Алгоритмы кэширования современных микропроцессоров
Рассмотрим память, как 2х уровневую структуру (верхнюю и нижнюю). Например, кэш 1го уровня и кэш 2го уровня.
Если при выполнении программы фиксируется кэш промах, то соответствующая информация должна быть записана в память верхнего уровня, если при этом свободного места нет, то она должна заменить 1 из строк верхнего уровня. Если строка модифицирована, то ее необходимо переписать в память нижнего уровня. Эти операции передачи информации снижают быстродействие системы, поэтому их необходимо минимизировать. Количество пересылок зависит от того, какая строка замещается, т.к. она может понадобиться в дальнейшем.
Процесс выполнения программы можно представить, как последовательность обращения к строкам основной памяти. Вся информация хранится в основной памяти, а часть в кэш памяти. Выполнение программы можно описать процессом замещения строк. Для каждой программы можно найти хотя бы 1 последовательность замещения, которая дает минимум кэш промахов – это минимально-возможная последовательность замещения. Выбор замещаемой строки определяется в соответствии со специальными правилами, которые называются алгоритмом кэширования, при разработке которого стремятся достичь минимально возможной последовательности замещения.
Все алгоритмы делятся на 2 большие группы:
1 Физически не реализуемые (используют информацию о будущем обращении)
2 Физически реализуемые (используют историю процессора)
С помощью (1) можно оценить качество алгоритмов (2).
Физически не реализуемые
1 Алгоритм Михновского-Шора (сов. уч.): при каждом замещении удаляется строка, обращение к которой будет позже, чем к любой другой (реализуется минимально-возможная последовательность замещения) – МИН-алгоритм.
2 ОПТ (оптимальный) – известна вероятность обращения к строкам памяти. Замещается строка, вероятность обращения к которой не больше, чем к любой другой. Среднее число кэш промахов минимально.
Физически реализуемые
Алгоритмы выбора строки из кэш памяти.
1 Алгоритм случайного замещения (СЗ;Random)
2 Наиболее давно использованная (НДИ). Удаляется строка, к которой дольше всего не было обращения (LRU).
3 По времени первого появления (FIFO). Удаляется строка, появившаяся раньше всех.
4 LIFO (Last In First Out).
Существует группа алгоритмов, обладающих адаптивными свойствами.
1 Карабкающаяся строка
Все строки в КЭШе образуют некоторую последовательность, которая пронумерована. При каждом общении последовательность изменяется следующим образом.
St: j1, j2,…, jm–1, jm,…, jr
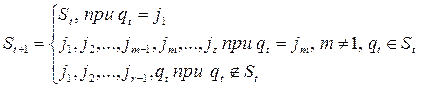
qt – номер строки основной памяти.
Строка, к которой обращаются меньше всего постепенно съезжает в конец и при промахе заменяется.
Это разновидность НДИ алгоритма.
2 Рабочий комплект (РК)
Строки в кэше, используемые в течение определенного промежутка времени, образуют определенный комплект. Из строк, не вошедших в рабочий комплект, формируются 2 очереди кандидатов замещения:
- модифицированные строки
- не модифицированные строки
Алгоритм: «Первый вышел из РК, первый удаляется из кэша». Предпочтение отдается 2ой очереди.
1.2 Зависимость по данным и переименование регистров при параллельной обработке
Возможность выполнения программы в измененной последовательности ограничивается 2мя ограничителями:
1. зависимость по управлению (ЗПУ) – наличие команд условных переходов;
2. зависимость по данным (ЗПД) – ограниченность ресурсов.
Переименование регистров (ЗПД)
Это архитектурная особенность, направленная на преодоление зависимости по данным.
Существует 4 зависимости:
1. RAR – чтение после чтения
2. RAW – чтение после записи
3. WAR – запись после чтения
4. WAW – запись после записи
Цель изучения зависимостей: распараллелить процессы, изменить последовательность команд для обеспечения более полной загрузки оборудования, повышение быстродействия.
Пример.
 |
Move r3, r7
Lw r8, (r3)
Add r3, r3, 4
Lw r9, (r3)
Некоторые зависимости являются несущественными, например, зависимость RAR.
Зависимости WAR и WAW могут быть устранены.
Существенной является только 1 зависимость – RAW.
Причины возникновения лишних зависимостей:
1. неоптимальный программный код;
2. ограниченность ресурсов.
В рамках существующей архитектуры х86 используется механизм динамического отображения логических ресурсов процессора на его физические ресурсы.
Логические ресурсы – те, которые определяют текст программы, физические – реально существующие в процессоре.
В этом случае с одним логическим ресурсом может быть связано несколько различных физических ресурсов. Каждое из этих значений соответствует значению логической величины в 1 из моментов времени выполнения программы.
Существует несколько подходов решения программы, представленной в примере.
Имеется логический файл (набор регистров) и физический файл. Физический больше логического и при необходимости переименования из файла берется свободный регистр и в него заносится значение из программы.
Move r0, r7
Lw r8, (r0)
Add r1, r0, 4
Lw r9, (r1)
1.3 Принципы конвейеризации. Синхронный и асинхронный конвейер.
Рассмотрим процедуру рабочего цикла и последовательность действий для основных команд. Можно выделить 5 этапов рабочего цикла.
В простейшем случае этапы выполняются последовательно. Во многих случаях последовательная процедура не обеспечивает требуемого быстродействия процессора. Лебедев предложил принцип совмещения этапов рабочего цикла. Он реализуется путем совмещения выборки команд из памяти и обработки в АЛУ.
Конвейер – набор устройств, соединенных цепочкой так, что результат выполнения операций с выхода первого блока поступает на вход следующего блока.
Существуют различные виды конвейеров.
Синхронный конвейер операций
Он работает в принудительном темпе и существует единое время выполнения каждого этапа (время такта).
Время такта = времени выполнения самой сложной операции.
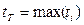 , где ti – время операции.
, где ti – время операции.
Продолжительность выполнения 2х смежный операции должна быть больше времени такта.
Этапы
 |
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5
1 2 3 4 5 6 7 8 9 10 такты
Рост производительности (теоретически) = количеству этапов (сколько этапов во столько раз возрастает)
Реальная производительность ниже. На это влияют 3 причины:
1. начальная загрузка и конечная выгрузка(пустые места в схеме)
2. разная длительность команд
3. наличие команд условного перехода (основная причина снижения производительности конвейерной обработки, с которой борются)
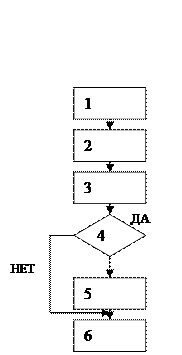 При выполнении условного перехода на 1 команду теряем 1 такт и т.д. При переходе на величину больше 5 команд получаем последовательную обработку.
При выполнении условного перехода на 1 команду теряем 1 такт и т.д. При переходе на величину больше 5 команд получаем последовательную обработку.
Если устройство управления при выборе направления ветвления ожидает формирование признака результата предыдущей команды, то также происходит простой (в примере, формирование признака результата-6й такт, анализ признака-5й такт).
В первых микропроцессорах конвейер при появлении команд условного перехода просто останавливался.
В современных микропроцессорах вычислительный процесс не останавливается, выполняется спекулятивный переход (попытка сделать переход (угадать) с выгодой для себя), т.е. предсказание ветвлений.
Асинхронный конвейер операций
Информация передается по готовности блоков (источник и приемник). Такой конвейер целесообразно применять, когда существует большая зависимость длительности отдельных этапов от типа команды.

I – выборка участка программы
II – распаковка
III – выборка операндов (tп – время паузы)
IV – операции в АЛУ
V – запись результата
Паузы возникают из-за неготовности блоков (источника или приемника).
Принципы конвейеризации
Первоначально с точки зрения конвейера процессоры были скалярными, т.е. имели 1 конвейер. Начиная с процессора Pentium(5е поколение), у процессоров стало 2 конвейера.
Эти 2 конвейера неравнозначны (U и V).
U – главный конвейер (команды идут всегда).
По второй ветви идут только целочисленные операции, согласованно с основным.
При переходе к процессорам следующего 6го поколения подход к конвейеру изменился.
 BTB0 BTB0
|
| BTB1 |
| IFU0 |
| IFU1 |
| IFU2 |
| ID0 |
| ID1 |
| ROB RD |
| RAT |
| RS |
| P0 | P1 | P2 | P3 | P4 |
| ROB WB |
| RRF |
Увеличилось число ступеней с 5 до 13.
Весь конвейер можно условно разбить на 3 большие части:
1. препроцессор – здесь программы выполняются в соответствии с программным кодом;
2. ядро с неупорядоченным исполнением – команды выполняются в порядке, удобном для максимальной загрузки устройств.
3. упорядочивающее выходное устройство – данные и результаты вычислений выгружаются в порядке, задаваемым программой.
BTB – блок предсказания ветвлений
IFU – блок выборки инструкции
ID – блок декодирования
ROB RD – переупорядочивающий буфер чтения
RAT – блок выделения ресурсов и переименования регистров
RS – станция резервирования
P – порты используемых устройств
ROB WB – переупорядочивающий буфер записи
RRF – буфер регистров
Блок предсказания ветвлений содержит информацию о выполненных ранее командах условного перехода.
Инструкции предварительно выбираются с помощью блока предвыборки большими блоками из памяти и предварительно декодируются.
Блок дешифрации за каждый такт работы конвейера может декодировать до 3х инструкций. Причем команда на языке ассемблера переводится в простые микрооперации µ-ops (u-ops), причем в 2х потоках могут декодироваться команды, содержащие 1 микрооперацию, а в третьем – 4 µ-ops. Такой подход характерен для RISC-архитектуры.
Простые команды, содержащие 1 микрооперацию: команды типа «регистр-регистр».
2 микрооперации: запись и простые команды чтения.
4 микрооперации: чтение, модификация, запись.
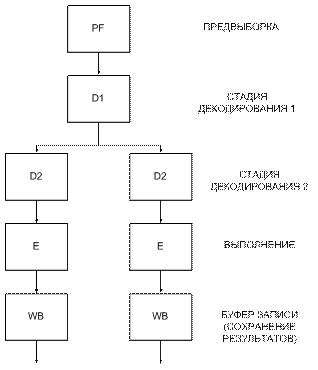
1.4 Защищенный режим 32-разрядных процессоров
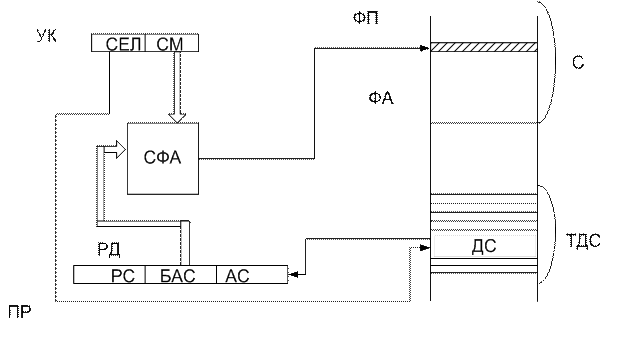
ПР – процессор
ФП – физическая память
УК – указатель
СЕЛ – селектор
СМ – смещение
СФА – сумматор физического адреса
РД – регистр дескриптора
ФА – физический адрес
С – сегмент
ТДС – таблица дескриптора сегмента
ДС – дескриптор сегмента
РС – размер сегмента
БАС – базовый адрес сегмента
АС – атрибуты сегмента
Сегментный регистр содержит не базовый адрес сегмента, а селектор – адрес нужной строки специальной таблицы под названием ТДС, расположенной в оперативной памяти. Дескриптор – это служебное слово, описывающее сегмент, использующаяся для определения свойств программных элементов. Дескриптор одержит базовый адрес сегмента, размер сегмента, назначение и характеристики защиты.
Процессор имеет несколько таблиц дескрипторов:
- локальная (Local Description Table (LTD));
- глобальная (GDT);
- таблица прерываний (IDT).
С каждой из таблиц связан соответствующий регистр процессора.
Загрузка дескрипторов выполняется с помощью привилегированных команд операционной системы. Глобальная таблица содержит доступные всем задачи. Локальная – только собственные задачи.
Обычно 4х уровневую систему привилегий рисуют с помощью коелц защиты.
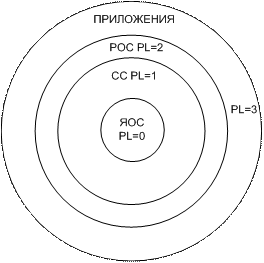
PL – уровень привилегий:
0 – ядро ОС;
1 – системные сервисы;
2 – расширения ОС;
3 – приложения.
Задаче могут предоставляться сервисы, находящиеся в разных кольцах защиты. Передача управления между задачами контролируется вентилями или шлюзами. Они проверяют правила использования уровней привилегий.
Существует несколько элементов задачи уровня привилегий.
В регистре CS задается CPL – текущий уровень привилегий данной программы. Если CPL=0, то она может обращаться ко всем сегментам, описанным в глобальной таблице дескрипторов. Если он =3, то задача с самым низким уровнем привилегий.
Поле атрибутов сегмента содержит подполе DPL – поле привилегий дескриптора (все они занимают 2 бита (0-3)). Если DPL=0, то соответствующий дескриптор самый защищенный, к нему может обратиться задача с CPL=0. DPL=3 – обращаются все.
Привилегии селектора RPL – запрошенный уровень привилегии.
Существуют и другие уровни привилегий.
Переключение задач
Характерно для многозадачных систем.
Сохраняет состояние процессора и связь с предыдущей задачей и загружает состояние новой задачи.
Переключение задач происходит по инструкции межсегментного перехода и по прерыванию. В оперативной памяти имеется сегмент состояния задачи (TSS). В составе процессора имеется специальный регистр задач (RS). Он имеет селектор, который ссылается на дескриптор текущего TSS. При переключении задач достаточно загрузить новый селектор в регистр задачи.
Сегментация
В 32-разрядном процессоре различают 3 вида адреса: логический, линейный, физический. В защищенном режиме существуют все виды преобразований.
Логический (виртуальный) состоит из селектора и эффективного адреса offset.
Линейный адрес образуется сложением базового адреса сегмента и смещения.
Физический получается из линейного после преобразования страничной переадресации.
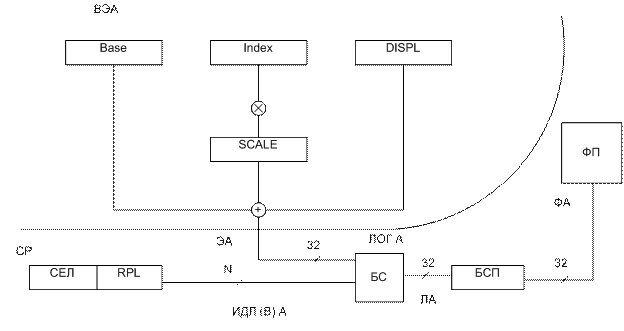
ЭА – эффективный адрес
ЛОГ А – логический адрес
ЛА – линейный адрес
ФА – физический адрес
ВА – вычисление ЭА
СР – сегментный регистр
БС – блок сегментации
БСП – блок страничной переадресации
ФП – физическая память
ИДЛ (В) А – индекс дескриптора логического (виртуального) адреса
EA=Base+Index*Scale+Displ
В общем случае эффективный адрес вычисляется по этой формуле.
Displ – смещение – число, включенное в команду
Base – содержимое базового регистра. Обычно используется для адресации начала массива.
Index – содержимое индексного регистра (для выбора элемента массива)
Scale – размер элемента массива (множитель, задаваемый кодом).
Некоторые слагаемые в формуле могут отсутствовать.
Страничное управление памятью
Базовый механизм страничного управления использует 2х уровневую табличную трансляцию линейного адреса в физический.
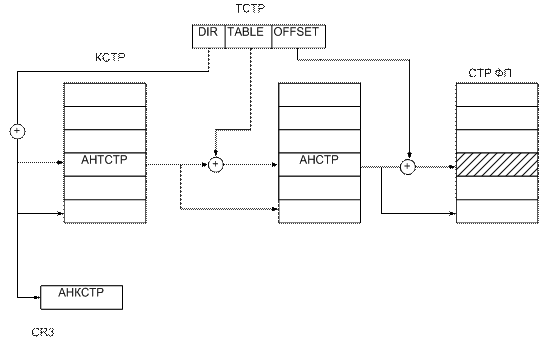
КСТР – каталог страниц, ТСТР – таблица страниц, СТР ФП – страница физической памяти, АН – адрес начала, DIR – смещение
Для каждой задачи имеется регистр CR3, он хранит физический адрес каталога страниц. К этому адресу добавляется полк DIR из линейного адреса и мы обращаемся к определенной строке. В ней хранится адрес начала таблицы страниц. Складывая его с TABLE, получаем нужную строку таблицы, где находится базовый адрес страницы. Сложив его с offset выбираем нужную ячейку.
Недостаток – низкое быстродействие.
Обращение при каждой операции доступа к памяти к 2м таблицам, расположенным в памяти, существенно снижает производительность. Поэтому используется буфер ассоциативной трансляции (блок быстрой переадресации) (TLB). Он применяется для хранения интенсивно используемых строк таблицы. В первых 32х разрядных процессорах он хранил 32 строки. Он организован в виде 4х канальной наборно-ассоциативной кэш памяти. При этом получается коэффициент кэш попаданий 98%.
Режим виртуального 8086 (V86)
Прикладные программы для 8086 могут исполняться на 32-разрядных процессорах как в реальном режиме, так и в режиме виртуального 8086 (V86), который является особым состоянием задачи защищенного режима. Режим V86 более привлекателен своими возможностями и гибкостью. В этом режиме работает защита и механизм страничной переадресации, позволяющий адресоваться к любой области 4-гигабайтного пространства памяти. Выполнение приложений 8086 в среде V86 возможно параллельно с приложениями защищенного режима. Кроме того, страничная переадресация позволяет нескольким V86 совместно использовать общие области кода операционной системы.
Все программы, выполняемые в режиме V86, имеют уровень привилегий 3, то есть минимальные привилегии (реальный режим подразумевает уровень привилегий 0). Таким образом, программы в V86 выполняются со всеми проверками защиты.
| <== предыдущая лекция | | | следующая лекция ==> |
| Динамическая маршрутизация. | | | Числовая последовательность |
Дата добавления: 2017-09-19; просмотров: 1084;