С гетероскедастичными остатками
Довольно часто при построении регрессии анализируемые объекты неоднородны, например, при исследовании структуры потребления домохозяйств естественно ожидать, что колебания в структуре будут выше для богатых, чем для бедных домохозяйств. В этой ситуации предположение (3.3) о постоянстве дисперсии случайной ошибки (имеется в виду возможное поведение случайного члена до того, как сделана выборка) оказывается не соответствующим действительности. В случаях, когда дисперсия uодинакова в каждый момент времени или для каждого значения X, существуют определенные ограничения (в некоторой полосе) для расположения точек на графике X и Y, согласно которым отчетливой тенденции к увеличению или уменьшению дисперсии 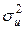 по мере роста X не наблюдается.
по мере роста X не наблюдается.
На рис. 4.1 приводятся примеры изменения разброса (гетероскедастичности) случайной ошибки регрессии.
На рис. 4.1а изображена ситуация, когда значения дисперсии растут по мере увеличения значений регрессора X. На рис. 4.1б дисперсия ошибки достигает максимальной величины при средних значениях X, уменьшаясь по мере приближения к крайним значениям. Наконец, на рис. 4.1в дисперсия ошибки оказывается наибольшей при малых значениях X, быстро уменьшается и становится однородной по мере увеличения независимой переменной X.
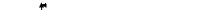 | 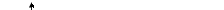 |
Рис. 4.1. Примеры гетероскедастичности
Гетероскедастичность дисперсии случайного члена означает, что
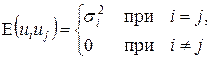 , (4.8)
, (4.8)
т.е. нарушается предположение (3.3) в КЛММР, и мы должны рассматривать ОЛММР с нулевой ковариацией случайных ошибок (ср. (4.5) и (4.8)).
Основные последствия гетероскедастичности проявляются в получении неэффективных оценок МНК и занижении стандартных ошибок коэффициентов регрессии, что завышает t-статистику и дает неправильное представление о точности уравнения регрессии.
Поэтому для оценивания регрессии с гетероскедастичными случайными ошибками применяется ОМНК.
Предположим, что нам известны значения величин 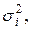 i =1,…,n. Тогда уравнение (4.3) разделим на si:
i =1,…,n. Тогда уравнение (4.3) разделим на si:
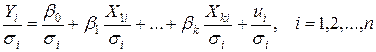 ,
,
и получим регрессию с постоянной (гомоскедастичной) дисперсией случайного члена, действительно 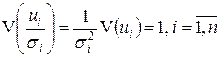 .
.
Для получения оценок неизвестных дисперсий i =1,…,n будем предполагать, что они пропорциональны некоторым числам, т.е. 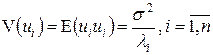 , где s2 – некоторая константа.
, где s2 – некоторая константа.
Принимая различные гипотезы относительно характера гетероскедастичности, будем иметь соответствующие значения li.
Если дисперсия случайного члена пропорциональна квадрату регрессора X, так что 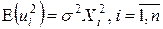 , то
, то 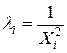 , i =1,…,n.
, i =1,…,n.
Если дисперсия случайного члена пропорциональна X, так что 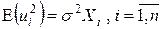 , то
, то 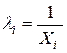 , i =1,…,n. Например, для случая одной объясняющей переменной имеем в этом случае систему уравнений ОМНК вида:
, i =1,…,n. Например, для случая одной объясняющей переменной имеем в этом случае систему уравнений ОМНК вида:
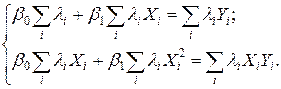
Поскольку значения li, i =1,…,n являются фактически весами, которые устраняют неоднородность дисперсии, то ОМНК для системы с гетероскедастичностью часто называют методом взвешенных наименьших квадратов.
Существуют также и другие методы коррекции модели на гетероскедастичность, в частности состоятельное оценивание стандартных ошибок. Известны способы коррекции стандартных ошибок Уайта и Невье-Веста [5, с. 144-146].
О проверке выборки на гомоскедастичность.
Рассмотрим вопрос тестирования выборки на наличие гомоскедастичности. Возможности такой проверки зависят от природы исходных данных.
Если имеется обширная выборка, то можно воспользоваться стандартным критерием однородности дисперсии Бартлетта.
Расчленяя выборку на m независимых групп (каждой из них соответствует единственное значение переменной X), вычислим величины:
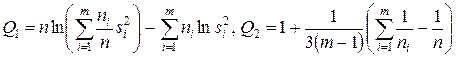 ,
,
причем åni=n, здесь ni - число наблюдений в i группе, 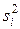 - дисперсия ошибки в i группе. Величина Q1/Q2 будет приближенно удовлетворять распределению c2 с (m-1) степенями свободы. Если вычисленное по выборке значение c2 меньше критического, то гипотеза об однородности выборочной дисперсии принимается, в противном случае отклоняется.
- дисперсия ошибки в i группе. Величина Q1/Q2 будет приближенно удовлетворять распределению c2 с (m-1) степенями свободы. Если вычисленное по выборке значение c2 меньше критического, то гипотеза об однородности выборочной дисперсии принимается, в противном случае отклоняется.
В случаях малого количества наблюдений в выборке, когда группировка данных невозможна, используется тест Голдфелда и Куандта. Он предусматривает осуществление следующих шагов:
1. Упорядочить наблюдения по убыванию той независимой переменной, относительно которой есть подозрение на гетероскедастичность.
2. Опустить v наблюдений, оказавшихся в центре (v должно быть примерно равно четверти общего количества наблюдений n).
3. Оценить отдельно обыкновенным методом наименьших квадратов регрессии на первых (n-v)/2 наблюдениях и на последних (n-v)/2 наблюдениях при условии, что (n-v)/2 больше числа оцениваемых параметров k.
4. Пусть e1 и e2 - суммы квадратов остатков от первой и второй регрессий соответственно. Тогда статистика Q=e1/e2 будет удовлетворять F - распределению с ((n-v-2k)/2; (n-v-2k)/2) степенями свободы. При Q < Fa гипотеза об однородности выборочной дисперсии принимается, в противном случае (с ростом величины Q) отклоняется.
Очевидно, что решающим для этого теста является выбор величины v. Слишком большое значение v уменьшает надежность теста. Экспериментально авторами теста установлено, что для одной объясняющей переменной оптимальное v=8 при n=30 и v=16 при n=60.
Кроме перечисленных, могут использоваться тесты на гетероскедастичность Уайта, Бреуша-Пагана и др.
Пример. Проверим по критерию Бартлетта данные из примера 1 раздела 3. Будем иметь табл. 4.1. В табл. 4.1 учтено, что среднее значение ei равно 0, а значит, 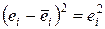 . Примем m=2. Тогда:
. Примем m=2. Тогда:
Q1=20×ln(10/20×167,41 + 10/20×59,69) - (10×ln(167,41)+10×ln(59,69))=2,55; Q2=1+1/3×(1/10+1/10-1/20)=1,05; Q1/Q2=2,43.
При одной степени свободы критическое значение c2 при 5% уровне значимости равно 3,84, а следовательно, гипотеза об однородности выборочной дисперсии принимается.
Для тех же данных применим тест Гольдфельда и Куандта. В нашем случае число объясняющих переменных k=2, количество исходных данных в выборке n=20. Упорядочим наблюдения по убыванию независимой переменной X2 – расстояние перевозки, относительно которой есть подозрение на гетероскедастичность. Опустим 4 наблюдения, оказавшихся в центре, т.е. v=4. При значении v=4 получим суммы квадратов остатков от первой и второй регрессий соответственно e1=1167,38 и e2=31,49. Статистика Q=e1/e2=1167,38/31,49 = 37,07 удовлетворяет F-распределению с (6; 6) степенями свободы. F0,05(6, 6) = 4,28, Q > F и гипотеза об однородности выборочной дисперсии должна быть отвергнута.
Поскольку тесты дают противоположные результаты (что не редкость в эконометрике), то лучше согласиться с наихудшим вариантом, т.е. предположить наличие гетероскедастичности и предпринять соответствующие корректирующие меры. В частности, скорректировать стандартные ошибки по формуле Невье-Веста. В таблице 4.2 представлены результаты регрессии до корректировки и после корректировки на гетероскедастичность. Видно, что на величине коэффициентов регрессии корректировка на гетероскедастичность не отражается, а стандартные ошибки и значения статистик были пересчитаны. Ñ
Таблица 4.1
Дата добавления: 2017-04-20; просмотров: 630;