Генетическая грамматика
После установления химического строения и пространственной структуры ДНК оставалось еще множество вопросов, основной из которых заключался в том, как же ДНК кодирует белки, то есть, что представляет из себя генетический код этой молекулы, какую «грамматику» она использует? На это в первую очередь и были направлены дальнейшие усилия исследователей.
Итак, установлено, что «буквами» в ДНКовом тексте служат нуклеотиды — элементарные звенья полимерной молекулы ДНК. В ДНК всего 4 нуклеотида (А, Т, Г, Ц). Следовательно, если сравнить каждый из этих нуклеотидов с отдельной буквой, то алфавит ДНКового текста содержит всего 4 «буквы». Как же из этих «букв» формируются «слова» и «предложения»?
Белковые молекулы всех существующих на земле организмов построены всего из 20 аминокислот. Сразу после создания модели ДНК стало ясно, что существует некий код, переводящий четырехбуквенный ДНКовый текст в двадцатибуквенный аминокислотный текст. Элементарные расчеты говорили о том, что число возможных сочетаний, в которых четыре нуклеотида могут быть по-разному расположены в «тексте», достигает астрономических значений. Так, молекула ДНК, состоящая, к примеру, всего из 100 пар нуклеотидов, может теоретически кодировать 4100 различных белковых «текстов». Какова же ситуация на самом деле?
Одним из первых в этом пытался разобраться русский физик Г. Гамов, эмигрировавший в то время в Америку. Наслушавшись многочисленных разговоров о ДНК и узнав, что она содержит — как и карты — всего четыре «масти», Гамов решил «разложить пасьянс» с целью понять устройство генетического кода. Ему сразу стало ясно, что код не может быть «двоичным», то есть одну аминокислоту в белке должна кодировать не двойка нуклеотидов — «букв», а как минимум тройка. Дело в том, что сочетание из 4 по 2 дает всего 16 комбинаций, а этого недостаточно для кодирования всех 20 аминокислот. Следовательно, рассуждал Гамов, код должен быть по крайней мере трехбуквенным, то есть каждую аминокислоту должна кодировать тройка «букв» в любых сочетаниях. На этом он и остановился, поскольку далее возникало множество вопросов. В частности, такой: число сочетаний из 4 по 3 равно 64, а аминокислот всего 20. Зачем же такая избыточность в трехбуквенном коде?
В то время уже существовал хорошо известный путь, который, в частности, был проделан в свое время французом Жаном Шампольоном при дешифровке иероглифов древнего Египта. В качестве основного подспорья для решения стоящей перед ним задачи он использовал базальтовую плиту, которую обнаружили во время военной компании Наполеона в Египет и которая получила название Розеттский камень. На плите одновременно присутствовали две надписи: одна была иероглифическая, а другая — сделанная греческими буквами на греческом языке. К счастью, и язык, и письмо древних греков были в то время уже хорошо известны ученым. В результате сравнение двух текстов Розеттского камня привело к расшифровке египетской иероглифики. Этим путем и двинулись ученые при расшифровке генетического кода. Надо было сравнить два текста: текст, записанный в ДНК, с текстом, записанным в белке. Однако первоначально ученые не умели «читать» ДНК, а одного известного в то время белкового текста было недостаточно. Пришлось искусственно синтезировать разнообразные короткие фрагменты РНК и синтезировать на них в искусственных системах фрагменты белка. Весной 1961 года в Москве на Международном биохимическом конгрессе М. Ниренберг сообщил, что ему удалось «прочесть» первое «слово» в ДНКовом тексте. Это была тройка букв — ААА (в РНК, соответственно, УУУ), то есть три аденина, стоящие друг за другом, — которая кодирует аминокислоту фенилаланин в белке. Так было положено начало расшифровке генетического кода.
Такой путь в конечном итоге вскоре привел к полной расшифровке генетического кода. Подтвердилось предположение Гамова, что код триплетный: одной аминокислоте в белках соответствует последовательность из 3 нуклеотидов в ДНК и РНК. Такие кодирующие тройки нуклеотидов — «слова» — получили название кодонов.
Напомним, что еще Гамов столкнулся с парадоксом: из четырех нуклеотидов может быть построено 64 разных кодонов, а для построения белков используется только 20 различных аминокислот. Решение этого парадокса оказалось в следующем. Большинство аминокислот может кодироваться несколькими кодонами. После выяснения этого обстоятельства генетический код назвали вырожденным.
В таблице 1 приведены кодоны, но не в самой ДНК, а в РНК-посреднике (матричной РНК, или мРНК), образующейся на ДНК, и соответствующие им аминокислоты в белках.
Кроме того, как видно из таблицы, реально для кодирования используются не все возможные кодоны. Три из этих «лишних» кодонов выполняют функцию стоп-сигналов, обеспечивая прекращение синтеза белковой цепи.
Если внимательно посмотреть на таблицу 1, то видно, что вырожденность генетического кода носит не совсем случайный характер. Хотя код триплетный, основную нагрузку несут первые два нуклеотида в каждом кодоне. Чаще всего в разных кодонах, кодирующих одну и ту же аминокислоту, отличается лишь третий нуклеотид.
Таблица 1. Генетический словарь. Указаны аминокислоты, встречающиеся в белках, и соответствующие им кодоны в комплементарной ДНК матричной РНК
Генетический код первоначально был расшифрован у таких простых организмов, как фаги и бактерии. В дальнейшем оказалось, что он универсален (за очень редким исключением) для геномов всех существующих ныне живых организмах (от бактерий до человека). Небольшие отличия, о которых мы поговорим далее, были выявлены при сравнении ядерного и митохондриального геномов.
Итак, как в привычном нам тексте книги, вся информация записана в ДНК последовательностью расположения четырех составляющих ее «букв» — нуклеотидов. Таким образом, ДНКовый текст написан с помощью А, Т, Ц, Г-алфавита. При этом только текст одной из двух цепей ДНК обычно кодирующий, а другая цепь, как правило, некодирующая. Хотя известно, что в каждом правиле есть исключения. Если читатель попробует написать этими четырьмя буквами какие-нибудь русские слова, то у него ничего не получится. «Словом» в ДНКовом тексте, условно говоря, служит определенное сочетание трех нуклеотидов, которому соответствует конкретная аминокислота в белке, являющемся также полимером. Таким образом, в клетке четырьмя буквами записано два десятка «слов» (аминокислот — составных частей белков). И, наконец, как «предложение» в ДНКовом тексте можно рассматривать полный набор триплетов, кодирующих определенный белок, то есть ген. Таким образом, генетический алфавит состоит всего из 4 букв, а генетический словарь из 20 слов. В этой связи вспомним, что даже словарь Эллочки-людоедки из романа И. Ильфа и Е. Петрова «Двенадцать стульев» состоял из 30 слов, а «Словарь языка произведений А. С. Пушкина» насчитывает примерно 20 тыс. слов.
Существует строгая закономерность: чем длиннее код (чем больше в нем знаков), тем короче тексты. Огромный по размерам код представляют собой, например, китайские иероглифы. В результате этого иероглифические тексты существенно более кратки по сравнению с другими системами письма, в том числе и нашей. Однако для создания генетического кода природа выбрала всего 4 «буквы». Такой код предполагает наличие длинных текстов, что и реализовалось природой в виде создания гигантских молекул ДНК. При написании полного «текста» генома человека потребовалось около 3,2 млрд. «букв». Для сравнения: в священной книге Бытия, написанной на древнееврейском языке, содержится всего 78100 букв.
Размножение ДНК (репликация)
Важно то, что структура ДНК, открытая Уотсоном и Криком, многое прояснила относительно разных механизмов функционирования этой молекулы в клетке. ДНК не только кодирует генетическую информацию, но и самовоспроизводится (удваивается) при каждом клеточном делении. И вскоре уже было экспериментально установлено, что одновременно с делением клетки ДНК снимает с самой себя точные копии в процессе удвоения, или репликации. Во время клеточного деления слабые связи между двумя цепями двойной спирали ДНК разрушаются, в результате чего нити разделяются. Затем на каждой из них строится вторая «дочерняя» (комплементарная) цепь ДНК. В результате этого молекула ДНК удваивается, как и клетка, и в обеих клетках оказывается по одной полной копии ДНК. Копии должны быть полностью идентичными, чтобы сохранить всю генетическую информацию.
Процесс репликации играет ключевую роль в сохранении одной и той же генетической информации в разных клетках, образующихся при их делении. В общем виде художественно он изображен на рис. 5. Однако реальные механизмы репликации довольно сложны, и до настоящего времени еще не все тонкие детали этого процесса известны, особенно применительно к геномам высших животных организмов, включая человека.
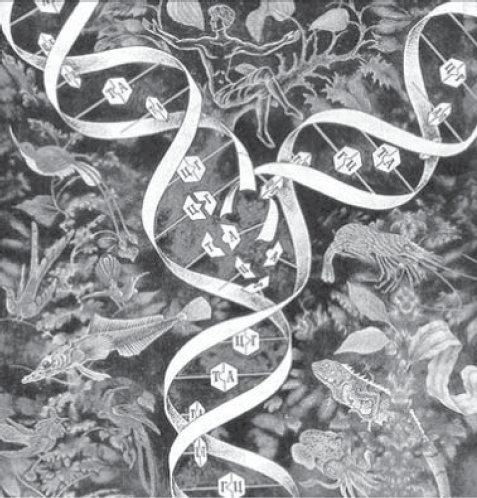
Рис. 5. Схема репликации ДНК
В общем виде этот процесс выглядит следующим образом. В каждой хромосоме ДНК удваивается не с начала до конца, а отдельными кусками (репликонами). Средний размер репликона составляет около 30 мкм. Тем самым в составе генома человека должно встречаться более 50 000 репликонов, участков ДНК, которые синтезируются в ядре как независимые единицы. И это имеет свой глубокий смысл. Если бы каждая из молекул ДНК удваивалась как один репликон от начала до конца молекулы, то при скорости синтеза 0,5 мкм в минуту (а она именно такова у человека) удвоение первой хромосомы, имеющей длину ДНК около 7 см, занимало бы 140 000 минут, или около трех месяцев. На самом деле благодаря полирепликонному строению молекул ДНК весь процесс занимает всего 7–12 часов. Отдельные относительно короткие репликоны соединяются друг с другом, обеспечивая этим процесс воспроизведения целой молекулы ДНК.
Перезапись генетического текста и перевод в белковый текст (транскрипция и трансляция)
В клетке ДНК служит в качестве матрицы, на которой первоначально происходит синтез разных РНК. Процесс перезаписи генетической информации из ДНК в РНКовый текст получил название транскрипция. Этот процесс, как и репликация ДНК, осуществляется в ядрах клеток. Первоначально на генах, кодирующих белки, образуются РНК-предшественники, которые после ряда модификаций превращаются в так называемые матричные РНК (мРНК). Они-то непосредственно и служат матрицей для синтеза белков, то есть их кодируют. Установлено, что мРНК служат не только носителями ДНКовой информации, но и переносчиками этой информации из ядра в цитоплазму клетки. Только там мРНК может играть роль матрицы для синтеза белковых молекул (этот процесс назван трансляцией). В цитоплазме на специфических «машинах» — рибосомах — осуществляется при трансляции мРНК синтез молекулы белка, т. е. происходит перевод информации с четырехбуквенного языка мРНК на двадцатибуквенный язык белка. Схематически этот процесс изображен на рис. 6.
В середине 60-х годов был сформулирован основной постулат (центральная догма) новой науки — молекулярной биологии, который первоначально выглядел следующим образом:
ДНК → РНК → белок.
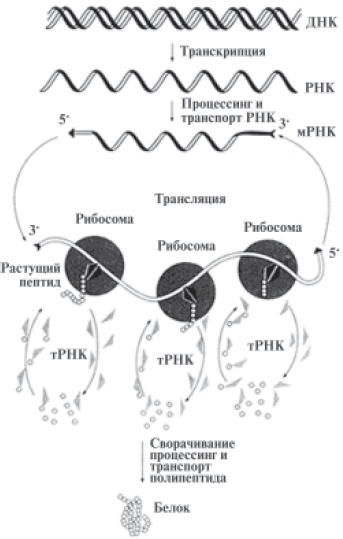
Рис. 6. Процесс трансляции мРНК на рибосомах с образованием белка
Рибосома играет роль «машины», читающей генетическую информацию, записанную в мРНК. Это молекулярная машина, построенная по единой схеме у всех организмов (включая человека) с небольшими вариациями. Она состоит из двух рибонуклеопротеидных (состоящих из РНК и белков) субчастиц: малой и большой. На рибосоме происходит взаимодействие мРНК с транспортными РНК (тРНК), несущими по одной аминокислоте каждая. Белок синтезируется путем образования связей между последовательно доставляемыми тРНК аминокислотами. Этим процессом «руководит» сама рибосома.
Позднее этот постулат был уточнен, и теперь он выглядит как

Сделанное дополнение вызвано обнаружением в 1970 году такого явления, как обратная транскрипция. Выяснилось, что у некоторых вирусов, генетический аппарат которых представлен РНК, а не ДНК, как у других живых организмов, имеется специальный фермент, который позволяет осуществлять такой обратный процесс, как синтез ДНК на РНК. Этот фермент получил название обратная транскриптаза, или ревертаза.
Казалось бы, теперь уже все стало ясно и однозначно и более ничего не может измениться. Но, как писал Марк Твен: «Из жизненного опыта следует извлекать только полезное и ничего больше, — иначе мы уподобимся кошке, присевшей на горячую печку. Она никогда больше не сядет на горячую печку — и хорошо сделает, но она никогда больше не сядет и на холодную». Ряд открытий последних лет продолжает вносить уточнения в казавшуюся незыблемой центральную догму молекулярной биологии.
Во-первых, выяснилось, что центральная догма молекулярной биологии постулирует лишь путь передачи генетической информации от нуклеиновых кислот к белкам и, следовательно, к конкретным свойствам и признакам живого организма. Однако исследование механизмов реализации этого пути на протяжении нескольких десятилетий, последовавших за формулировкой центральной догмы, вскрыло гораздо более разнообразные функции РНК, помимо известных ранее.
Во-вторых, согласно первоначальной догме, все носители инфекционных болезней должны иметь генетический материал — ДНК или РНК. Оказалось, что и здесь есть исключения. В 1997 году Нобелевская премия была вручена Стэнли Прузинеру за открытие белковых инфекционных частиц, вызывающих такое заболевание, как, например, болезни «коровьего бешенства», или почесухи. Эти частицы были названы прионами. Проникая в клетку-хозяина, прионы «навязывают» свою болезнетворную конформацию (измененную пространственную структуру) нормальным белкам-аналогам, содержащимся в клетках. При этом ни РНК, ни ДНК никак не участвуют в развитии заболевания. Иными словами, при прионовых заболеваниях информация передается не от одной нуклеиновой кислоты к другой нуклеиновой кислоте, а от белка к белку, что в исходном варианте центральной догмы не предусматривалось.
Однако все эти дополнения в «центральную догму» молекулярной биологии не повлияли принципиально на ее общую закономерность. В центре всего и вся стоял и стоит ген. Сегодня он перестал быть чем-то таинственным, стал реальным химическим веществом, появилась возможность судить о нем так же, как и о других химических соединениях живых организмов, изучать с помощью доступных генетикам и биохимикам методов. Стало понятным, что такое генетический код и как реализуется в клетке та информация, которая записана в ДНКовом тексте. В результате этого в 1953 году родилась молекулярная генетика — раздел науки, который занялся детальным изучением процессов работы ДНК в клетке на молекулярном уровне.
Расшифровка химической и пространственной структуры ДНК — носителя генетической информации — оценена во всем мире как одно из наиболее выдающихся открытий XX века. Геном стоит в центре всех биологических проблем, всех свойств и способностей человека, всего разнообразия человека. Теперь это уже аксиома. Как говорил Козьма Прутков: «Многие люди подобны колбасам: чем их начинят, то и носят в себе». Так вот, мы «начинены» ДНК, носим ее в себе, а она-то, главным образом, и определяет многое в нас.
Дата добавления: 2016-02-20; просмотров: 805;