they're attached to. Standard modules contain general procedures that aren't associated with any other object. Standard modules are listed under Modules in the Navigation Pane, whereas class modules are not.
For more information about modules, see the article Introduction to Access programming.
Lecture № 6.
Subject: Data analysis. Data management.Spreadsheet Microsoft Excel
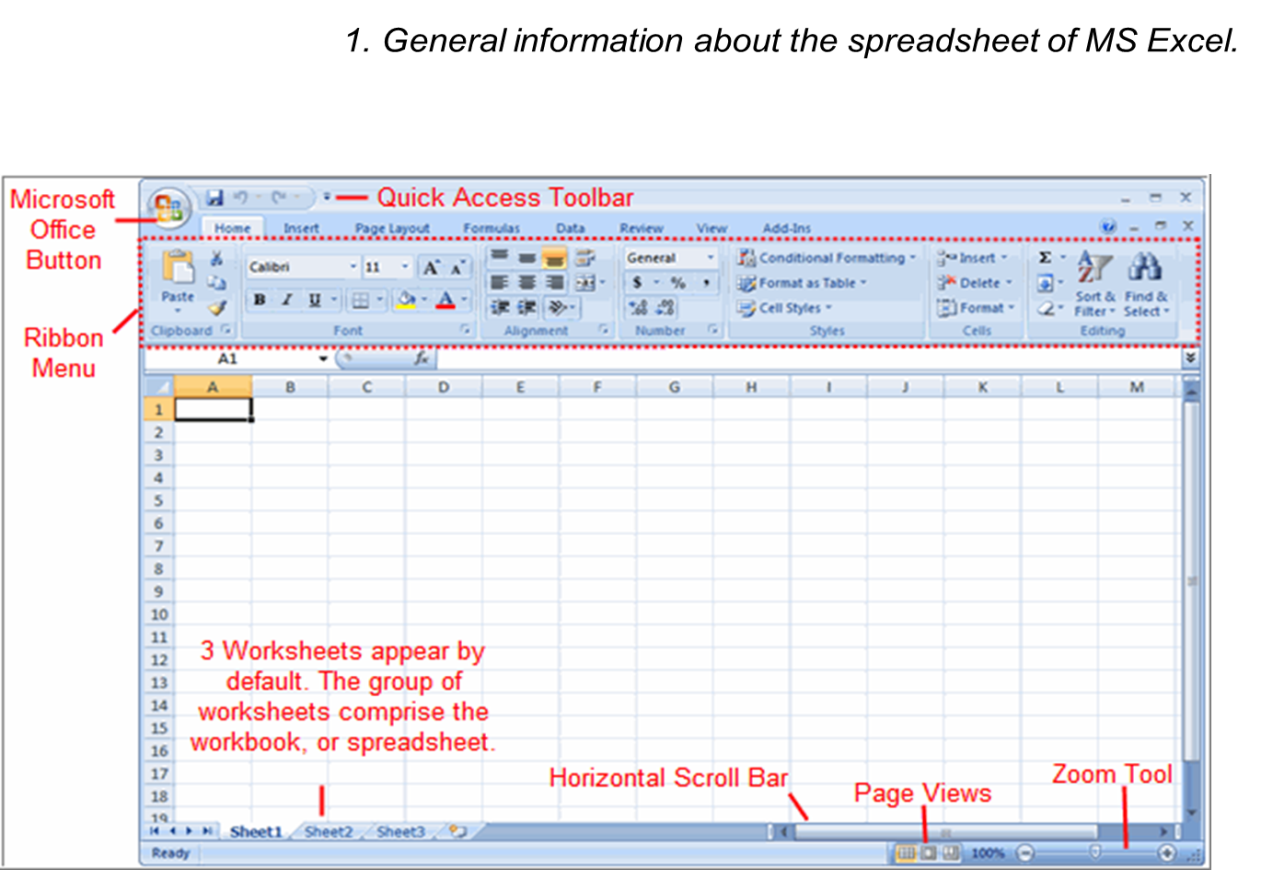
1. General information about the spreadsheet of MS Excel.
2. Entering data into the worksheet. Working with rows and columns.
3. Entering formulas. Using relative and absolute cell addresses. Using the Insert Function.
4. Construction of charts
In History…
Daniel Bricklin and Bob Frankston created the first spreadsheet application, VisiCalc (for "visible calculator"). Lotus 1-2-3 came next, followed by Microsoft Excel.

Spreadsheet – is…
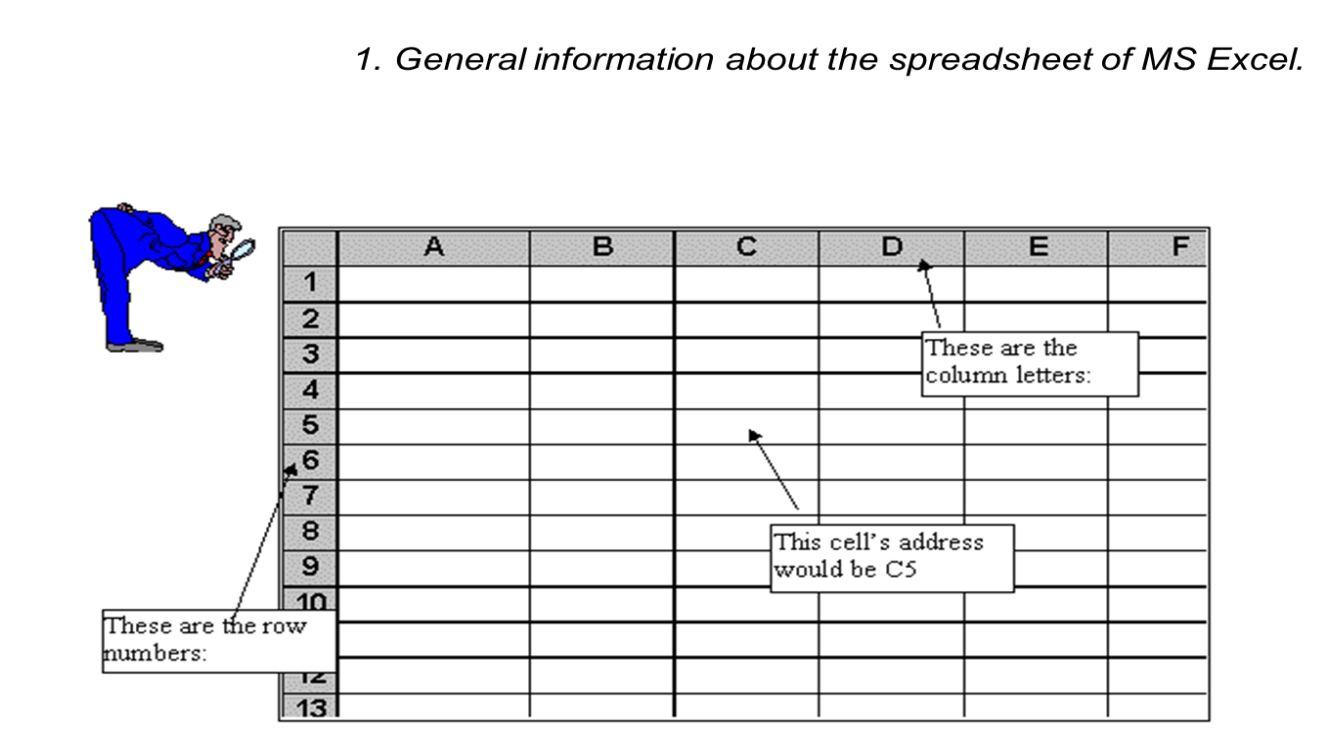
…a table of values arranged in rows and columns.
… a document, that stores data in a grid of horizontal rows and vertical columns. Rows are typically labeled using numbers (1, 2, 3, etc.), while columns are labeled with letters (A, B, C, etc). Individual row/column locations, such as C3 or B12, are referred to as cells
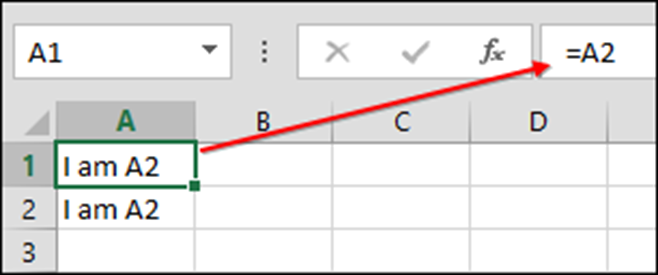
What is a Cell Reference?
A “cell reference” means the cell to which another cell refers. For example, if in cell A1 you have =A2. Then A1 refers to A2.
Дата добавления: 2018-11-25; просмотров: 1144;