Базы данных. Модели данных
База данных (БД) – это совокупность взаимосвязанных, характеризующаяся возможностью использования для большого количества приложений, возможностью быстрого получения и модификации необходимой информации, минимальной избыточностью информации, независимостью прикладных программ, общим управляемым способом поиска
Возможность применения баз данных для многих прикладных программ пользователя упрощает реализацию комплексных запросов, снижает избыточность хранимых данных и повышает эффективность использования информационной технологии. Основное свойство баз данных — независимость данных и использующих их программ. Независимость данных подразумевает, что изменение данных не приводит к изменению прикладных программ и наоборот.
Ядром любой базы данных является модель данных. Модель данных – это совокупность структур данных и операций их обработки.
Модели баз данных базируются на современном подходе к обработке информации, состоящем в том, что структуры данных обладают относительной устойчивостью. Структура информационной базы, отображающая в структурированном виде информационную модель предметной области, позволяет сформировать логические записи, их элементы и взаимосвязи между ними. Взаимосвязи могут быть типизированы по следующим основным видам:
- "один к одному", когда одна запись может быть связана
только с одной записью;
- "один ко многим", когда одна запись взаимосвязана со многими другими;
- "многие ко многим", когда одна и та же запись может входить в отношения со многими другими записями в различных вариантах.
Применение того или иного вида взаимосвязей определило три основные модели баз данных: иерархическую, сетевую и реляционную.
Для пояснения логической структуры основных моделей баз
данных рассмотрим такую простую задачу: необходимо разработать логическую структуру БД для хранения данных о трех
поставщиках: П1, П2, П3, которые могут поставлять товары Т1,
Т2, Т3 в следующих комбинациях: поставщик П1 — все три вида
товаров, поставщик П2 — товары Т1 и Т3, поставщик П3 — товары Т2 и Т3.
Иерархическая модель представляется в виде древовидного
графа, в котором объекты выделяются по уровням соподчиненности (иерархии) объектов (рис. 5.1.)
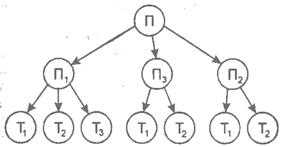
Рис. 5.1. Иерархическая модель БД
На верхнем, первом уровне находится информация об объекте "поставщики" (П), на втором — о конкретных поставщиках П1, П2, П3, на нижнем, третьем, уровне — о товарах, которые могут поставлять конкретные поставщики. В иерархической модели должно соблюдаться правило: каждый порожденный узел не может иметь больше одного порождающего узла (только одна входящая стрелка); в структуре может быть только один непорожденный узел (без входящей стрелки) — корень. Узлы, не имеющие входных стрелок, носят название листьев. Узел интегрируется как запись. Для поиска необходимой записи нужно двигаться от корня к листьям, т.е. сверху вниз, что значительно упрощает доступ.
Достоинство иерархической модели данных состоит в том, что она позволяет описать их структуру, как на логическом, так и на физическом уровне. Недостатками данной модели являются жесткая фиксированность взаимосвязей между элементами данных, вследствие чего любые изменения связей требуют изменения структуры, а также жесткая зависимость физической и логической организации данных. Быстрота доступа в иерархической модели достигнута за счет потери информационной гибкости (за один проход по дереву невозможно получить информацию о том, какие поставщики поставляют, например, товар Ti).
В иерархической модели используется вид связи между элементами данных "один ко многим". Если применяется взаимосвязь вида "многие ко многим", то приходят к сетевой модели данных.
Сетевая модель базы данных для поставленной задачи представлена в виде диаграммы связей (рис. 5.2.). На диаграмме указаны независимые (основные) типы данных П1, П2, П3, т.е. информация о поставщиках, и зависимые — информация о товарах T1, T2, и Т3. В сетевой модели допустимы любые виды связей между записями и отсутствует ограничение на число обратных связей. Но должно соблюдаться одно правило: связь включает основную и зависимую записи
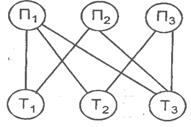
Рис. 5.2. Сетевая модель базы данных
Достоинство сетевой модели БД — большая информационная гибкость по сравнению с иерархической моделью. Однако сохраняется общий для обеих моделей недостаток — достаточно жесткая структура, что препятствует развитию информационной базы системы управления. При необходимости частой реорганизации информационной базы (например, при использовании настраиваемых базовых информационных технологий) применяют наиболее совершенную модель БД — реляционную, в которой отсутствуют различия между объектами и взаимосвязями.
В реляционной модели базы данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями. Отношения обладают следующими свойствами: каждый элемент таблицы представляет собой один элемент данных (повторяющиеся группы отсутствуют); элементы столб  ца имеют одинаковую природу, и столбцам однозначно присвоены имена; в таблице нет двух одинаковых строк; строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
ца имеют одинаковую природу, и столбцам однозначно присвоены имена; в таблице нет двух одинаковых строк; строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
Преимуществами реляционной модели БД являются простота логической модели (таблицы привычны для представления информации); гибкость системы защиты (для каждого отношения может быть задана правомерность доступа); независимость данных; возможность построения простого языка манипулирования данными с помощью математически строгой теории реляционной алгебры (алгебры отношений).
Для приведенной выше задачи о поставщиках и товарах логическая структура реляционной БД будет содержать три таблицы (отношения): R1, R2, R3, состоящие соответственно из записей о поставках, о товарах и о поставках товаров поставщиками (рис. 5.3.)

|

|

|
Рис. 5.3. Реляционная модель БД
СУБД и ее функции
Системой управления базами данных (СУБД) называют программную систему, предназначенную для создания на ЭВМ общей базы данных, используемой для решения множества задач. Подобные системы служат для поддержания базы данных в актуальном состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным в рамках
предоставленных пользователям полномочий.
СУБД предназначена для централизованного управления базой данных в интересах всех работающих в этой системе.
По степени универсальности различают два класса СУБД:
- системы общего назначения;
- специализированные системы.
СУБД общего назначения не ориентированы на какую-либо предметную область или на информационные потребности какой-либо группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной базой данных. Использование СУБД общего назначения в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии баз данных, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Этим СУБД присущи развитые функциональные возможности.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
СУБД общего назначения — это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией базы данных информационной системы.
Используемые в настоящее время СУБД обладают средствами обеспечения целостности данных и надежной безопасности, что дает возможность разработчикам гарантировать большую безопасность данных при меньших затратах сил на низкоуровневое программирование. Продукты, функционирующие в среде WINDOWS, выгодно отличаются удобством пользовательского интерфейса и встроенными средствами повышения производительности.
Производительность СУБД оценивается:
- временем выполнения запросов;
- скоростью поиска информации в неиндексированных полях;
- временем выполнения операций импортирования базы данных из других форматов;
- скоростью создания индексов и выполнения таких массовых операций, как обновление, вставка, удаление данных;
- максимальным числом параллельных обращений к данным в многопользовательском режиме;
- временем генерации отчета.
На производительность СУБД оказывают влияние два фактора:
- СУБД, которые следят за соблюдением целостности данных, несут дополнительную нагрузку, которую не испытывают другие программы;
- производительность собственных прикладных программ сильно зависит от правильного проектирования и построения базы данных.
Дата добавления: 2016-02-09; просмотров: 4206;