Компьютеры и программное обеспечение. Базы данных
Техническую основу обеспечения информационных технологий составляют средства компьютерной техники, средства коммуникационной техники и средства организационной техники.
Средства компьютерной техники составляют базис всего комплекса технических средств информационных технологий и предназначены прежде всего для обработки и преобразования различных видов информации, используемой в управленческой деятельности.
Средства коммуникационной техники обеспечивают одну из основных функций управленческой деятельности - передачу информации в рамках системы управления и обмен данными с внешней средой, и предполагают использование разнообразных методов и технологий, в том числе с применением компьютерной техники.
Средства организационной техники предназначены для механизации и автоматизации управленческой деятельности во всех ее проявлениях.
Вычислительная техника прошла те же исторические этапы эволюции, которые прошли и все прочие технические устройства: от ручных приспособлений к механическим устройствам и далее к гибким автоматическим системам. Современный компьютер — это прибор. Его принцип действия — электронный, а назначение — автоматизация операций с данными. Гибкость автоматизации основана на том, что операции с данными выполняются по заранее заготовленным и легко сменяемым программам. Универсальность компьютеров основана на том, что любые типы данных представляются в нем с помощью универсального двоичного кодирования.
В отечественной и зарубежной литературе существует достаточно много систем классификации компьютеров, рассмотрим следующие из них: классификация по назначению; по спецификации PC99; по уровню специализации; по размеру. Все виды классификаций достаточно условны, поскольку интенсивное развитие технологий приводит к размыванию границ между различными классами компьютеров.
Классификация по назначению. По этому принципу выделяют:
· Мэйнфреймы (большие ЭВМ);
· Мини ЭВМ;
· Настольные персональные компьютеры;
· Рабочие станции;
· Серверы начального и высокого уровня;
· Суперкомпьютеры.
Мэйнфреймы (Mainframe). Это многопользовательские вычислительные системы, имеющие центральный блок с большой вычислительной мощностью и значительными информационными ресурсами, к которому присоединяется большое число рабочих мест с минимальной оснащенностью (видеотерминал, клавиатура, мышь). Их применяют для решения научных, военных задач, требующих обработки очень больших массивов данных, такие компьютеры могут обслуживать целые отрасли народного хозяйства. Быстродействие мэйнфреймов составляет миллионы операций в секунду, оперативная память - один и более Гигабайт.
Мини ЭВМ. От больших компьютеров компьютеры этой группы отличаются меньшими размерами, меньшей производительностью и стоимостью. Такие компьютеры используются крупными предприятиями, научными учреждениями, банками.
Персональные компьютеры (ПК). Многие современные модели персональных компьютеров превосходят большие ЭВМ 70-х годов, мини ЭВМ 80-х годов. ПК применяются для решения задач автоматизации управления предприятиями, автоматизации учебного процесса, индивидуальной работы пользователя. Особенно широкую популярность ПК получили в связи с бурным развитием сети Интернет. Персонального компьютера вполне достаточно для использования всемирной сети в качестве источника научной, справочной, учебной и др. информации. На характеристиках и возможностях персонального компьютера мы остановимся позднее.
Рабочие станции предназначены для инженеров и пользователей настольных издательских систем, там, где нужно работать со сложной графикой. Такие системы оснащаются процессором Pentium III, IVс 2 Мб кэш-памяти второго уровня.
Серверы начального и высокого уровня. На сервер начального уровня устанавливают один или два процессора. Сервер начального уровня может поддерживать небольшую локальную сеть (до 40 пользователей). Серверы высокого уровня имеют обычно от двух до восьми процессоров, не менее двух источников питания. Серверы содержат большие объемы оперативной (до 4-х Гб) и дисковой памяти (6Тб и более).
Суперкомпьютеры. Применяются для решения задач в области метеорологии, аэродинамики, сейсмологии, различных военных исследованиях, в атомной и ядерной физике, физике плазмы, математическом моделировании сложных систем. Производительность суперкомпьютеров измеряется в триллионах операций с «плавающей точкой» в секунду, так называемых терафлопах. Например, для предсказания погоды используется 1024-процессорный компьютер Cray T3E900 фирмы SGI, показавший производительность 69 Гфлоп (миллиардов операций с плавающей точкой в секунду) на программе по прогнозированию погодных катаклизмов (HILARM). Этот же компьютер, но оснащенный 1328 процессорами, показал производительность 1,195 Тфлоп, что позволило предсказывать стихийные бедствия за 6 часов до их начала. Компьютер Cray T3E900 используется для построения трехмерных моделей гелиосферы, моделирования процессов, протекающих в земной коре и др.
Классификация по спецификации PC99. Начиная с 1999 г. в области персональных компьютеров начал действовать международный сертификационный стандарт – спецификация PC99. В соответствии с этой классификацией выделяют следующие категории персональных компьютеров:
· Consumer PC (массовый ПК);
· Office PC (офисный ПК);
· Mobile PC (мобильный, переносной);
· Workstation PC (рабочая станция);
· Entertainment PC (развлекательный ПК).
Классификация по размерам.Персональные компьютеры можно классифицировать по типоразмерам: Настольные; портативные (notebook); карманные (palmtop).
Программное обеспечение (ПО) компьютера называют мягким оборудованием или SOFTWARE.
В зависимости от функций, выполняемых программным обеспечением, его можно разделить на 2 группы: системное программное обеспечение и прикладное программное обеспечение.
Системное ПО организует процесс обработки информации на компьютере и обеспечивает нормальную рабочую среду для прикладных программ. Системное ПО настолько тесно связано с аппаратными средствами, что его иногда считают частью компьютера.
В состав системного ПО входят:
• операционные системы;
• сервисные программы;
• трансляторы языков программирования;
• программы технического обслуживания.
Операционная система (ОС) ¾ это совокупность программ, управляющая аппаратной частью компьютера, его ресурсами (оперативной памятью, местом на дисках), обеспечивающая запуск и выполнение прикладных программ, автоматизацию процессов ввода/вывода. Без операционной системы компьютер мертв. ОС загружается при включении компьютера.
Прикладное ПО предназначено для решения конкретных задач пользователя и организации вычислительного процесса информационной системы в целом.
Прикладное ПО позволяет разрабатывать и выполнять задачи (приложения) пользователя по бухгалтерскому учету, управлению персоналом и т.п.
Прикладное программное обеспечение работает под управлением системного ПО, в частности операционных систем. В состав прикладного ПО входят:
• пакеты прикладных программ (ППП) общего назначения;
• пакеты прикладных программ функционального назначения.
ППП общего назначения ¾ это универсальные программные продукты, предназначенные для автоматизации разработки и эксплуатации функциональных задач пользователя и информационных систем в целом.
К этому классу ППП относятся:
• редакторы текстовые (текстовые процессоры) и графические;
• электронные таблицы;
• системы управления базами данных (СУБД);
• интегрированные пакеты;
• Case-технологии;
• оболочки экспертных систем и систем искусственного интеллекта.
К ППП функционального назначения относятся программные продукты, ориентированные на автоматизацию функций пользователя в конкретной сфере экономической деятельности. К данному классу относятся пакеты программ по бухгалтерскому учету, технико-экономическому планированию, разработке инвестиционных проектов, управлению персоналом, системы автоматизированного управления предприятием в целом.
Базами данных (БД) называют электронные хранилища информации, доступ к которым осуществляется с помощью одного или нескольких компьютеров. Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, то есть некоторой области человеческой деятельности или области реального мира.
Системы управления базами данных (СУБД) — это программные средства, предназначенные для создания, наполнения, обновления и удаления баз данных. Различают три основных вида СУБД: промышленные универсального назначения, промышленные специального назначения и разрабатываемые для конкретного заказчика. Специализированные СУБД создаются для управления базами данных конкретного назначения — бухгалтерские, складские, банковские и т. д. Универсальные СУБД не имеют четко очерченных рамок применения, они рассчитаны «на все случаи жизни» и, как следствие, достаточно сложны и требуют от пользователя специальных знаний. Как специализированные, так и универсальные промышленные СУБД относительно дешевы, достаточно надежны (отлажены) и готовы к немедленной работе, в то время как заказные СУБД требуют существенных затрат, а их подготовка к работе и отладка занимают значительный период (от нескольких месяцев до нескольких лет). Однако в отличие от промышленных заказные СУБД в максимальной степени учитывают специфику работы заказчика (того или иного предприятия), их интерфейс обычно интуитивно понятен пользователям и не требует от них специальных знаний.
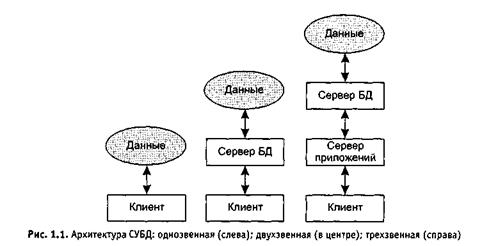
По своей архитектуре СУБД делятся на одно-, двух- и трехзвенные (рис.2). В однозвенной архитектуре используется единственное звено (клиент), обеспечивающее необходимую логику управления данными и их визуализацию. В двухзвенной архитектуре значительную часть логики управления данными берет на себя сервер БД, в то время как клиент в основном занят отображением данных в удобном для пользователя виде. В трехзвенных СУБД используется промежуточное звено — сервер приложений, являющееся посредником между клиентом и сервером БД. Сервер приложений призван полностью избавить клиента от каких бы то ни было забот по управлению данными и обеспечению связи с сервером БД.
|
|
В зависимости от расположения отдельных частей СУБД различают локальные и сетевые СУБД.
Все части локальной СУБД размещаются на компьютере пользователя базы данных. Чтобы с одной и той же БД одновременно могло работать несколько пользователей, каждый пользовательский компьютер должен иметь свою копию локальной БД. Существенной проблемой СУБД такого типа является синхронизация копий данных, именно поэтому для решения задач, требующих совместной работы нескольких пользователей, локальные СУБД фактически не используются.
К сетевым относятся файл-серверные, клиент-серверные и распределенные СУБД. Непременным атрибутом этих систем является сеть, обеспечивающая аппаратную связь компьютеров и делающая возможной корпоративную работу множества пользователей с одними и теми же данными.
В файл-серверных СУБД все данные обычно размещаются в одном или нескольких каталогах достаточно мощной машины, специально выделенной для этих целей и постоянно подключенной к сети. Такой компьютер называется файл-сервером — отсюда название СУБД. Безусловным достоинством СУБД этого типа является относительная простота ее создания и обслуживания — фактически все сводится лишь к развертыванию локальной сети и установке на подключенных к ней компьютерах сетевых операционных систем. По счастью, Delphi «умеет» использовать сетевые средства самой популярной в мире ОС — Windows — для создания соответствующих клиентских мест, то есть специального программного обеспечения компьютеров пользователей. Нетрудно заметить, что между локальными и файл-серверными вариантами СУБД нет особых различий, так как в них все части собственно СУБД (кроме данных) находятся на компьютере клиента. По архитектуре они обычно являются однозвенными, но в некоторых случаях могут использовать сервер приложений. Недостатком файл-серверных систем является значительная нагрузка на сеть. Если, например, клиенту нужно отыскать сведения об одной из фирм-партнеров, по сети вначале передается весь файл, содержащий сведения о многих сотнях партнеров, и лишь затем в созданной таким образом локальной копии данных отыскивается нужная запись. Ясно, что при интенсивной работе с данными уже нескольких десятков клиентов пропускная способность сети может оказаться недостаточной, и пользователя будут раздражать значительные задержки в реакции СУБД на его требования. Файл-серверные СУБД могут успешно использоваться в относительно небольших фирмах с количеством клиентских мест до нескольких десятков.
Клиент-серверные (двухзвенные) системы значительно снижают нагрузку на сеть, так как клиент общается с данными через специализированного посредника — сервер базы данных, который размещается на машине с данными. Сервер БД принимает запрос от клиента, отыскивает в данных нужную запись и передает ее клиенту. Таким образом, по сети передается относительно короткий запрос и единственная нужная запись, даже если соответствующий файл с данными содержит сотни тысяч записей. Запрос к серверу формируется на специальном языке структурированных запросов (Structured Query Language, SQL), поэтому часто серверы БД называются SQL-серверами. Серверы БД представляют собой относительно сложные программы, изготавливаемые различными фирмами. К ним относятся, например, Microsoft SQL Server производства корпорации Microsoft, Sybase SQL Server корпорации Sybase, Oracle производства одноименной корпорации1, DB2 корпорации IBM in. д. SQL-сервером является также и сервер InterBase корпорации Inprise, который поставляется вместе с Delphi в комплектации Enterprise. Клиент-серверные СУБД масштабируются до сотен и тысяч клиентских мест.
Распределенные СУБД могут содержать несколько десятков и сотен серверов БД. Количество клиентских мест в них может достигать десятков и сотен тысяч. Обычно такие СУБД работают на предприятиях государственного масштаба, отдельные подразделения которых разнесены на значительной территории. К таковым, например, относятся подразделения Министерства обороны и Министерства внутренних дел. В распределенных СУБД некоторые серверы могут дублировать друг друга с целью достижения предельно малой вероятности отказов и сбоев, которые могут исказить жизненно важную информацию. Они используют собственные региональные средства связи. Интерес к распределенным СУБД возрос в связи со стремительным развитием Интернета. Опираясь на возможности Интернета, распределенные системы строят не только предприятия государственного масштаба, но и относительно небольшие коммерческие предприятия, обеспечивая своим сотрудникам работу с корпоративными данными на дому и в командировках.
CASE-технологии. CASE-технологии применяются при создании сложных информационных систем, обычно требующих коллективной реализации проекта, в котором участвуют различные специалисты: системные аналитики, проектировщики и программисты.
Модели данных
В экономике существуют объекты, предметы, информацию о которых необходимо хранить, и эти объекты связаны между собой самыми разными способами. Чтобы область хранения данных рассматривалась в качестве базы данных, в ней должны содержаться не только данные, но и сведения о взаимоотношениях между этими данными.
Различают логический и физический уровни организации данных. Физический уровень отражает организацию хранения БД на машинных носителях, а логический уровень ¾ внешнее представление данных пользователю.
Логическая организация данных па машинном носителе зависит от используемых программных средств организации и ведения данных. Метод логической организации данных определяется используемыми типом структур данных и видом модели., которая поддерживается программным средством.
Модель данных — это совокупность взаимосвязанных структур данных и операций над этими структурами. Вид модели и используемые в ней типы структур данных отражают концепцию организации и обработки данных, используемую в СУБД, поддерживающей модель, или в языке системы программирования, на котором создается прикладная программа обработки данных.
Важно отметить, что для размещения одной и той же информации во внутримашинной сфере могут быть использованы различные структуры и модели данных. Их вы6op возлагается на пользователя, создающего информационную базу, и зависит от многих факторов, в том числе от имеющегося технического и программного обеспечения, определяется сложностью автоматизируемых задач и объемом информации.
По способу организации БД разделяют на базы с плоскими файлами, иерархические, сетевые, реляционные, объектно-реляционные и объектно-ориентированные базы данных.
Файловая модель. На ранней стадии использования информационных систем в экономике применялась файловая модель данных. В файловых системах реализуется модель типа плоский файл.
Плоский файл ¾ это файл, состоящий из записей одного типа и не содержащий указателей на другие записи, двумерный массив элементов данных. Файлы, которые создаются в прикладных программах пользователя, написанных на алгоритмическом языке, также относятся к этому виду организации данных. Описание логической структуры файлов и параметры размещения на машинных носителях содержатся в каждой прикладной программе обработки файлов. В этих же программах предусмотрено их создание и корректировка. При файловой организации массивов трудно обеспечить актуальное состояние данных, их достоверность и непротиворечивость.
Сетевые и иерархические модели. Более сложными моделями данных по сравнению с файловой являются сетевые и иерархические модели, которые поддерживаются в системе управления базами данных соответствующего типа. Тип модели данных, поддерживаемой СУБД на машинном носителе, является одним из важнейших признаков классификации СУБД.
Сетевая или иерархическая модель данных представляет соответствующий метод логической организации базы данных в СУБД.
Иерархическая модель представляет собой древовидную структуру с корневыми сегментами, имеющими физический указатель на другие сегменты. Одно из неудобств этой модели заключается в том, что реальный мир не может быть представлен в виде древовидной структуры с единственным корневым сегментом. Иерархические БД обеспечивали указатели между различными деревьями баз данных, но обработка данных с использованием таких связей была не всегда удобной.
В иерархических моделях непосредственный доступ, как правило, возможен только к объекту самого высокого уровня, который не подчинен другим объектам. К другим объектам доступ осуществляется по связям от объекта на вершине модели. В сетевых моделях непосредственный доступ может обеспечиваться к любому объекту независимо от уровня, на котором oн находится в модели. Возможен также доступ по связям от любой точки доступа.
В отличие от иерархической БД в сетевой БД нет необходимости в корневой записи. Однако, как и в иерархических БД, связи поддерживаются с помощью физических указателей.
Сетевые модели данных по сравнению с иерархическими являются более универсальным средством отображения структуры информации для разных предметных областей. Взаимосвязи данных большинства предметных областей имеют сетевой характер, что ограничивает использование СУБД с иерархической моделью данных. Сетевые модели позволяют отображать также иерархические взаимосвязи данных. Достоинством сетевых моделей является отсутствие дублирования данных в различных элементах модели. Кроме того, технология работы с сетевыми моделями является удобной для пользователя, так как доступ к данным практически не имеет ограничений и возможен непосредственно к объекту любого уровня. Допустимы всевозможные запросы.
Реляционная модель данных. Концепция реляционной модели баз данных была предложена Э.Ф. Коддом в 1970 г. Как отмечал доктор Кодд, реляционная модель данных обеспечивает ряд возможностей, которые делают управление и использование базы данных относительно легким, предсказуемым и устойчивым по отношению к ошибкам. Наиболее важные характеристики реляционной модели заключены в следующем:
· Модель описывает данные с их естественной структурой, не добавляя каких-либо дополнительных структур, необходимых для машинного представления или для целей реализации.
· Модель обеспечивает математическую основу для интерпретации выводимости, избыточности и непротиворечивости отношений.
· Модель обеспечивает независимость данных от их физического представления, от связей между данными и от соображений реализации, связанных с эффективностью и подобными проблемами.
Реляционные модели данных отличаются от рассмотренных выше сетевых и иерархических простотой структур данных, удобным для пользователя табличным представлением и доступом к данным. Реляционная модель данных является совокупностью простейших двумерных таблиц - отношений (объектов модели). Связи между двумя логически связанными таблицами в реляционной модели устанавливаются по равенству значений одинаковых атрибутов таблиц-отношений.
Таблица-отношение является универсальным объектом реляционных моделей. Это обеспечивает возможность унификации обработки данных в различных СУБД, поддерживающих реляционную модель. Операции обработки реляционных моделей основаны на использовании универсального аппарата алгебры отношений и реляционного исчисления.
Структуры данных реляционной модели.Таблица является основным типом структуры данных (объектом) реляционной модели. Структура таблицы определяется совокупностью столбцов. Данные в пределах одного столбца однородны. В таблице не может быть двух одинаковых строк. Общее число строк не ограничено.
Столбец соответствует некоторому элементу данных — атрибуту, который является простейшей структурой данных. В таблице не могут быть определены множественные элементы, группа или повторяющаяся группа, как в рассмотренных выше сетевых и иерархических моделях. Каждый столбец таблицы должен иметь имя соответствующего элемента данных (атрибута). Один или несколько атрибутов, значения которых однозначно идентифицируют строку таблицы, являются ключом таблицы.
В реляционном подходе к построению баз данных используется терминология теории отношений. Простейшая двумерная таблица определяется как отношение. Столбец таблицы со значениями соответствующего атрибута называется доменом, а строки со значениями разных атрибутов — кортежем.
Совокупность нормализованных отношений (реляционных таблиц), логически взаимосвязанных и отражающих некоторую предметную область, образует реляционною базу данных (РБД). В ходе разработки БД должен быть определен состав логически взаимосвязанных реляционных таблиц и определен состав aтрибутов каждого отношения. Состав атрибутов должен отвечать требованиям нормализации.
Реляционная модель данных зарекомендовала себя как модель, на основе которой могут разрабатываться реальные жизнеспособные приложения. В настоящее время эта модель данных является наиболее популярной.
Объектно-ориентированная модель данных. Реляционная модель данных оказалась эффективной не для всех приложений. Главными среди типов приложений, для которых трудно использовать реляционные базы данных, являются автоматизированное проектирование (Computer Aided design, CAD) и автоматизированная разработка программного обеспечения (Computer Aided Software Engineering, CASE). Разработчики коммерческих продуктов в таких областях, в которых для управления хранением данных используется реляционная СУБД, должны пойти на некоторые изменения данных для того, чтобы подогнать их к структуре строк и столбцов. Как показывает практика, в таких областях, как CAD и CASE более подходит объектно-ориентированная модель данных. В объектно-ориентированных базах данных (ООБД) важнейшее место отводится объектам, на основе которых могут определяться другие объекты благодаря использованию концепции, называемой наследованием. При этом некоторые или все атрибуты (либо свойства) определяющего объекта наследуются каким-то другим объектом, одни атрибуты и свойства добавляются, а другие могут удаляться.
Дата добавления: 2017-01-29; просмотров: 1983;