Данные и их разновидности
Данные в статистике – это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные результаты, свойства, присущие определенным членам популяции, место в той или иной последовательности – любая информация, которая может быть классифицирована или разбита на категории с целью обработки.
Построение распределения ряда данных – это разделение первичных данных, полученных на выборке, на классы или категории с целью получить обобщенную упорядоченную картину, позволяющую их анализировать. Существуют три типа данных:
1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т.п.). Их можно распределить по шкале с равными интервалами.
2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке.
3. Качественные данные, представляющие собой какие-то свойства элементов выборки или популяции. Их нельзя измерить, и единственной их количественной оценкой служит частота встречаемости.
Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры (такие, например, как средняя арифметическая, мода, дисперсия и т.д.). Но даже к количественным данным такие методы можно применить лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение.
1.2. Измерительные шкалы
Поскольку психология имеет дело с психологическими процессами, то она оперирует по необходимости различными числовыми показателями, выражающими частоты, протяженности и напряженность связи между различными характеристиками. Предпосылка всех операций с количественными выражениями свойств психологических процессов и характеристик – первичное измерение качественных признаков или их квантификация. Проблема первичного измерения лишь частично математическая. Чтобы по определенным правилам приписать числа свойствам объекта психологии, надо уяснить их содержательную структуру, найти соответствие между нею и инструментом измерения. Это задачи качественно-количественного анализа. Измерению подлежат любые свойства психологических объектов: качественные и количественные. С количественными дело обстоит просто, для них уже есть общепринятые эталоны измерения (год, рубль, один человек). Качественные характеристики не имеют установленных эталонов измерения. Их приходится конструировать в соответствии с природой изучаемого объекта.
Введем некоторые определения.
Признаки и переменные – это измеряемые психологические явления. Такими явлениями могут быть время решения задачи, количество ошибок.
Значения признака определяются при помощи специальных шкал наблюдения. Психологические переменные являются случайными величинами, поскольку неизвестно заранее, какое именно значение они примут.
Измерение – это приписывание числовых форм объектам или событиям в соответствии с определенными правилами.
С. Стивенсом предложена классификация из 4 типов шкал измерения:
1) номинативная, или номинальная, или шкала наименований;
2) порядковая, или ординальная, шкала;
3) интервальная, или шкала равных интервалов;
4) шкала равных отношений.
Номинативная шкала –это шкала, классифицирующая по названию. Название же не измеряется количественно, оно лишь позволяет отличить один объект от другого или одного субъекта от другого. Номинативная шкала – это способ классификации объектов или субъектов, распределения их по ячейкам классификации.
Простейший случай номинативной шкалы – дихотомическая шкала, состоящая всего лишь из двух ячеек, например: «имеет братьев и сестер – единственный ребенок в семье»; «иностранец – соотечественник»; «проголосовал «за» – проголосовал «против»» и т.п.
Расклассифицировав все объекты, реакции или испытуемых, можно перейти, от наименований к числам, подсчитав количество наблюдений в каждом классе. Номинальная шкала позволяет подсчитывать частоты встречаемости разных наименований или значений признака и затем работать с этими частотами. Единица измерения, которой мы оперируем – это одно наблюдение.
Операции с числами для номинативной шкалы.
1) Нахождение частот распределения по пунктам шкалы с помощью процентирования или в натуральных единицах. Нетрудно подсчитать численность каждой группы и отношение этой численности к общему ряду распределения (частоты).
2) Поиск средней тенденции по модальной частоте. Модальной (Мо) называют группу с наибольшей численностью. Эти две операции дают представление о распределении психологических характеристик в количественных показателях. Его наглядность повышается отображением в диаграммах.
3) Самым сильным способом количественного анализа является установление взаимосвязи между рядами свойств, расположенных неупорядоченно. С этой целью составляют перекрестные таблицы. Помимо простой процентовки в таблицах перекрестной классификации можно подсчитать критерий сопряженности признаков по Пирсону.
Порядковая шкала – это шкала, классифицирующая по принципу «больше – меньше». Если в шкале наименований было безразлично, в каком порядке расположены классификационные ячейки, то в порядковой шкале они образуют последовательность от ячейки «самое малое значение» к ячейке «самое большое значение» (или наоборот).
Это полностью упорядоченная шкала наименований, она устанавливает отношения равенства между явлениями в каждом классе и отношения последовательности в понятиях больше, меньше между всеми без исключения классами.
Упорядоченные номинальные шкалы общеупотребимы при опросах общественного мнения. С их помощью измеряют интенсивность оценок каких-то психологических свойств, суждений, событий, степени согласия или несогласия с предложенными утверждениями. Весьма часто употребляемая разновидность шкал этого типа – ранговые. Они предполагают полное упорядочение каких-то объектов.
Операции с числами.
Интервалы в этой шкале не равны, поэтому числа обозначают лишь порядок следования признаков. И операции с числами – это операции с рангами, но не с количественным выражением свойств в каждом пункте.
1) Числа поддаются монотонным преобразованиям: их можно заменить другими с сохранением прежнего порядка. Так вместо ранжирования от 1 до 5 можно упорядочить тот же ряд в числах от 2 до10. Отношения между рангами останутся неизменными.
2) Суммарные оценки по ряду упорядоченных номинальных шкал – хороший способ измерять одно и то же свойство по набору различных индикаторов.
3) Для работы с материалом, собранным по упорядоченной шкале, можно использовать, помимо модальных показателей (Мо), поиск средней тенденции с помощью медианы (Ме), найти среднее арифметической (М) и сделать оценку разброса данных с помощью дисперсии (D) и стандартного отклонения (σ).
4) Наиболее сильный показатель для таких шкал – корреляция рангов по Спирмену или по Кендаллу. Ранговые корреляции указывают на наличие или отсутствие функциональных связей в двух рядах признаков, измеренных упорядоченными шкалами.
Интервальная шкала – это шкала, классифицирующая по принципу «больше на определенное количество единиц – меньше на определенное количество единиц». Каждое из возможных значений признака отстоит от другого на равном расстоянии.
Шкала интервалов представляет собой полностью упорядоченный ряд с измеренными интервалами между пунктами, причем отсчет начинается с произвольно выбранной величины (нет абсолютного нуля).
Операции с числами в интервальной метрической шкале богаче, чем в номинальных шкалах.
1) Точка отсчета на шкале выбирается произвольно.
2) Все методы описательной статистики.
3) Возможности корреляционного и регрессионного анализа. Можно использовать коэффициент парной корреляции Пирсона и коэффициенты множественной корреляции, что может предсказать изменения в одной переменной в зависимости от изменений в другой или в целом ряде переменных.
Шкала равных отношений –это шкала, классифицирующая объекты или субъектов пропорционально степени выраженности измеряемого свойства. В шкалах отношений классы обозначаются числами, которые пропорциональны друг другу: 2 так относится к 4, как 4 к 8. Это предполагает наличие абсолютной нулевой точки отсчета. Считается, что в психологии примерами шкал равных отношений являются шкалы порогов абсолютной чувствительности (Стивенс С., 1960; Гайда В.К., Захаров В.П., 1982). Возможности человеческой психики столь велики, что трудно представить себе абсолютный нуль в какой-либо измеряемой психологической переменной. Абсолютная глупость и абсолютная честность – понятия скорее житейской психологии.
Возможны преобразования из одной шкалы в другую. Результаты, полученные по шкале интервалов, могут быть преобразованы в ранги или переведены в номинативную шкалу. Рассмотрим, например, первичные результаты шести испытуемых по шкале экстраверсии-интроверсии теста Айзенка (табл. 1).
| Испытуемые | Шкала интервалов | Шкала рангов | Номинативная шкала |
| А | Э | ||
| Б | Э | ||
| В | Э | ||
| Г | И | ||
| Д | И | ||
| Е | И |
Первый столбец – имена испытуемых, второй столбец – балл за выраженность качества (реализована шкала интервалов), третий столбец – в соответствии с исходным баллом испытуемым приписаны ранги (первый ранг получает испытуемый, имеющий наименьший балл, второй ранг - испытуемый, имеющий следующий по величине балл, и т.д.), четвертый столбец - в соответствии с исходными баллами испытуемые распределены на два класса: интроверты (И) -баллы от 0 до 12, экстраверты (Э) - от 13 до 24. Отметим, что каждый раз при переходе от одной шкалы к другой теряется часть информации об испытуемых. Так, при ранжировании оказываются следующими друг за другом испытуемые Д. и Е. имеющие различие первичных оценок в один балл, и испытуемые Б. и Г., имеющие различие первичных оценок в шесть баллов. При распределении испытуемых по классам в один класс попадают сильно различающиеся по первичным оценкам испытуемые.
Мы рассмотрели различные приемы перевода качественных психологических признаков в количественные выражения. Следует отметить, что при описании психологических явлений необходимо всегда отдавать себе отчет в том, какая именно шкала используется, поскольку каждый способ обработки экспериментальных данных рассчитан на определенный тип шкал. Применение математических методов к неадекватным данным приводит к странным, а часто и ложным результатам. Квантификация сложных и далеко не однозначных психологических характеристик накладывает немало ограничений на математические операции с их измерениями. Математик работает с простыми числами, психолог обязан помнить, что в действительности скрывается за величинами, которыми он оперирует.
1) Первое ограничение – соразмерность количественных показателей, фиксированных разными шкалами в рамках одного исследования. Более сильная шкала отличается от слабой тем, что допускает более широкий диапазон математических операций с числами. Все, что допустимо для слабой шкалы допустимо и для более сильной, но не наоборот. Поэтому, смешение в анализе мерительных эталонов разного типа приводит к тому, что не используются возможности сильных шкал.
2) Второе ограничение связано с формой распределения величины фиксированных описанными выше шкалами, которое предполагается нормальным Для нормального распределения оценки меры рассеяния совпадают: Мо=Ме=М, в скошенном хвосты распределения не влияют на среднюю (М).
Таким образом необходимо внимательно изучать форму распределения с точки зрения его отклонения от нормального.
1.3. Генеральная совокупность и выборка
В математической статистике выделяют два фундаментальных понятия: генеральная совокупность и выборка.
Совокупностью называется множество некоторых объектов или элементов, интересующих исследователя;
Свойством совокупности называется реальное или воображаемое качество, присущее некоторым всем ее элементам. Свойство может быть случайным или неслучайным.
Параметром совокупности называется свойство, которое можно квантифицировать в виде константы или переменной величины.
Простая совокупность характеризуется:
• отдельным свойством (например: все студенты России);
• отдельным параметром в виде константы или переменной (Все студенты женского пола);
• системой непересекающихся (несовместных) свойств, к примеру: Все учителя и ученики школ г. Владивостока.
Сложная совокупность характеризуется:
• системой, хотя бы частично пересекающихся свойств (Студенты психологического и математических факультетов ДВГУ, окончивших школу с золотой медалью);
• системой параметров независимых и зависимых в совокупности; при комплексном исследовании личности.
Гомогенной или однородной называется совокупность, все характеристики которой присущи каждому ее элементу;
Гетерогенной или неоднородной называется совокупность, характеристики которой сосредоточены в отдельных подмножествах элементов.
Важным параметром является объем совокупности – количество образующих ее элементов. Величина объема зависит от того, как определена сама совокупность, и какие вопросы нас конкретно интересуют. Допустим нас интересует эмоциональное состояние студента 1-го курса в период сдачи конкретного экзамена в сессию. Тогда генеральная совокупность исчерпывается в течении получаса. Если нас интересует эмоциональное состояние всех студентов 1-го курса, то совокупность будет гораздо больше, и еще больше, если взять эмоциональное состояние всех студентов 1-го курса данного вуза и т.д. Понятно, что совокупности большого объема можно исследовать только выборочным путем.
Выборкой называется некоторая часть генеральной совокупности, то, что непосредственно изучается.
Выборки классифицируются по репрезентативности, объему, способу отбора и схеме испытаний.
Репрезентативная –выборка адекватно отображающая генеральную совокупность в качественном и количественном отношениях. Выборка должна адекватно отображать генеральную совокупность, иначе результаты не совпадут с целями исследования.
Репрезентативность зависит от объема, чем больше объем, тем выборка репрезентативней.
По способу отбора.
Случайная – если элементы отбираются случайным образом. Так как большинство методов математической статистики основывается на понятии случайной выборки, то естественно выборка должна быть случайной.
Неслучайная выборка:
• механический отбор, когда вся совокупность делится на столько частей, сколько единиц планируется в выборке и затем из каждой части отбирается один элемент;
• типический отбор – совокупность делится на гомогенные части, и из каждой осуществляется случайная выборка;
• серийный отбор – совокупность делят на большое число разновеликих серий, затем делают выборку одной какой-либо серии;
• комбинированный отбор – сочетаются рассматриваемые виды отбора, на разных этапах.
По схеме испытаний – выборки могут быть независимые и зависимые.
По объему выборки делят на малые и большие. К малым относят выборки, в которых число элементов n ≤ 30. Понятие большой выборки не определено, но большой считается выборка в которой число элементов > 200 и средняя выборка удовлетворяет условию 30≤ n≤ 200. Это деление условно.
Малые выборки используются при статистическом контроле известных свойств уже изученных совокупностей.
Большие выборки используются для установки неизвестных свойств и параметров совокупности.
1.4. Статистические гипотезы
Основной задачей статистической проверки гипотез в психологических исследованиях является репрезентативное выборочное описание свойств генеральных совокупностей. Для описания значительных по объему совокупностей психических свойств, состояний, процессов требуется накопление огромного выборочного материала или проведение исследований в национальном масштабе. Поэтому задача репрезентативного описания сводится к задаче проверки однородности выборочных описаний, полученных в разных исследованиях, и к объединению однородных данных.
Для проверки однородности, необходимы:
а) однообразность статистических описаний одних и тех же психических явлений разными авторами;
б) указание на величину объектов выборок, из которых вычислялись статистические
оценки параметров и функций.
Начало любого исследования – это постановка проблемы. Самые простые, наивные вопросы являются прототипами проблемы. В неизменных условиях, к которым приспосабливается человек, мир для него беспроблемен. И лишь изменчивость мира и духовная активность людей порождают проблемы.
В отличие от житейской, научная проблема формулируется в терминах определенной научной отрасли. Она должна быть операционализированной.
″Являются ли различия в агрессивности, личностном свойстве людей, генетически детерминированным признаком или зависят от влияний семейного воспитания?″ – это проблема, которая сформулирована в терминах психологии развития и может быть решена определенными средствами.
Постановка проблемы влечет за собой формулировку гипотезы. Гипотеза – это научное предположение, вытекающее из теории, которое еще не подтверждено и не опровергнуто. Научная гипотеза должна удовлетворять:
• принципам фальсифицируемости – быть опровергаемой в эксперименте; принцип фальсифицируемости абсолютен, так как опровержение теории всегда окончательно,
• принципам верифицируемости – быть подтверждаемой в эксперименте, этот принцип относителен, так как всегда есть вероятность опровержения гипотезы в следующем исследовании.
Различают научные и статистические гипотезы. Научные гипотезы формулируются как предполагаемое решение проблемы. Статистическая гипотеза – утверждение в отношении неизвестного параметра, сформулированное на языке математической статистики. Любая научная гипотеза требует перевода на язык статистики. После проведения конкретного эксперимента проверяются многочисленные статистические гипотезы, поскольку в каждом психологическом исследовании регистрируется не один, а множество поведенческих параметров. Каждый параметр характеризуется несколькими статистическими мерами: центральной тенденции, изменчивости, распределения. Можно вычислить меры связи параметров и оценить значимость этих связей.
Научные гипотезы. Экспериментальная гипотеза служит для организации эксперимента, а статистическая – для организации процедуры сравнения регистрируемых параметров. Статистическая гипотеза необходима на этапе математической интерпретации данных эмпирических исследований. Большое количество статистических гипотез необходимо для подтверждения или опровержения основной – экспериментальной гипотезы. Экспериментальная гипотеза – первична, статистическая – вторична.
Процесс выдвижения и опровержения гипотез можно считать основным и наиболее творческим этапом деятельности исследователя. Установлено, что количество и качество гипотез определяется общей креативностью (общей творческой способностью) исследователя – «генератора идей».
Гипотеза может отвергаться, но никогда не может быть окончательно принятой. Любая гипотеза открыта для последующей проверки.
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде.
Статистические гипотезы. В обычном языке слово «гипотеза» означает предположение. В том же смысле оно употребляется в научном языке, используясь в основном для предположений, вызывающих сомнение. В математической статистике термин «гипотеза» означает предположение, которое не только вызывает сомнения, но и которое мы собираемся в данный момент проверить.
При построении статистической модели приходиться делать много различных допущений и предположений, и далеко не все из них мы собираемся или можем проверить.
Статистическая проверка гипотезы состоит в выяснении того, насколько совместима эта гипотеза с имеющимся результатом случайного выбора.
Определение. Статистическая гипотеза – это предположение о распределении вероятностей, которое мы хотим проверить по имеющимся данным. Гипотезы различают простые и сложные:
• простая гипотеза полностью задает распределение вероятностей;
• сложная гипотеза указывает не одно распределение, а некоторое множество распределений. Обычно это множество распределений, обладающих определенным свойством.
Статистические гипотезы подразделяются на нулевые и альтернативные.
Нулевая гипотеза - это гипотеза oб отсутствии различий, она обозначается как Но и называется нулевой потому, что содержит число 0: X1 ∙Х2 = 0, где X1 и Х2 - сопоставляемые значения признаков. Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий.
Альтернативная гипотеза - эта гипотеза о значимости различий. Она обозначается H1. Альтернативная гипотеза - это то, что мы хотим доказать, поэтому ее иногда называют экспериментальной гипотезой.
Бывают задачи, когда мы хотим доказать незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам.
Чаще всего требуется доказать значимость различий, ибо они более информативны для нас в поиске нового.
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
1.5. Статистические критерии
«Статистический критерий – это решающее правило, обеспечивающее надежное поведение, то есть принятие истинной и отклонение ложной гипотезы с высокой вероятностью» (Суходольский Г.В.). Статистические критерии обозначают также метод расчета определенного числа и само это число.
В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, в некоторых критериях придерживаются противоположного правила. Эти правила оговариваются в описании каждого критерия.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как n. В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице определяется, какому уровню статистической значимости различий соответствует данная эмпирическая величина.
В большинстве случаев, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в выборке (n) или от так называемого количества степеней свободы, которое обозначается как v.
Число степеней свободы. Число степеней свободы равно числу классов вариационного ряда минус число условий, при которых он был сформирован. К числу таких условий относятся: объем выборки, средние и дисперсии.
Если мы расклассифицировали наблюдения по классам какой-либо номинативной шкалы и подсчитали количество наблюдений в каждой ячейке классификации, то мы получаем так называемый частотный вариационный ряд. Единственное условие, которое соблюдается при его формировании - объем выборки n.
Допустим у нас три класса: "Умеет работать на ПК – умеет выполнять лишь определенные операции – не умеет работать".
Выборка состоит из 50 человек. Если в первом классе – 20 человек, во втором классе – 20 человек, то в третьем должны оказаться 10 человек. Мы ограничены только одним условием –объемом выборки. Мы не свободны в определении количества испытуемых в третьем классе, "свобода" простирается только на первые два класса
v=с-1=3-1=2
Аналогичным образом, если бы у нас была классификация из 10 разрядов или классов, то мы были бы свободны только в 9 и т.д.
Зная n и/или число степеней свободы, по специальным таблицам можно определить критические значения критерия и сопоставить с ними полученное эмпирическое значение.
Среди возможных статистических критериев выделяют: односторонние и двусторонние, параметрические и непараметрические, более и менее мощные.
Односторонние и двусторонние. Понятие одностороннего либо двустороннего критерия связано с формулировкой гипотез.
Если "нулевая" гипотеза формулируется о равенстве (Х1 = Х2), то для проверки используется двусторонний критерий. Если же "нулевая" гипотеза формулируется о неравенстве, то возможны три варианта:
1) если Х1 ≠ Х2, то используется двусторонний критерий;
2) если Х1 > Х2 или Х1 < Х2, то используется односторонний критерий.
Параметрические критерии – это некоторые функции от параметров совокупности, они служат для проверки гипотез об этих параметрах или для их оценивания. Параметрические критерии включают в формулу расчета параметры распределения, т.е. средние и дисперсии.
Непараметрические критерии – это некоторые функции от функций распределения или непосредственно от вариационного ряда наблюдавшихся значений изучаемого случайного явления. Они служат только для проверки гипотез о функциях распределения или рядах наблюдавшихся значений.
Непараметрические критерии не включают в формулу расчета параметров распределения и основанные на оперировании частотами или рангами.
И те, и другие критерии имеют свои преимущества и недостатки.
Параметрические критерии могут оказаться несколько более мощными, чем непараметрические, но только в том случае, если признак измерен по интервальной шкале и нормально распределен. Лишь с некоторой натяжкой мы можем считать данные, представленные в стандартизованных оценках, как интервальные. Кроме того, проверка распределения «на нормальность» требует достаточно сложных расчетов, результат которых заранее не известен.
Может оказаться, что распределение признака отличается от нормального, и нам так или иначе все равно придется обратиться к непараметрическим критериям.
Непараметрические критерии лишены всех этих ограничений и не требуют таких длительных и сложных расчетов. По сравнению с параметрическими критериями они ограничены лишь в одном - с их помощью невозможно оценить взаимодействие двух или более условий или факторов, влияющих на изменение признака.
Уровни статистической значимости.Уровень значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5% уровне значимости, или при р<0,05, то мы имеем ввиду, что вероятность того, что они недостоверны, составляет 0,05.
Если же мы указываем, что различия достоверны на 1% уровне значимости, или при р≤0,01, то имеем ввиду, что вероятность того, что они все-таки недостоверны равна 0,01.
Иначе, уровень значимости – это вероятность отклонения нулевой гипотезы, в то время как она верна.
Ошибка, состоящая в том, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой 1 рода.
Вероятность такой ошибки обычно обозначается как α. Поэтому правильнее указывать уровень значимости: α < 0,05 или α < 0,01.
Если вероятность ошибки – это α, то вероятность правильного решения равна: 1 – α. Чем меньше α, тем больше вероятность правильного решения.
В психологии принять считать низшим уровнем статистической значимости 5%-ный уровень, а достаточным 1%-ный. В таблицах критических значений обычно приводятся значения критериев, соответствующих уровням значимости р<0,05 и р<0,01 иногда для р<0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для значения критерия Фишера φ = 1,56 р = 0,06.
До тех пор. пока уровень значимости не достигнет р = 0.05, мы еще не имеем права отклонить нулевую гипотезу. Будем придерживаться следующего правила отклонения гипотезы об отсутствии различий (Н0) и принятии гипотезы о статистической достоверности различий (Н1).
Правило отклонения H0 и принятия H1
Если эмпирическое значение критерия равняется критическому значению, соответствующему р < 0,05 или превышает его, то Н0 отклоняется, но мы еще не можем определенно принять H1. Если эмпирическое значение критерия равняется критическому значению, соответствующему р < 0,01 или превышает его, то Н0 отклоняется и принимается H1.
Исключения: критерий знаков G, критерий Т Вилкоксона и критерий U Манна-Уитни. Для них устанавливаются обратные соотношения.
Для облегчения принятия решения можно вычерчивать "ось значимости".
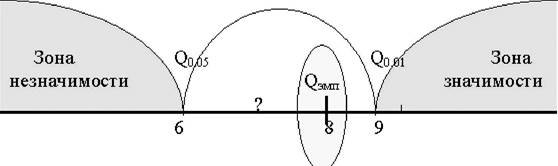
|
| Критические значения критерия обозначены как Q0,05 и Q0,01, эмпирическое значение критерия как Qэмп. Оно заключено в эллипс. |
| <== предыдущая лекция | | | следующая лекция ==> |
| Методы спортивного отбора | | | Обмен информацией осуществляется посредством сообщений. |
Дата добавления: 2016-10-17; просмотров: 3365;