Метод допустимих перетворень
Можливі такі спотворення зображення відносно еталону:
 1. Зміщення (центрування)
1. Зміщення (центрування)
2. Масштабування.
3. Поворот.
4. Деформація.
5. Пошкодження (шум)
Рис.3. Допустимі перетворення
Для суміщення зображень при наявності спотворень потрібно виконати відповідні допустимі перетворення зображення (однієї матриці відносно іншої) для знаходження максимального співпадання з еталоном (сума квадратів різниць координат відповідних точок зображень – мін.).
2.5.3. Просторово-частотний метод (Фур’є перетворення)
На основі кожного зображення отримується його спектр, а далі вже порівнюються спектри. Переваги – нечутливість до зміщення, повороту ....
2.6. Структурні методи (синтаксичний, лінгвістичний метод)
В структурних системах об’єкт описується як граф, вузлами якого є елементи вхідного об’єкта, а дугами – просторові відношення між ними. Такі системи звичайно працюють з векторними зображеннями. Наприклад, в такому представленні буква „Р” – це вертикальний відрізок і дуга.
Послідовність обробки зображень
1. Виконується сегментація зображення на складові частини (фрагменти) – відрізки. Виділяються елементарні елементи зображення (атоми), які складають алфавіт символів.
2. Після виділення атомарних елементів починається синтаксичне розпізнавання образів, визначається взаємне розташування елементів (зверху, знизу, сусідні елементи). Множина геометричних елементів створює словник мови. Множина правил – граматику мови.
3. Зображення представляється як послідовність (ланцюг) символів.
4. Розпізнавання образу полягає у порівнянні вхідного ланцюга образу з еталонним.
Класифікація формальних граматик за Хомським: контекстно-залежна і контекстно-вільна.
Структурний метод розпізнавання кривих за Фріменом (використовують одиничні вектори 1..8).
2.6.1. Квазітопологічний метод (структурний)
Топологія – це наука, яка розглядає властивості графів. Граф складається з точок (вершин) та з’єднуючих їх ребер (ліній). За допомогою графів можна усунути один з основних недоліків розпізнавання тексту – ускладнення у розпізнаванні деформованого тексту (рис. 4,5). Один з квазітопологічних алгоритмів:
1. Обхід літери виконується проти руху стрілки годинника по замкненому зовнішньому контуру, починаючи з верхньої правої точки, яка позначається кодом «1».
2. При обході літери позначається цифра коду, яка вказує загальну кількість ребер, що належить вершині графа. На рис. 5 вершини графа помічені літерами «а, б, в, г, д».
Згідно з цими правилами кодова комбінація літери «А» має вигляд «1, 3, 1, 3, 3, 1, 3». Цей код отриманий за умови обходу, починаючи з точки «а».
Недоліки цього методу: бруд, переміщення лінії, видалення/ додавання фрагменту утруднює якісне розпізнавання образу.
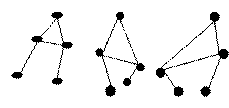
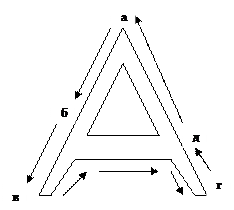
Рис.4. Графи літери «А» Рис.5. Визначення коду літери «А»
2.7. Розпізнавання у просторі ознак
Об’єкт представляється точкою у просторі, де осями координат є його n ознак. Звичайно використовують кількісні ознаки: діаметр, висота, ширина, площа, периметр (наприклад, геометричні ознаки мікроорганізмів), які утворюють алфавіт ознак. Отриманий n-мірний вектор порівнюється з еталонними, й вибирається найближчий з них. В якості міри близькості між об’єктами a i b використовують зважені евклідові відстані:
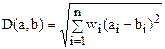 ,
,
де ai, bi – ознаки об’єктів, wi – вага ознаки.
2.7.1. Кластерний аналіз. Гіпотеза компактності
Всі дискримінанті методи спираються на гіпотезу компактності. Відповідно до цієї гіпотези класу відповідає компактна множина точок у деякому класі ознак. Термін „компактний” означає:
1) число граничних точок мале у порівнянні із загальним числом точок;
2) будь-які дві внутрішні точки можуть з’єднані плавною лінією так, щоб лінія проходила тільки через точки цієї множини
3) майже будь-яка внутрішня точка має у достатньо великому околі лише точки цієї множини.
Якщо класи об’єктів не перекриваються, то їх можна розділити лініями на області.
Рис.6. Поділ на класи
2.7.2. Метод потенціалів
Досліджуваний об’єкт представляється набором електричних зарядів, потенціал яких
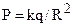 ,
,
де k – постійний коефіцієнт, q - величина заряду, R - відстань від точки до заряду.
Коли потенціал створюється кількома зарядами, то потенціал у будь-якій точці дорівнює сумі потенціалів всіх зарядів. Заряди можуть бути різних знаків – додатні і від’ємні.
Оскільки в попередній формулі є ділення на нуль при R=0, то використовується формула
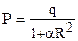 ,
,
де коефіцієнт α визначає швидкість зміни потенціалу.
В просторі ознак точки різних класів А і В створюють потенціал певного знаку, клас нової точки С визначається тим, який потенціал в точці С буде більший. В евклідовому просторі навколо об’єкту створюються рівні однакового потенціалу, які розходяться від об’єкту як хвилі. Такі хвилі описують тільки найсуттєвіші деталі зображення. Скелет, побудова скелету об’єкта (внутрішня хвиля), порівняння скелетів поточного образу і еталонів (напр. для символів)
2.7.3. Байєсівські методи розпізнавання
Байєсівські методи належать до імовірнісних.
Нехай існують класи K1 .. Km, які описується вектором ознак Y. З кожним класом пов’язана апріорна ймовірність P(Kj) появи об’єкта j-го класу (частота появи). Умовна ймовірність того, що класу Кі відповідають ознаки Yпозначається P(Y/Ki). Тоді можна визначити ймовірність того, що вектору ознак Yвідповідає клас Кі.
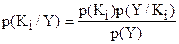 ,
,
де спільну для всіх класів величину p(Y) можна скоротити.
Наприклад, потрібно відрізнити стиглі яблука від недостиглих (2 класи: K1=„Стиглі” і K2=„Недостиглі”), m=2. Вектор ознак Y=(розмір /малий, великий /, колір /зелений, червоний/). Ймовірність попадання стиглих яблук більша: р(К1)=0,7; р(К2)=0,3.
Якщо яблука стиглі (К1): Y=(великий, червоний), то р(У, К1)=0,95;
Y=(малий, зелений), то р(У, К1)=0,05;
Якщо яблука не стиглі (К2): Y=(великий, червоний), то р(У, К2)=0,05;
Y=(малий, зелений), то р(У, К2)=0,95;
Якщо спостерігаються ознаки Y=(великий, червоний), то
p(K1/Y)=0,7*0,95 = 0,665; p(K2/Y)=0,3*0,05 = 0,015.
2.7.4. Метод опорного словника (розпізнавання у просторі ознак)
Припустимо, що ми розпізнаємо слово «ЛИСТ» з 4-х літер. Спочатку виділяється характерна сукупність ознак кожного символу цього слова:
ХЛ={х1, х2,…,хр}Л; ХИ={х1, х2,…,хр}И;
ХС={х1, х2,…,хр}С; ХТ={х1, х2,…,хр}Т.
Потім використовують вирішальні функції, які розроблені для кожного символу українського алфавіту з 32 літер. Вирішальні функції
gA(X1S), gБ(X2S),…,gЬ(X32S)
приймають максимальне цифрове значення, коли сукупність ознак ХjS відноситься до літери, для якої складена конкретна вирішальна функція. Наприклад, ga(XA) приймає максимальне значення, а ga(XЛ) приймає мінімальне значення.
Система РО перебирає всі слова з 4-х літер, які є у словнику, і для кожного з них розраховуємо суму з 4-х вирішальних функцій:
S1(АБАТ)=gA(XЛ)+ gБ(XИ)+ gA(XС)+ gТ(XТ); ..............
S50(ЯЩУР)=gЯ(XЛ)+ gЩ(XИ)+ gУ(XС)+ gР(XТ).
В результаті виділяють те слово в словнику, для якого отримана сума має найбільше значення.
Недоліком алгоритму є швидке зростання об’єму розрахунків із зростанням кількості літер.
2.7.5. Метод зондів (розпізнавання у просторі ознак)
Метод зондів використовується для розпізнавання цифр та літер, навіть написаних від руки та з деякими відхиленнями у розмірах та стилі написання. Вперше метод зондів був запропонований британським вченим Д.Даймондом у 1958р.
Розглянемо принцип використання зондів у припущенні, що наша система РО повинна розпізнавати образи лише чотирьох великих друкованих літер «ЛЕНА», написаних від руки.
Ці літери пишуться (з деякими обмеженнями у розмірах) електропровідними чорнилами на звичайному папері. Можна вважати, що кожний зонд 1, 2, 3 (рис. 8) складається з двох електродів, розділених ізоляційним проміжком. Кожному зображенню одного класу (одній літері) відповідає одна комбінація збуджених зондів. Зонд вважається збудженим, якщо він пересікає лінії літери. Реакцією зонду є «1» у разі збудження і «0» - в іншому випадку.
2.8. Системи оптичного розпізнавання, FineReader 4
OCR - Optical Character Recognition
Сьогодні вже існує рішення, що наближається до здібностей людини читати, яке використовує в своїй основі принципи розпізнавання живих систем - технологія цілісного цілеспрямованого адаптивного розпізнавання (Integral Purposeful Adaptive perception, IPA-технологія), реалізована в ABBYY FineReader (або „Фонтанне перетворення”).
Активність - це основна властивість роботи системи розпізнавання по аналогії з живим організмом. Розробники компанії ABBYY роблять спроби замінити традиційне розпізнавання окремих символів «розпізнаванням з розумінням». Тобто, комп'ютер сприймає не тільки те, що прямо спостерігається на зображенні, але і те, що від зображення очікується. Робота такої системи стала можлива завдяки принципам цілісності, цілеспрямованості і використанню контексту.
1. Принцип цілісності припускає, що кожен просторовий об'єкт складається з елементарних частин, зв'язаних між собою визначеними геометричними відношеннями. Наприклад, друкована сторінка складається з статей, стаття – з заголовка і колонок, колонка – з абзаців, абзаци – з рядків, рядки – з слів, слова – з букв.
2. Принцип цілеспрямованості стверджує, що процес ефективного розпізнавання повинен виконуватися шляхом висунення і подальшої перевірки гіпотез.
3. Принцип адаптивності свідчить, що для надійного розпізнавання різнорідних об'єктів система повинна мати здібність до самонавчання.
Відповідно до трьох основоположних принципів інженерами ABBYY був розроблений новий структурний алгоритм розпізнавання символів. Окрім нього в FineReader використовуються і інші широко відомі алгоритми: ознаковий, растровий (шаблонний) та ін.
2.9. Ідентифікація відвідувачів по особистому підпису
Для багатьох установ існує задача розробки систем по захисту інформації, доступу до неї і реєстрації користувачів. Серед систем персональної ідентифікації найбільшою перевагою володіє система ідентифікації особи по його підпису, який може бути введений користувачем в комп'ютер у реальному масштабі часу за допомогою звичного графічного планшета і електронного пера (digitizer with pen).
Введений таким чином підпис є стійкою комбінацією взаємозв'язаних символів і динамікою їх написання (розподіл швидкості, натиску і нахилу пера по довжині підпису і т. п.), характерну тільки для конкретного користувача і важковідтворювану іншим.
Метод ідентифікації користувача, що представляється, по його підпису припускає:
1) формування багатовимірного масиву точок, одержуваних в процесі написання (введення) підпису, з відповідними координатами (x,y), тиском пера (p), його нахилом (j ), швидкістю (v) в даній точці і т. п..;
2) складання математичного опису форми підпису у вигляді впорядкованого набору примітивів (кути і відрізки), одержуваних при кусково-лінійній апроксимації контуру підпису по точках максимальної зміни кривизни контуру;
3) алгоритм зіставлення одержаного опису зі всіма еталонними описами в банку даних полягає в перевірці зіставності груп примітивів на поточному і еталонному підписах і пошуку серед еталонів таких підписів, які дають максимальне число зіставлених груп примітивів;
4) нормалізацію зображення поточного підпису до вибраних еталонів, тобто обчислення параметрів зворотного перетворення (кут, масштаб, зсув) по зіставлених примітивах;
5) обчислення кількісної оцінки ступеня відповідності аналізованого підпису еталонам за формою написання символів і множини динамічних характеристик;
6) ухвалення рішення по ідентифікації користувача на основі інтегральної оцінки по всіх аналізованих ознаках.
Дата добавления: 2016-04-19; просмотров: 1009;