Распределения, связанные с нормальным
- Распределение
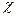 -квадрат (хи - квадрат)
-квадрат (хи - квадрат)
Опр.: Пусть случайные величины 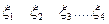 распределённые как N(0, 1).
распределённые как N(0, 1).
Говорят, что случайной величине 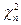 , определённая как:
, определённая как:
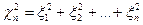 имеет распределение
имеет распределение
хи – квадрат с n степенями свободными.
Ясно, что (для 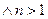 ) с вероятностью 1 принимает положительные значения. Функция плотности в точке x(x>0) равна :
) с вероятностью 1 принимает положительные значения. Функция плотности в точке x(x>0) равна :
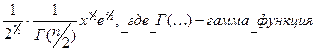
Свойство:
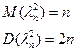
График:
 y
y
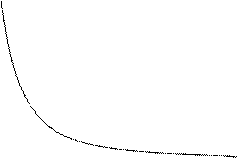 n=1
n=1
 0,6
0,6
n=2
0,4
 |
 n=3
n=3
0,2
n=8
X
1 2 5 10 15
Применение: Критерии согласия
Критерии согласия используются для проверки того, удовлетворяет ли рассматриваемая случайная величина данному закону распределения.
Критерий согласия Пирсона ( 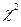 -критерий) служит для проверки гипотезы но о том, что
-критерий) служит для проверки гипотезы но о том, что 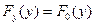
где 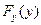 - истинное распределение случайной величины y.
- истинное распределение случайной величины y.
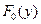 - гипотетическое распределение.
- гипотетическое распределение.
Статистическая гипотеза – это утверждение относительно значений одного или более параметров распределений некоторой величины или о самой форме распределения. Обычно выбирают две исходные гипотезы: основную - 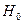 , и альтернативную ей
, и альтернативную ей 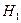 .
.
Статистическая проверка гипотезы – это процедура выяснения, следует ли принять основную гипотезу или отвергнуть её. Если в результате проверки гипотеза ошибочна отвергается (в то время как она верна), то имеет место ошибке 1-го ряда (характеризующая более тяжелыми последствиями); если гипотеза принимается при истинности - ошибке 2-го ряда. Вероятности ошибок I и II ряда ( 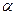 и
и 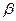 ) зависят от критерия, на основании которого будет выбираться одна из гипотез. Очевидно, что вероятности этих 2-х ошибок взаимосвязаны, то есть чем больше значение , тем меньше , и наоборот.
) зависят от критерия, на основании которого будет выбираться одна из гипотез. Очевидно, что вероятности этих 2-х ошибок взаимосвязаны, то есть чем больше значение , тем меньше , и наоборот.
Обычное решение этой дилеммы состоит в том, что выбирают некоторое фиксированное значение (как правило, 0.05, 0.1, 0.001) и надеются что будет также мало. Значение - наз -уровнем значимости.
Для выбранного значения определяется так называемая критическая область , удовлетворяющая значению 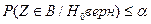
Где Z-контрольная величина (критерий), представляющая собой некоторую функцию от выборки (результатов эксперимента).
Проверки гипотезы состоит в следующем. Производится выборка (эксперимент), на основании чего вычисляется Z-частное значение критерия Z. Если 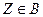 , то от гипотезы отказывается. Если Z не принадлежит B, то говорят, что полученные наблюдения не противоречат принятой гипотезе. Разумеется, прежде чем выдвинется
, то от гипотезы отказывается. Если Z не принадлежит B, то говорят, что полученные наблюдения не противоречат принятой гипотезе. Разумеется, прежде чем выдвинется
Гипотезу относительно значений параметров распределения, необходимо определить вид самого закона распределения. Наиболее распространённый на практике и достаточно эффективный метод подбора закона распределения, основан на графическом представлении экспериментальных данных. Оси отображаются в виде гистограммы относительных частот:
- Вычисляется величина класса гистограммы: d=
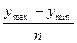
- Определяется число попаданий значений y в i -й интервал
- Вычисляется относительная частота попаданий наблюдаемой переменной в каждый класс:
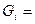
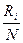 , где
, где 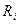 -число попаданий в i -й интервал. N-объём выборки.
-число попаданий в i -й интервал. N-объём выборки. - На каждом i-м интервале строится прямоугольник со сторонами
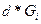 .Сумма
.Сумма 
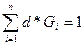 .
.
При использовании 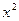 -критерии поступают следующим образом: Вычисляется контрольная величина :
-критерии поступают следующим образом: Вычисляется контрольная величина : 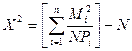 , где
, где 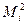 -число значений
-число значений 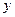 ,попавших в
,попавших в 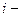 й класс.
й класс.

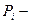 теоретическая вероятность для
теоретическая вероятность для 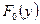 попадание значения в й класс.
попадание значения в й класс.
Затем по таблице 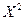 -распределений исходит критическое значение
-распределений исходит критическое значение 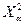 для уровня значимости и
для уровня значимости и 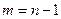 степеней свободы.
степеней свободы.
Основной вывод :
Если 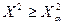 ,то гипотеза отвергается.
,то гипотеза отвергается. 
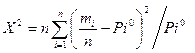
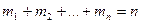
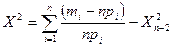
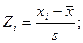
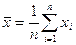
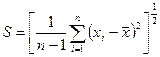
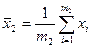
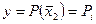
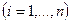
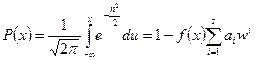
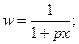
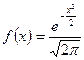
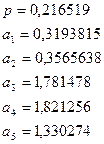
 равномерно распределёнными
равномерно распределёнными 
 -распределение Релея.
-распределение Релея.
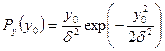
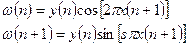 Нормальное распределение M=0 D=
Нормальное распределение M=0 D= 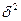
или

Лекция 3
Проверка статистических гипотез.
Основной задачей имитационного моделирования систем является подбор законов
распределения на основе статистических данных, полученных в результате эксперимента. В
основе процедуры отыскания закона распределения некоторой величины по экспериментальным данным лежит проверка статистических гипотез.
Опр. Статистическая гипотеза – утверждение относительно значений одного или боле параметров распределение некоторой величины или о самой форме распределения.
Обычно выбирают две исходные гипотезы:
основную - H 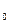 и
и
альтернативную ей – H 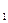
Опр. Статистическая проверка гипотезы – процедура выяснения, следует ли принять основную гипотезу H или отвергнуть ее.
Если в результате проверки гипотеза H ошибочно отвергается, то имеет место ошибка 1-го рода ( характеризующаяся более тяжелыми последствиями ); ели гипотеза H принимается при истинности H - совершается ошибка 2-го рода.
Вероятности ошибок 1 и 2 рода ( и 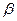 ) зависят от критерия, на основании которого будет выбираться одна из гипотез. Очевидно, что вероятности этих двух ошибок взаимосвязаны, то есть чем больше значение , тем меньше , и наоборот.
) зависят от критерия, на основании которого будет выбираться одна из гипотез. Очевидно, что вероятности этих двух ошибок взаимосвязаны, то есть чем больше значение , тем меньше , и наоборот.
Обычное решение этой дилеммы состоит в том, что выбирают некоторое фиксированное значение ( как правило, небольшое – 0.05, 0.1, 0.001 – т.к. это вероятность отвергнуть H , в то время как она, на самом деле, верна ) и надеются, что будет так же мало. Фиксированное значение называется уровнем значимости.
Для выбранного значения определяется так называемая критическая область В, удовлетворяющая условию:
P( Z 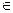 B| H верна )
B| H верна ) 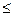 ,
,
Где Z - контрольная величина ( критерий ), представляющее собой некоторую функцию от выборки ( результатов эксперимента ). Проверка гипотезы сводится к следующему. Производится выборка ( эксперимент ), на основании чего вычисляется Z - частное значение критерия Z . Если Z B, то от гипотезы H отказываются. Если Z 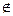 B то говорят, что полученные наблюдения ( экспериментальные данные ) не противоречат принятой гипотезе.
B то говорят, что полученные наблюдения ( экспериментальные данные ) не противоречат принятой гипотезе.
Разумеется, прежде чем выдвигать гипотезу относительно значений параметров распределения, необходимо определить вид самого закона распределения. Наиболее распространенный на практике и достаточно эффективный метод подбора закона распределения основан на графическом представлении экспериментальных данных в виде гистограммы.
Методика построения гистограммы.
- Вычисляется величина интервала гистограммы:
d = , где (y 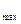 - y
- y  ) – диапазон изменений наблюдаемой переменной,
) – диапазон изменений наблюдаемой переменной,
n-число интервалов
2. Определяется число показаний значений y в i -й интервал.
- Вычисляется относительная частота попаданий наблюдаемой переменной в каждый интервал:
G 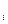 = ,где R
= ,где R 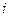 - число попаданий в i-й интервал
- число попаданий в i-й интервал
N - число наблюдений (объем выборки).
4. На каждом i-м интервале строится прямоугольник со сторонами d*G . Сумма площадей прямоугольников 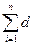 *G = 1.Для наиболее часто используемых статистических гипотез разработаны критерии, позволяющие проводить их проверку с наибольшей достоверностью:
*G = 1.Для наиболее часто используемых статистических гипотез разработаны критерии, позволяющие проводить их проверку с наибольшей достоверностью:
t - критерий ( Стьюдента ).
Этот критерий используется для проверки гипотезы о равенстве средних значений 2–х нормально распределенных случайных величин X и Y в предложении, что дисперсии их равны, хотя и неизвестны. Сравниваемые выборки могут иметь равный объем.
В качестве критерия используют величину Т:
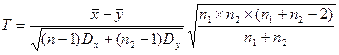 |
Величина Т подчиняется распределению Стьюдента. Критическое значение для t –критерия определяется по таблице для выбранного значения 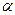 и числа степеней свободы
и числа степеней свободы 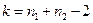 . Если вычисленное по указанной формуле значение Т удовлетворяет неравенству
. Если вычисленное по указанной формуле значение Т удовлетворяет неравенству 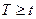 - критерию, то гипотезу отвергают.
- критерию, то гипотезу отвергают.
По отношению к предложению о «нормальности распределения» величин x и y t-критерий не очень чувствителен. Его можно применять, если распределение одномодальны и не слишком асимметричны.
F-критерий (Фишера)
Этот критерий служит для проверки гипотезы о равенстве дисперсий 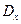 и
и  при условии, что x и y распределены нормально.
при условии, что x и y распределены нормально.
(Гипотезы такого рода имеют большое практическое значение, т.к. дисперсия есть мера таких характеристик, как погрешности измерительных приборов, точность технологических процессов и т.д.) В качестве контрольной величины используется отношение дисперсий 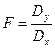 (или
(или 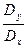 - большая дисперсия должна быть в числителе). Величина F подчиняется F-распределению (Фишера) с (
- большая дисперсия должна быть в числителе). Величина F подчиняется F-распределению (Фишера) с ( 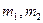 ) степенями свободы, где
) степенями свободы, где 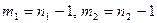 . Проверка гипотезы состоит в следующем.
. Проверка гипотезы состоит в следующем.
Для величины 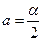 и величины
и величины  по таблице F – распределения выбирают значения
по таблице F – распределения выбирают значения 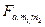 . Если f, вычисленное по выборке, больше этого критического значения (
. Если f, вычисленное по выборке, больше этого критического значения (  ), то гипотеза о равенстве дисперсий должна быть отклонена с вероятностью ошибки .
), то гипотеза о равенстве дисперсий должна быть отклонена с вероятностью ошибки .
Критерий согласия.
Критерии согласия используются для проверки того, удовлетворяет ли рассматриваемая случайная величина данному закону распределения. Критерий согласия 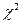 (хи – квадрат - Пирсона) служит для проверки гипотезы о том, что
(хи – квадрат - Пирсона) служит для проверки гипотезы о том, что 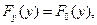 где
где 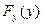 - истинное распределение случайной величины y, - гипотетическое распределение.
- истинное распределение случайной величины y, - гипотетическое распределение.
Проверка производится следующем образом.
1. Область значений случайной величины y разбивается (произвольно) на к непересекающихся множеств («классов»).
2. В результате n опытов формируется выборка 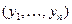 .
.
3. Вычисляется контрольная величина .
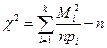 , где
, где
- число значений y, попавших в i-й класс.
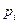 - теоретическая вероятность для попадания значения y, в i-й класс (гистограммы).
- теоретическая вероятность для попадания значения y, в i-й класс (гистограммы).
4. По таблице - распределений находят критическое значение 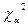 для уровня значимости и
для уровня значимости и 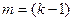 степеней свободы.
степеней свободы.
Если 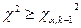 , то гипотеза о - функции распределения отвергается.
, то гипотеза о - функции распределения отвергается.
Критерий Колмогора-Смирнова.
Имеющееся выборка упорядочивается по возрастанию и строится эмпирическая функция распределения:
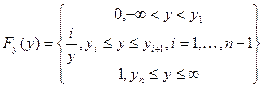 .
.
Контрольной величиной является следующая:
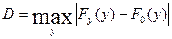
Гипотеза 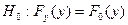 отвергается, если вероятность попадания соответствующего критерия в критическую область оказывается меньше выбранного уровня значимости .
отвергается, если вероятность попадания соответствующего критерия в критическую область оказывается меньше выбранного уровня значимости .
Критическое значение критерия, как и в предыдущих случаях, находят по таблицам.
Модуль2
Dim q(1 To 15) As Single
Dim a As String
Dim b(1 To 15, 1 To 15) As String
Dim n1(1 To 15, 1 To 15) As Single
Sub Test_Tau ()
Dim i1 As Integer
Dim j1 As Integer
' j1 10 'размерность
' i1 15 'количество точек размерности j1
Call LP_tau_15_Dim
for j1= 1 To 10
For i1 = 1 To 15
Call TauCoord(i1,j1)
'For ns= 1 To j1
'For j2 = 1 To ns
‘Worksheets(1) .Cells(i1 +15+ (ns-1), j2).Formula = q(ns)
'Next j2
'Next ns
'Call Prin_List(j1)
Next i1
Next j1
End Sub
Sub LP_tau_15__Dim()
a= "00001000010000100001000010000100001000010000100001"+ _
"0000100001000010000100001" + _
"00001000030000500015000170005100085002550025700771"+ _
"0128503855043690310721845" + _
"00001000010000700011000130006100067000790046500721"+_ "0082304091041250414128723" +_
“00001000030000700005000070004300049001470043901013”+_
“0072700987058890691516647”+_
"00001000010000500003000150005100125001410017700759”+_ "0026701839069291624116565”+_
"00001000030000100001000090005900025000890032100835"+ _
"0083304033039131164318777"+ _
"00001000010000300007000310004700109001730018100949”+_
“0047102515062110214703169”+_
"00001000030000300009000090005700043000430022500113”+_
"0160100579017310119707241”+_
"00001000030000700013000030003500089000090023500929”+ _
''0134103863013470441705087"+_
"00001000010000500011000270005300069000250010300615"+_
“0091300977061971465102507”+_
For k = 1 To 10
Fоr j = 1 To 15
b(k, j) = Mid(a, 75 * (k - 1) + 5 (j - 1) + 1, 5)
n1(k,j)= Val(b(k, j))
Next j
Next k
End Sub
Sub TauCoord (i, n)
'i- номep точки, n-размерность
aa = i
m = 1 + int(Log(aa) / 0.693147)
For j = 1 To n
s = 0
for k = 1 To m
n2 = 0
For 1 = k To m
Bb= n1(j. 1)
‘m=MsgBox(bb,3,”bb=”)
n2=n2+int(2*fnd(aa/2*1))*int(2*fnd(bb/2^(1+1-k)))
Next f
‘m=MsgBox(m2,3,”m2=”)
s=s+fnd(0.5*n2)/(2^(k-1))
Next k
q(j)=s
Next j
‘jk1=MsgBox(i,3,”номер точки=”)
‘jk1=MsgBox(n,3,”размерность=”)
for l1 = 1 To n
for j2 = 1 To l1
‘Worksheets(1) .Cells(i, j2).Formula = q(j2)
Next j2
‘Next ns
‘jk1=MsgBox(l1,3,”порядковый номер координаты l1=”)
‘jk1=MsgBox(q(l1),3,”координата q=”)
Next l1
End Sub
Function fnd(x)
zn=x-Int(x)
fnd=zn
‘n=MsgBox(zn,3,”zn=”)
End Function
Sub Prin_List (j1)
For kt= 1 To 10
For ns = 1 To j1
For j2 = 1 To ns
Worksheets(1) .Cells(kt +10* (ns-1), j2).Formula = q(ns)
Next j2
Next ns
Next kt
End Sub
Sub optimization()
Dim q As Integer
Dim n As Integer
Dim m As Integer
20 MsgBox (“КОМПЛЕСНЫЙ МЕТОД”)
40 Rem ФУНКЦИЯ Z-F (X1,X2,…,XN)ВЫЧЕСЛЯЕТСЯ В СТРОКЕ 5000
60 Rem Вычисление значений G1,G2,…,GN И ПРОВЕРКА
65 Rem ОГРАНИЧЕНИЙ ПРОИЗВОДИТСЯ В СТРОКЕ 6000
80 q InputBox (“ВВЕДИТЕ КОЛИЧЕСТВО ПЕРЕМЕННЫХ”):n=Cint(q): Worksheets.Cells(3,4), Formula=n
100 q InputBox (“ВВЕДИТЕ КОЛИЧЕСТВО ПЕРЕМЕННЫХ”):n=Cint(q): Worksheets.Cells(2,4), Formula=m
120 ReDim X(n), Y(n), L(n), U(n), XC(n), XO(n), XR(n), XH(n)
160 K=2*n:PP=0
180 ReDim C(1 To K, 1 To n), F(K), G(m), IC(m), EC(2*n)
200 For J=1 To n: q=InputBox(“ВВЕДИТЕ НАЧАЛЬНЫЕ ЗНАЧЕНИЯ”): X(J)=CSng(q):C(1,J)=X(J):XC(J)=X(J):Next
240 Rem ПРОЧИТАТЬ ЗНАЧЕНИЯ НИЖНИХ И ВЕРХНИХ ГРАНИЦ
260 For J=1 To n: L(J)= Worksheets(1).Cells(n,3): U(J)= Worksheets(1).Cells(n,4): Next
280 Rem ВКЛЮЧИТЬ ГЕНЕРАТОР СЛУЧАЙНЫХ ЧИСЕЛ
290 q InputBox(“ВВЕДИТЕ Х”) :X1=CSng(q)
500 I=1
520 GoSub 5000
540 F(1)=Z
600 I=I+1
620 For J=1 To n: C(LJ)=L(J)+1(U(J)-L(J)):X(J)=C(LJ):Next
640 IM=1: GoSub 6000
660 IfIC1= 1 To GoTo 720
670 Rem ОБНОВИТЬ ЗНАЧЕНИЯ “ЦЕНТРА ТЯЖЕСТИ”
680 For J=1 To n: XC(J)=((I-1)*XC(J)+C(I,J))/I:Next
700 GoTo 760
720 For J=1 To n: C(I,J)=(C(I,J)+XC(J))/2:X(J)=C(I,J):Next J
740 GoTo 640
760 GoSub 5000: F(I)=Z
780 If I< K Then GoTo 600
790 Rem УПОРЯДОЧИТЬ ЗНАЧЕНИЯ ФУНКЦИИ И ТОЧКИ
795 Rem В КОТОРЫХ ОНА ВЫЧЕСЛЕНА
800 For J=1 To K-1
820 For I=1 No K
840 If F(J)<=F(J) Then GoTo 900
860 F1=F(I):F(J)=F(I):F(I)=F1
880 For L1=1 To n: Y(L1)=C(J,L1):C(I,L1)=C(I,L1): C(I,L1)=Y(L1):Next L1
900 Next I: Next J
910 Rem ЗАПОМНИТЬ НАИМЕНЬШЕЕ ЗНАЧЕНИЕ ФУНКЦИИ
920 FM=F(1)
1000 MsgBox(“Первая точка”)
1020 MsgBox(F(1)“МИНИМАЛЬНОЕ ЗНАЧЕНИЕ”)
1040 MsgBox(“МИНИМАЛЬНАЯ ТОЧКА”)
1060 For L1=1 To n: Worksheets(1.Cells(6.L1).Formula: C(1,L1):Next L1
1100 Rem ЗАДАТЬ КОЭФФИЦИЕНТ ОТРАЖЕНИЯ
1120 A=1.3
1190 Rem ОПРЕДЕЛИТЬ “ЦЕНТР ТЯЖЕСТИ” НАИЛУЧШИХ (К-1) ТОЧЕК
1195 Rem И ЗАПОМНИТЬ НАИХУДШУЮ ТОЧКУ
1200 For LI - 1 To n: XH(L1) = C(K,L1): XO(Ll) = (K* XC(L1) - XH(L1)) / (K - I): Next LI
1390 Rem Получить отраженную точку
1400 For L1=1 To n: XR(L1) = (1 +A) * XO(L1) - A * XH(L1): X(L1) = XR(L1): Next L1
1490 Rem ПРОВЕРИТЬ, ДОПУСТИМА ЛИ НОВАЯ ТОЧКА
1500 IM=0
1520 GoSub 6000
1540 If EC1 = 0 And IC1 = 0 Then GoTo 2000
1550 Rem ЕСЛИ ТОЧКА ЯВЛЯЕТСЯ ДОПУСТИМОЙ, ТО ПЕРЕЙТИ К СТРОКЕ 2000
1555 Rem ПОМЕСТИТЬ ТОЧКУ ВНУТРЬ ГРАНИЦ
1600 If EC1=0 Then GoTo 1800
1610 Rem ЕСЛИ ЯВНЫЕ ОГРАНИЧЕНИЯ НАРУШЕНЫ, ТО
1615 Rem ПОМЕСТИТЬ ТОЧКУ ВНУТРЬ ГРАНИЦ
1620 For J = 1 To n
1640 If EC(J) = 1 Then XR(J) = L(J) + 0.00001: X(J) = XR(J)
1660 If EC(J+n) = 1 Then XR(J) = U(J) - 0.00001: X(J) = XR(J)
1680 Next J
1800 If IC1 = 0 Then GoTo 2000
1810 Rem ЕСЛИ НЕЯВНЫЕ ОГРАНИЧЕНИЯ НАРУШЕНЫ, ТО
1815 Rem ТО ПЕРЕМЕСТИТЬСЯ НА ПОЛОВИНУ РАССТОЯНИЯ К “ЦЕНТРУ ТЯЖЕСТИ”
1820 For L1 = 1 To n: XR(L1)=(XR(L1)+X0(Ll))/2: X(L1) = XP(L1): NextL1
1840 GoTo 1490
2010 Rem ЕСЛИ НОВОЕ ЗНАЧЕНИЕ - НАИХУДШЕЕ,
2015 Rem ТО ПЕРЕМЕСТИТЪСЯ НA ПОЛОВИНУ РАССТОЯНИЯ К ТОЧКЕ ХО
2018 Rem И ВЫЧИСЛИТЬ НОВОЕ ЗНАЧЕНИЕ ФУНКЦИИ
2020 If FR< F(K) Then GoTo 2400
2040 For L1=1 To n: XR(L1) = (XR(L1) +XO(L1))/2: X(L1) - XR(L1): Next L1
2060 GoTo1490
2400 Rem ОБНОВИТЬ Х0 И ЗАМЕНИТЬ НАИХУДШУЮ ТОЧКУ НОВОЙ ТОЧКОЙ
2410 F(K) =FR '
2420 For L1 =1 To n
2440 XC(L.1) = К * XC(Ll) - C(K,L1)+ XR(L1)
2460 XC(L1)=XC(L1)/K:C(K,Ll)=XR(Ll)
2480 Next L1
2490 Rem УПОРЯДОЧИТЬ. ЗНАЧЕНИЯ ФУНКЦИИ И ТОЧКИ,
2493 Rem В КОТОРЫХ ОНА ВЫЧИСЛЕНА
2500 For J=1 To K-1
2520 For I=J + 1 To К
2540 If F(J)<=F(I) Then GoTo 2600
2560 F1=F(J):F(J)=F(I):F(I)=F1
2580 For L1=1 To n: Y(L1)= C(J, L1) :C(J,L1)=C(I, L1): C(I, L1) = Y(L1): Next L1
2600 Nex I: Next J
2610 Rem ЕСЛИ НАИМЕНЬШЕЕ ЗНАЧЕНИЕ ФУНКЦИИ УМЕНЬШЕНО,
2615 Rem ВЫСТАВИТЬ ПРИЗНАК ПЕЧАТИ'
2620 If F(1)<FM Then PP=1
2630 Rem ЕСЛИ УМЕНЬШЕНИЕ ФУНКЦИИ НЕ ОБНАРУЖЕНО,
2633 Rem ПРОВЕРКА КРИТЕРИЯ ЗАВЕРШЕНИЯ ПОИСКА МИНИМУМА НЕ ПРОИЗВОДИТСЯ
2640 If PP=0 Then GoTo 1190
2990 Rem НАЙТИ ОТКЛОНЕНИЕ ЗНАЧЕНИЙ ФУНКЦИИ
3000 S1 = 0: S2 =0
3020 For I=1 To K:S1=S1+F(I):S2=S2+F(I)*F(I): Next I
3040 SD= S2-S1*S1/K:SD=SD/K
3080 Rem НАЙТИ МАКСИМАЛЬНОЕ РАССТОЯНИЕ
3095 Rem ТОЧКАМИ КОМПЛЕКСА
3100 DM=0
3120 For I=1 To K-1: For J=I+1 To K
3140 D=0
3160 For L1=1 To n: D=D+C(I,L1)-C(J,L1)^2: Next L1
3180 D=Sqr(D)
3200 If D> DM Then DM=0
3220 Next J: Next I
3400 If PP=0 Then GoTo 3790
3500 MsgBox(“НОВАЯ ТОЧКА В СТРОКЕ 3500”)
3520 MsgBox(“МИНИМАЛЬНОЕ ЗНАЧЕНИЕ”=F1)
3540 MsgBox(“ТОЧКА МИНИМУМА”)
3560 For L1=1 To n: Worksheets(1).Cells(L1,9)=C(1,L1):Next L1
3600 FM=F(1):PP=0
3790 Rem ПРОВЕРКА СХОДИМОСТИ
3800 If SD>0.000001 And DM>0.0001 Then GoTo 1190
4000 MsgBox(“МИНИМУМ НАЙДЕН”)
4020 MsgBox(“ТОЧКА МИНИМУМА”)
4040 For L1=1 To n: Worksheets(1).Cells(L1,10)=C(1,L1):Next L1
4060 Worksheets(1).Cells(9,1)=F(1)
4100 End
5000 Z=-X(1)*X(2)*X(3)+3300
5050 fe=fe+1
5100 Return
6000 For ii= 1 To 2*n: EC(ii)=0:Next ii: EC1=0
6020 For ii= 1 Tom: IC(ii)=0:Next ii: IC1=0
6050 If IM= 1 Then GoTo 7100
6090 Rem ПРЕДЫДУЩАЯ СТРОКА ПРЕДНАЗНАЧЕНА ДЛЯ ПРОВЕРКИ НЕРАВЕНСТВА
6095 Rem GI(x)<=BI
6100 For ii= 1 No n
6120 If X(ii)<L(ii) Then EC(ii)=1: EC1=1
6140 If X(ii)>U(ii) Then EC(n+ii)=1: EC1=1
6160 Next ii
7100 G(1)=X(1)+3*X(2)+2*X(3)
7110 If G(1)=X(1)>72 Then IC(1)=1:IC=1
8000 Return
9000 ‘data 0,20,0,11,0,42
End Sub
Лекция 4
Дата добавления: 2018-06-28; просмотров: 648;