Процессорах (интегрированные)
__ На ЭВМ средней
Производительности
— На мини- и супермини- ЭВМ
На ПЭВМ
Рис. 3.6. Классификация экспертных систем
3.4.2. Нейронные сети
Искусственные нейронные сети представляют собой один из интереснейших с точки зрения информатики случаев систем, основанных на знаниях. Искусственные нейронные сети возникли из многочисленных попыток воспроизвести при помощи математики и компьютера абстрактную модель совместной работы клеток головного мозга.
|
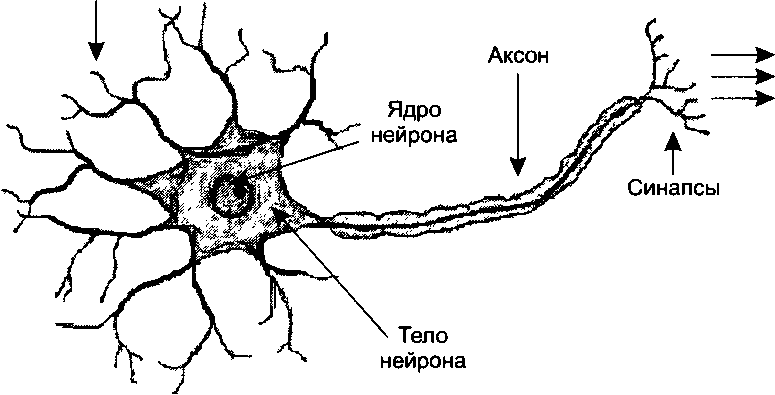
| Дендриты |
| Входные сигналы, |
| поступающие |
| от синапсов других нейронов |
| Рис. 3.7. Биологический нейрон |
|
| на дендриты других нейронов |
Нейрон, основная строительная единица биологического нервного вещества, представляет собой клетку, в которой множество входных сигналов обрабатывается по определенному алгоритму, и затем, как результат этой обработки, формируется выходной сигнал (рис. 3.7).
Выходные сигналы,
передаваемые
Абстрагируя принцип работы биологического нейрона, математики построили математическую модель, отражающую основные принципы работы этой клетки (рис. 3.8).
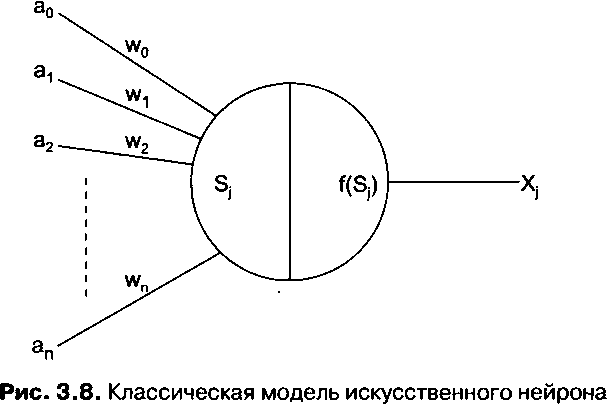
|
В этой модели сигналы, поступающие на входы а0...аю умножаются на весовые коэффициенты w0...wnj и на основе функции обработки J(Sj) вырабатывается выходной сигнал Xj. В простейшем случае входные сигналы, помноженные на весовые коэффициенты, суммируются, и, когда значение суммы становится больше определенного порога, генерируется выходной сигнал. В других случаях зависимость выходного сигнала от суммы входных может иметь более сложный характер, описываемый заданной математической функцией.
Физически один искусственный нейрон представляет собой простой микропроцессор с возможностью программирования функции J(Sj)f установки весовых коэффициентов и с небольшим объемом встроенной памяти. Для обработки знаний отдельный искусственный нейрон применен быть не может. Но когда множество искусственных нейронов соединяются между собой в искусственную нейронную сеть (подобно тому, как биологические нейроны соединены в мозгу человека), у них появляется возможность обрабатывать и накапливать знания. Знания в искусственной нейронной сети накапливаются в виде значений весовых коэффициентов.
Таким образом, можно сформулировать определение.

|
Исходя из этого определения, необходимыми элементами искусственной нейронной сети являются:
□ математическая модель;
□ искусственные нейроны (реализованные аппаратно или программно);
□ программно-топологическая реализация математической модели за счет задания соединений между нейронами и обрабатывающей (активационной) функции
ASj).
Искусственная нейронная сеть в общем случае характеризуется следующими параметрами:
□ Адаптивная обучаемость. В контексте искусственной нейронной сети обучаемость означает, что сеть может усваивать различные варианты поведения в зависимости от того, какие данные поступают на ее вход. Вместо того чтобы диктовать сети, как она должна реагировать на каждую порцию данных (как это было бы в случае обычного программирования), сеть сама находит сходства и различия в поступающих данных. По мере поступления новых данных обучение продолжается, и поведение сети изменяется.
□ Самоорганизация. По мере того как данные поступают на вход сети, сеть имеет возможность изменять весовые коэффициенты тех или иных соединений. Тем самым, по мере поступления новых данных, практически изменяется структура сети. Эффективность самоорганизации сети зависит от начальной структуры соединений и выбранного в качестве математической модели алгоритма обучения (тренинга).
□ Устойчивость к ошибкам. Искусственная нейронная сеть умеет выделять из потока данных важные свойства и усиливать их, при этом слабо реагируя на случайные, искаженные или совершенно новые данные (свойства). Таким образом данные, не несущие в себе повторяющихся закономерностей (другими словами, помехи), просто отбрасываются нейронной сетью, обеспечивая тем самым устойчивость к ошибкам.
□ Работа в режиме реального времени и параллельная обработка информации. Эти преимущества нейронных сетей проявляются только в промышленном исполнении (когда каждый нейрон действительно представляет собой отдельный процессор) и не могут быть получены при программной эмуляции нейронов.
Основными признаками для классификации искусственных нейронных сетей являются архитектура и связанный с ней алгоритм обучения. По этим признакам искусственные нейронные сети можно классифицировать так, как это показано на рис. 3.9.
В этой классификации можно отметить несколько моментов.
□ Обучение с учителем — класс искусственных нейронных сетей, для которого заранее известен диапазон выходных данных. В случае, когда после преобразования входных данных и получения выходных данных последние не укладываются в заранее заданные диапазон значений, нейронная сеть получает сигналы обратной связи и корректирует свою структуру с целью уменьшения ошибки.
Пример. При распознавании изображений оператор (человек или электронное устройство) сообщает нейронной сети, правильно или нет она распознала изображение.
□ Обучение без учителя — класс искусственных нейронных сетей, для которого диапазон выходных значений не задан и обучение сети проводится только на основании закономерностей, обнаруженных во входных сигналах.
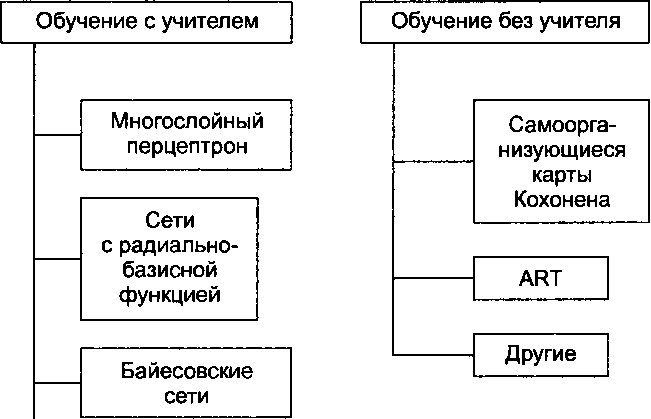 Другие
Рис. 3.9. Классификация нейронных сетей
Другие
Рис. 3.9. Классификация нейронных сетей
|
□ Многослойный перцептрон — искусственная нейронная сеть, состоящая из
О входного слоя нейронов, на которые поступают входные сигналы;
О выходного слоя нейронов, передающего выходные сигналы на интерфейс пользователя;
О скрытых слоев нейронов, расположенных между входным и выходным слоями;
| Искусственная нейронная сеть |
О механизма (или алгоритма) обратного распространения, обеспечивающего при наступлении ошибки (несовпадении выходного сигнала с шаблоном) последовательную корректировку всех весовых коэффициентов связей, начиная с ближнего к выходному скрытого слоя и заканчивая входным слоем, с целью устранения этой ошибки.
□ Сеть с радиально-базисной функцией — искусственная нейронная сеть, имеющая, кроме входного и выходного, один скрытый слой и использующая в качестве активационной функции нейронов скрытого слоя радиально-базисную функцию (РБФ), которая в общем виде выглядит так:
□ Байесовская сеть — искусственная нейронная сеть, использующая в качестве математической модели сеть Байеса, связывающую между собой множество переменных (весовых коэффициентов) и их вероятностных зависимостей (ак- тивационных функций).
□ Самоорганизующиеся карты Кохонена — искусственные нейронные сети, осуществляющие последовательное (по мере обучения) группирование сходных данных в плоской системе координат таким образом, что к завершению обучения узлы, содержащие сходные данные, располагаются геометрически в непосредственной близости друг от друга. Данный подход позволяет эффективно выделить главные данные, подавив случайные шумы и ошибки.
□ Сети на основе адаптивной теории резонанса (ART-сети) были созданы специально для решения задач классификации. В них заложено сразу два дихотомически противоположных принципа: во-первых, сеть должна самомодифицироваться в ответ на каждый входной сигнал; во-вторых, сеть должна сохранять знания, а значит, быть стабильной. Решение заключается в нахождении точки равновесия между требованиями пластичности и стабильности сети.
К достоинствам искусственных нейронных сетей можно отнести:
□ возможность решения задач, которые не решаются никакими другими методами;
□ самообучение;
□ получение результатов в режиме реального времени;
□ «креативность»;
□ создание новых знаний внутри сети в процессе переработки входных данных. Недостатки искусственных нейронных сетей:
□ сравнительная дороговизна аппаратной реализации;
□ трудность тиражирования накопленных знаний;
□ для больших сетей невозможность заранее даже приблизительно оценить время обучения сети.
Искусственные нейронные сети хорошо подходят для решения задач:
□ с большими массивами входных данных;
□ с неизвестным алгоритмом, но большим количеством конкретных примеров решения;
□ с большим количеством шумов;
□ с недостаточностью или, наоборот, избыточностью данных.
Искусственные нейронные сети могут эффективно решать задачи распознавания изображений, классификации, оптимизации или прогнозирования. Более конкретно такими задачами являются:
□ распознавание лиц, голосов, отпечатков пальцев;
□ анализ рентгенограмм;
□ обнаружение отклонений в ЭКГ;
□ обработка звуковых сигналов (разделение, идентификация, локализация, устранение шума, интерпретация);
□ обработка радарных сигналов (распознавание целей, идентификация и локализация источников);
□ проверка достоверности подписей;
□ оценка риска займов;
□ прогнозирование изменений экономических показателей и т. п.
3.4.3. Системы, основанные на прецедентах
Когда речь идет о системах, основанных на прецедентах, имеется в виду накопленный ранее опыт решения проблем, сходных с возникшей. В базе знаний системы хранятся не правила, а прецеденты. Прецедент состоит из двух важных составляющих:
□ хорошо сформулированного описания проблемы (или набора проблем);
□ описания решения этой проблемы.

|
Таким образом, система, основанная на прецедентах, наиболее полно соответствует понятию знаний организации. Она накапливает знания о методах, способах и путях решения часто встречающихся проблем и решения стандартных задач.
Обобщенная схема работы системы, основанной на прецедентах, показана на рис. 3.10.
Новый прецедент
| -а |
| Поиск 0 |
 База
прецедентов
База
прецедентов
|
| Пополнение базы Обучение |
| Нет |
| Правила адаптации Закрытый прецедент |
Найденный подобный прецедент
Требуется адаптация?
| Да I 1 | г |
| Адаптация и использование |
| Повторное использование |
Проблема решена
Рис. 3.10. Схема работы системы, основанной на прецедентах
Алгоритм работы предложенной схемы следующий:
1. На первом этапе возникает проблемная ситуация (техническая или производственная задача, требующая решения).
2. Заполняется диагностическая форма, то есть происходит описание ситуации по формальным признакам.
3. По набору формальных признаков производится поиск схожей или идентичной ситуации в базе знаний:
О если идентичная ситуация найдена, то алгоритм ее решения предлагается в качестве решения текущей проблемы;
О если найдена ситуация, отклоняющаяся по формальным признакам от идентичной ниже порогового уровня (который вычисляется как сумма формальных признаков, помноженная на весовые коэффициенты признаков), то исследуется возможность адаптации прецедента из базы знаний к текущему прецеденту с использованием правил базы знаний;
О если схожая ситуация не найдена или адаптация невозможна, к решению проблемы подключается эксперт в предметной области, после чего решение проблемы формализуется и новый прецедент вносится в базу знаний;
О если в процессе поиска находится несколько соответствий описанию входной ситуации, необходимо уточнить набор входных параметров, чтобы выявить наиболее подходящий прецедент.
В качестве достоинств систем, основанных на прецедентах, можно отметить:
□ сокращение трудоемкости приобретения новых знаний, поскольку описывать прецеденты проще, чем программировать правила;
□ обучение системы происходит на основе добавления новых прецедентов, а не изменения или добавления новых правил.
Недостатки систем, основанных на прецедентах:
□ необходимость строго отслеживать правильность оформления прецедентов, в противном случае может произойти «засорение» базы знаний;
□ необходимость разработки методов поиска, однозначно идентифицирующих подходящие прецеденты.
Наиболее часто системы, основанные на прецедентах, используются в тех областях, для которых характерны повторяющиеся проблемные ситуации:
□ службы технической поддержки, сервисные подразделения;
□ диагностика в медицинских учреждениях;
□ организация юридической помощи (особенно в странах, где действует прецедентное законодательство);
□ контрольные органы;
□ системы обеспечения качества и т. д.
В общем случае рекомендуется применять системы, основанные на прецедентах, когда
□ трудно произвести детальную декомпозицию ситуации с целью выработать правила ее решения, то есть тогда, когда не может быть применена экспертная система, основанная на правилах;
□ трудно понять и описать суть возникающих проблем, но легко накопить примеры их разрешения.
3.4.4. Системы, построенные на генетических алгоритмах
Под алгоритмом обычно понимают более или менее сложную последовательность действий, которые необходимо выполнить для решения текущей проблемы или задачи. При этом подразумевается, что данная последовательность является статической, то есть формируется до начала решения задачи и остается неизменной в ходе решения. Статичность алгоритма накладывает ограничения на поиски путей решения.
Генетический алгоритм — это одна из моделей машинного самообучения, основанная на абстрагировании моделей биологической эволюции.
Так же как и в биологической эволюции, для применения генетического алгоритма внутри компьютера программным путем создаются популяции особей, представленные хромосомами.
При реализации генетического алгоритма в процессе используются следующие составляющие:
□ генетическое представление потенциального решения проблемы;
□ способ создания начальной популяции потенциального решения;
□ эволюционная функция, которая играет роль среды обитания, сортируя решения согласно их адекватности;
□ генетические операторы, которые изменяют сочетания генов потомства;
□ значения различных параметров, которые использует генетический алгоритм. Эволюция решений при использовании генетического алгоритма базируется
на трех основных процессах:
□ Воспроизведение. На базе родительских шаблонов создается новое поколение кода, которое имеет более высокий адаптационный рейтинг, то есть в большей мере соответствует решению проблемы.
□ Скрещивание. Строки кода в случайном порядке разбиваются пополам и создаются новые строки путем обмена половинками старых строк. Этот процесс имитирует биологический процесс, происходящий при создании хромосом потомства из хромосом родителей.
□ Мутация. В случайном порядке изменяется один символ (одна цифра) в исходной строке без воспроизведения или перекрещивания.
Процесс применения генетического алгоритма является циклическим и выполняется до тех пор, пока не находится приемлемое решение проблемы:
1. Вычисляется уровень адаптации всех членов популяции.
2. Над каждым членом популяции выполняются операции воспроизведения, генерации и мутации.
3. Старая популяция уничтожается.
Генетические алгоритмы применяют для решения сложных задач с большим количеством данных и параметров, которым должно соответствовать решение:
□ составление расписаний;
□ решение логистических задач;
□ создание сложных многослойных топологий (например, проектирование топологии микросхем) и т. д.
3.4.5. Интеллектуальные агенты
Существует множество рутинных процессов, не поддающихся строгой алгоритмизации. При достаточно точной формулировке конечной цели или задачи процесс ее решения может потребовать от исполнителя определенной гибкости и адаптивности. Речь идет о таких процессах, как длительный поиск в больших массивах информации, расположенных в динамически изменяющейся системе (например, в Интернете), уборка квартиры или очистка участка улицы от снега, то есть работа, которую приходится выполнять человеку, но которую желательно перепоручить автомату.
Для выполнения такого рода работ были созданы интеллектуальные агенты.
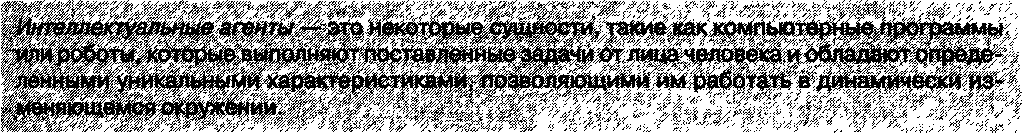
|
Для того чтобы классифицироваться как интеллектуальный агент, сущность должна обладать следующей функциональностью:
□ воспринимать свое окружение;
□ понимать конечную цель или назначение;
□ взаимодействовать с окружением;
□ реагировать на изменения в окружении;
□ проявлять признаки интеллекта, то есть уметь принимать решение и, возможно, обучаться на основе приобретенного опыта;
□ принимать автономные решения, то есть, обладая знанием конечной цели или предназначения, самостоятельно решать, какие действия нужно выполнить для достижения цели.
Общая архитектура интеллектуального агента представлена на рис. 3.11.
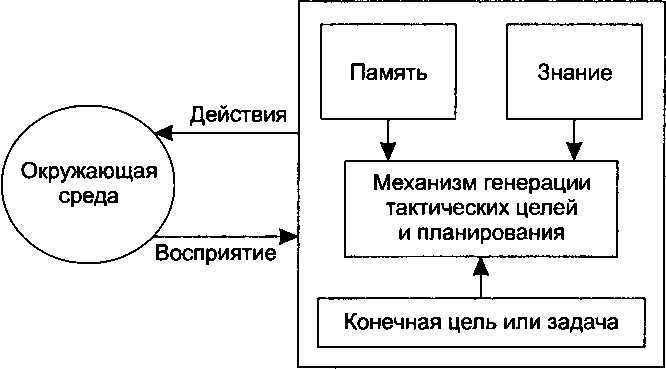 Рис. 3.11. Общая архитектура интеллектуального агента
Рис. 3.11. Общая архитектура интеллектуального агента
|
Интеллектуальные агенты все чаще применяются в самых разных областях деятельности: в поисковых и промышленных роботах, в беспилотных летательных аппаратах, в исследовательских роботах, работающих на дне океана, и т. д.
3.4.6. Системы добычи данных
Базы данных в их классическом понимании, а также большие хранилища данных вне баз данных (например, лог-файлы крупных веб-серверов) могут быть источником информации, которая в явном виде в них не отображена. Например, анализируя лог-файлы популярного образовательного интернет-портала, можно сделать вывод об успешности информатизации школ в том или ином регионе страны.
Под добычей данных (выявлением знаний) понимают автоматическое извлечение скрытых (присутствующих в неявной форме) данных из наборов данных. Добычей данных занимаются специализированные системы. Скрытые данные, добываемые при помощи инструментов добычи данных, могут служить основой для создания баз знаний экспертных систем различного типа. Сами инструменты добычи данных, в свою очередь, зачастую являются инструментами, основанными на знаниях. В зависимости от выбранной модели добычи данных, в качестве инструментов анализа и выявления скрытых данных (знаний) могут быть использованы:
□ искусственные нейронные сети;
□ деревья решений;
□ генетические алгоритмы;
□ индукционные алгоритмы.
Источниками данных для выявления знаний могут служить любые массивы накопленных данных, например:
□ медицинские и анкетные данные от государственной переписи населения до базы данных персонала и клиентов крупной фирмы;
□ сохраненные данные видео- и фотонаблюдения;
□ данные спутниковой съемки;
□ данные на цифровых носителях;
□ текстовые отчеты и записки;
□ данные Всемирной паутины (несмотря на свою неструктурированную и гетерогенную природу, Интернет сосредотачивает в себе самый большой объем данных, который когда-либо существовал).
Для выявления знаний используют два основных типа моделей:
□ описательная модель выявляет и описывает общие свойства и закономерности в существующих данных;
□ прогнозирующая модель пытается предсказать тенденции в той или иной области, основываясь на добытых знаниях.
Функциональность систем добычи данных может включать в себя следующие компоненты:
□ Информационные характеристики объединяют в себе общие особенности объектов какого-либо класса.
□ Дифференцирование данных. Продуктом дифференцирования данных является набор правил, описывающих разницу основных особенностей объектов целевого и контрастного классов. Например, чтобы лучше организовывать рекламные компании, полезно увидеть, чем отличаются клиенты, арендующие большие площади, от клиентов, арендующих малые площади.
□ Анализ связности данных служит для извлечения сведений о данных, которые часто встречаются вместе.
□ Классификационный анализ обеспечивает разделение данных на классы по некоторым заранее известным характеристикам. Для этого обычно применяется нейронная сеть с учителем, когда в качестве выходного шаблона задаются требуемые характеристики класса.
□ Предсказание данных. На базе шаблонов, уже имеющихся в наборе данных, можно предсказать вероятность появления данных. Это может пригодиться для предсказания поведения потребителей на основе их прошлого поведения.
□ Кластеризация обеспечивает разделение данных на классы с заранее неизвестными параметрами, характеристики которых извлекаются из самих данных. При кластеризации основания для классификации ищутся в самих данных. Для кластеризации применяются нейронные сети без учителя, такие как самоорганизующиеся карты Кохонена.
□ Анализ выбросов позволяет отбирать данные, которые не подпадают ни иод один шаблон или класс. Иногда эти данные являются шумом, но иногда могут представлять собой важные знания.
□ Эволюционный анализ служит для моделирования изменения наборов данных во времени.
□ Анализ отклонений позволяет сравнить эталонные и реальные значения данных и выявить причины, по которым данные отклоняются от эталона.
Системы добычи данных можно классифицировать по
□ типу источника данных (распределенные данные, временные ряды, данные мультимедиа, текстовые источники);
□ используемой модели данных (реляционные данные, объектно-ориентированные базы данных, хранилища данных);
□ способу добычи данных (дифференциация, классификация, кластеризация, и т. д.);
□ технологии реализации (нейронные сети, генетические алгоритмы, статистические методы, и т. д.).
Инженерия знаний
Хотя термины «инженерия знаний» и «управление знаниями» часто используют как взаимозаменяемые, на самом деле необходимо провести демаркационную линию между двумя этими понятиями. Управление знаниями в большей мере связано с функцией руководства, администрирования и контроля. Менеджер знаний чаще всего является управляющим информационного подразделения в организации, отвечая за определение потребности организации в знаниях. Основной вопрос, на который отвечает менеджмент знаний: «зачем?».
В менеджмент знаний входят следующие функции:
□ определение потребности организации в знаниях;
□ определение роли знаний в структуре управления работой организации;
□ определение типа и объема знаний, необходимых различным подразделениям организации;
□ выявление приоритетов важности знаний и времени, когда они необходимы. В отличие от менеджмента, инженерия знаний подразумевает ответ на вопрос
«как?».
Инженер по знаниям обеспечивает технологию решения задач и обеспечения потребностей, которые формулирует менеджер по знаниям. Инженерия знаний выполняет следующие функции:
□ обеспечивает технологический процесс сбора и хранения знаний;
□ разрабатывает методологии и технологии извлечения знаний из хранилищ;
□ отвечает за форму представления знаний конечному пользователю;
□ поддерживает сбор, хранение, модификацию и целостность знаний.
Таким образом, если менеджер по знаниям может быть своего рода информационным управляющим, не имеющим прямого отношения к компьютерным технологиям, то инженер по знаниям обязательно должен быть компьютерным специалистом, способным решать сложные задачи разработки и сопровождения информационных систем и информационных технологий самого широкого спектра. Одновременно инженер по знаниям должен обладать глубокими знаниями психологии общения и развитыми социальными навыками, позволяющими обеспечить получение знаний от экспертов.
3.5.1. Получение знаний
Получение (извлечение, добыча, выявление, приобретение) знаний является главным процессом в инженерии знаний. Без этого процесса все остальные технологии становятся малоприменимыми.
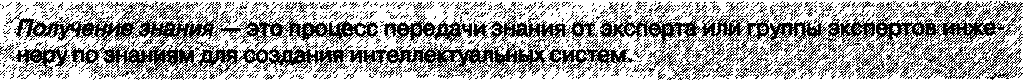
|
Поскольку экспертная система или любая другая система, основанная на знаниях, должна содержать в себе в первую очередь знания экспертов-людей той или иной предметной области, процесс получения знаний в первую очередь предполагает вовлечение экспертов в диалог с инженером по знаниям. Хотя эксперты обычно с удовольствием говорят на темы, непосредственно затрагивающие близкую им предметную область, это не значит, что процесс получения знаний является легким.
Кроме получения знаний от экспертов, знания можно получать из других источников: технической литературы или литературы по предметной области, анкетных опросов, документации аналогичных систем, основанных на знаниях. Однако стержнем системы, основанной на знаниях, являются знания экспертов, связанных с конкретной задачей в конкретной организации. Для получения знаний от экспертов широко используются различные способы собеседования (интервью). Выделяют четыре главных типа интервью:
□ Неструктурированное интервью. Такого рода интервью представляет собой собеседование без четкого плана. В этом случае инженер получает базовые представления о предметной области. Задача инженера в процессе проведения интервью — мягко, но настойчиво возвращать эксперта к обсуждению предметной области.
□ Структурированное интервью. Этот тип интервью имеет четкий план и структуру и используется для получения подробных сведений о предметной области. Поскольку структурированные интервью обычно проводятся после нескольких неструктурированных, инженер по знаниям обычно уже ориентируется в предметной области. К этому интервью у него подготовлен список вопросов, на которые он хочет получить ответы. В основном интервью сосредотачивается на том, почему были предприняты те или иные действия, для того чтобы понять, как эксперт принимает решение. Структурированное интервью проходит в три этапа:
1)инженер по знаниям излагает предстоящие темы и согласовывает их с экспертом. Задача этого этапа — мотивировать эксперта;
2) инженер по знаниям задает эксперту вопросы, эксперт отвечает;
3)инженер по знаниям еще раз проверяет, правильно ли он понял ответы, все ли вопросы были заданы, на все ли вопросы были получены правильные ответы. После чего он излагает свои выводы эксперту и добивается его одобрения.
□ Случай из прошлого. В этом интервью инженер по знаниям просит эксперта вспомнить конкретный случай из прошлой практики, когда эксперт применял свои навыки в предметной области. Берется локальная ситуация, возможно, небольшая по масштабам, и разбирается очень подробно. Этот тип интервью направлен в первую очередь на то, чтобы понять, как именно происходит мыслительный процесс у эксперта, на основании каких неявных мыслей принимается решение, и требует особых психологических навыков от инженера по знаниям. Цель интервью — постараться перевести в эксплицитные как можно больше тацитных (неявных) знаний эксперта.
□ Мысли вслух. В этом типе интервью так же, как и в случае из прошлого, разбирается конкретная ситуация (из реальной жизни или смоделированная), но эксперта просят все рассуждения делать явным образом, вслух. Цель интервью такая же, как и в предыдущем — выявление неявных знаний.
Кроме четырех базовых типов интервью в работе инженера по знаниям могут применяться и другие типы бесед с экспертами.
□ Учебное интервью. Эксперта просят подготовить презентацию для инженера по знаниям, чтобы ознакомить его со специфической областью.
□ Двадцать вопросов. Инженер по знаниям подготавливает опросный лист из вопросов, на которые надо ответить только «да» или «нет».
□ Пусковое интервью. Инженер по знаниям готовит материал, который может резко повысить активность эксперта. Такая подготовка делается на основе предыдущих бесед (например, отмечается, что эксперт был очень эмоционален в обсуждении какого-то вопроса). Этот материал включается в интервью и все внимание сосредоточивается на нем.
□ Интервью обратного обучения. Инженер по знаниям делает попытку обучить эксперта в обсуждаемой предметной области. Эксперт обеспечивает обратную связь.
□ Репертуарная решетка. Объекты в предметной области помещаются в заголовки столбцов, характеристики объектов — в названия строк, затем на пересечении строк и столбцов ставятся крестики (методология работы с репертуарной решеткой достаточно объемна и в данной книге не приводится).
Есть несколько советов, которые могут помочь в ходе проведения интервью.
Во-первых, избегайте двусмысленности. Всякого рода сравнения типа «более быстрый», «лучше», «больше» требуют уточнения: больше чего? лучше по сравнению с чем?
Во-вторых, надо принимать во внимание, что эксперт в своих рассуждениях часто опускает ключевые части процесса. Для того чтобы инженер по знаниям понял его рассуждения, эксперт часто опускает ключевые, но сложные для понимания технические детали.
В-третьих, то, что эксперт считает интуицией, часто является частью прошлого опыта, который может быть переведен в явную форму. Однако эксперт может настаивать на том, что он просто «почувствовал», что именно такое решение будет правильным.
Вопросы, которые полезно задавать в процессе интервью:
1. Можете ли вы дать мне краткий обзор выбранной темы?
2. Можете описать последний случай, с которым вы столкнулись на практике?
3. Какие факты или гипотезы приходят вам в голову, когда вы думаете о проблеме?
4. Какие вещи вы предпочитаете узнать перед тем, как начать размышлять о проблеме?
5. Расскажите, как именно вы к этому пришли?
6. И что вы делаете затем?
7. Как это связано с ...?
8. Как (почему, когда, зачем) вы делаете это?
9. Вы можете описать другими словами, что вы подразумеваете под...?
В завершение интервью крайне важно сделать краткий обзор полученной информации и оповестить эксперта о возможности или необходимости дальнейших интервью.
3.5.2. Жизненный цикл и методология
При проектировании и разработке систем, основанных на знаниях, стандартную методологию разработки информационных систем трудно применить в полном объеме. Специфика систем, основанных на знаниях, требует применения особых подходов и инструментов.
В стандартной методологии жизненный цикл разработки информационных систем обычно составляет 6 этапов, объединенных в процессе разработки моделями водопада или спирали:
1. Анализ (сбор требований).
2. Дизайн (моделирование).
3. Реализация (программирование).
4. Тестирование (испытание).
5. Развертывание (установка).
6. Поддержка (обслуживание).
При попытке применить эту методологию к созданию систем, основанных на знаниях, инженер по знаниям может столкнуться со следующими трудностями:
□ Проблемы спецификации требований. На этапе сбора требований еще не существует точной информации о том, какие знания будут содержаться в системе и как именно они будут обрабатываться. Поскольку модель водопада полностью построена на подробной спецификации требований при анализе, ее реализация оказывается невозможной.
□ Проблемы макетирования. Циклический процесс разработки, который начинается с создания макета и заканчивается разработкой полноценной системы, казалось бы, больше соответствует системам, основанным на знаниях. Однако этот процесс также затруднен: требования к выходным знаниям, к процессу принятия решений, расплывчатые на начальных этапах, должны конкретизироваться от цикла к циклу. Но по мере выявления неявных знаний у экспертов эти требования обычно претерпевают разительные изменения. По этой причине зачастую каждый цикл представляет собой не доработку существующего макета, а создание нового, при этом количество циклов и сроки выполнения работ невозможно предсказать даже приблизительно.
Такого рода затруднения требуют применения новых подходов и новых методологий проектирования при создании систем, основанных на знаниях.
Архитектура общего планшета подразумевает разделение одной большой системы, основанной на знаниях, на ряд связанных подсистем и спецификацию однотипного интерфейса между ними. Таким образом, сложная задача создания большой системы разбивается на ряд подзадач, объем работ и время выполнения которых можно с достаточной степенью достоверности оценить.
Название архитектуры произошло от способа проектирования, когда несколько человек усаживаются за один планшет (или доску) и совместно рисуют на ней. При этом каждый хорошо видит часть работы, которую выполняют другие.
Архитектура планшета подходит не для всех проектов. Для того чтобы проект можно было разрабатывать, используя эту архитектуру, он должен допускать возможность декомпозиции на ряд связанных, но в достаточной мере изолированных подзадач.
Пример. Создание экспертной системы строительства дома на участке.
Такого рода экспертная система легко разбивается на ряд подсистем: организация садового участка, кухни, гаража, спальни, комнат общего пользования и интегрирующей системы знаний.
Все включенные экспертные системы могут разрабатываться независимо друг от друга, иметь независимые базы знаний и модули представления знаний при наличии однотипного интерфейса с интегрирующей системой.
Кроме методологии общего планшета при разработке систем, основанных на знаниях, применяются следующие методологии:
□ Метод решения проблем основывается на накоплении и создании библиотеки последовательности действий, необходимых для решения проблемы, и набора знаний, позволяющего эти действия совершить. Достоинство метода — возможность многократного использования. Недостаток — необходимость создания библиотеки знаний и методов.
□ Методология моделирования получения знаний сочетает в себе черты методологии архитектуры планшета (деление проблемы на составные части) и метода решения проблем (накопления методов и знаний).
Вопросы для самопроверки
1. Как вы понимаете термин «управление знаниями»?
2. Какие процессы включаются в управление знаниями?
3. Из каких этапов состоит жизненный цикл управления знаниями?
4. Чем отличаются друг от друга понятия «данные», «информация» и «знания»?
5. Как развивались информационные системы?
6. Какие способы классификации знаний вы знаете?
7. Какие модели представления знаний вам известны?
8. Приведите пример продукционной модели представления знаний.
9. Дайте определение семантической сети.
10. Что такое «фрейм»? Что такое «слот»?
11. Перечислите признаки интеллектуального поведения.
12. Какие типы систем, основанных на знаниях, вам известны?
13. Дайте определение экспертной системы.
14. Из каких основных элементов состоит экспертная система?
15. Каковы достоинства и недостатки экспертных систем?
16. В чем суть методологии построения баз данных?
17. Что такое «искусственная нейронная сеть»?
18. Перечислите характеристики нейронной сети?
19. Какие типы нейронных сетей вам известны?
20. Каков алгоритм работы системы, основанной на прецедентах?
21. В каком виде знание представлено в искусственной нейронной сети? В экспертной системе? В системе, основанной на прецедентах?
22. Что такое «генетический алгоритм» и для чего он применяется?
23. Что такое интеллектуальный агент?
24. Что может быть источниками данных в процессе добычи данных?
25. На основе каких функций производится добыча данных?
26. В чем различие инженерии знаний и управления знаниями?
27. Что такое «получение знаний»? Какую роль этот процесс играет в инженерии знаний?
28. Перечислите четыре основных типа интервью.
29. Почему стандартная методология разработки информационных систем часто не подходит для инженерии знаний?
30. Какие специфические методологии применяются в инженерии знаний?
Литература
1. Башмаков А. И., Башмаков И. А. Интеллектуальные информационные технологии. M.: Издательство МГТУ им. Баумана, 2005.
2. Гаврилова Т. A1 Хорошевский В. Ф. Базы знаний интеллектуальных систем. СПб.: Питер, 2000.
3. Джанетто Kapeny Уилер Энн. Управление знаниями. M.: Добрая книга, 2005.
4. Емельянова Н. 3, Партыка Т. JI., Попов И. И. Основы построения автоматизированных информационных систем. M.: ФОРУМ-ИФРА-М, 2007.
Глава 4 Логические основы
информатики
4.1. Представление о высказываниях и логических операциях
4.2. Алгебра логики
4.3. Построение коммутационных схем на основе алгебры логики
Алгебра логики (алгебра высказываний) и основы математической логики играют важную роль в информатике. Математическая логика присутствует в различных разделах информатики: в виде двоичной логики, на которой основана работа цифровых компьютеров; в виде специальной алгебры логики, лежащей в основе математической модели реляционных баз данных; в виде правил, определяющих функционирование алгоритмов и программ, работу интеллектуальных и экспертных систем. Таким образом, логика для информатики является фундаментальным предметом, изучение которого дает ключ к множеству других разделов.
Дата добавления: 2016-04-14; просмотров: 1877;