Аналитические информационные системы.
К середине 80-х годов в развитых странах мира завершился первый этап оснащения бизнеса и органов государственного управления средствами вычислительной техники. Военные ведомства и крупные корпорации установили распределенные вычислительные системы, состоявшие из мощных мэйн-фреймов и информационные системы на их основе. С появлением персональных компьютеров ЭВМ стали разрабатываться информационные системы для множества средних и мелких фирм и организаций. Исторически первые системы предназначались для оперативной обработки данных - они обслуживали информационные потребности управления организаций, архивы, телефонные сети, системы резервирования билетов, сбора метеоданных и др. Такие системы получили название сначала систем операционной обработки, а затем систем оперативной обработки транзакций или OLTP. Использование мощных средств вычислительной техники позволило накапливать большие объемы информации: документы, сведения о банковских операциях, клиентах, предоставленных услугах. Однако период хранения этой информации был относительно невелик - сохранялись только данные за текущий календарный период.
Вскоре возникло понимание, что сбор данных - не самоцель и накопленные информационные массивы могут быть полезны. Системы операционной обработки способны выполнять тривиальный анализ данных - вычислять максимальные, минимальные и средние значения атрибутов. Но из накопленных данных можно почерпнуть намного более глубокие сведения как о функционировании организации, которая обслуживается информационной системой, так и о сфере ее деятельности, В информационных массивах можно попытаться выявить скрытые, на первый взгляд, закономерности и вывести из них правила, которым подчиняется предметная область информационной системы. Впоследствии эти правила можно использовать для стратегического планирования, принятия решений и прогнозирования их последствий.
Осознание пользы накапливаемой информации и возможности использовать ее для решения аналитических задач привело к появлению нового класса вычислительных систем - систем поддержки принятия решений (СППР), ориентированных на аналитическую обработку данных.
Под системой поддержки принятия решений (СППР) понимают человеко-машинный вычислительный комплекс, ориентированный на анализ данных и обеспечивающий получение информации, необходимой для разработки решений в сфере управления.
Следует заметить, что аналитические системы существовали и ранее, но именно возможность обработки больших объемов накапливаемых данных дала новый толчок их развитию и приходу на рынок. Также этому способствовали снижение стоимости высокопроизводительных компьютеров и расходов на хранение больших объемов данных, развитие математических методов обработки информации. К числу задач, которые традиционно решают системы поддержки принятия решений, относятся: оценка альтернатив решений, прогнозирование, классификация, кластеризация, выявление ассоциаций и др.
Для получения интересующей их информации лица, принимающие решения (ЛПР), или аналитики обращаются к СППР с запросами. Эти запросы в большинстве случаев более сложные, чем те, которые применяются в системах операционной обработки данных. Например, в ОLТР-системе банка запрос может сводиться к получению сведений о сумме на счету конкретного клиента. В аналитической системе запрос может быть таким: "Найти среднее значение промежутка времени между выставлением счета и оплатой его клиентом в текущем и прошедшем году отдельно для разных групп клиентов."
В большинстве случаев сложный аналитический запрос невозможно сформулировать в терминах языка SQL, поэтому для получения информации приходится применять специализированные языки, ориентированные на аналитическую обработку данных. К их числу можно отнести, например, язык Ехргеss 4GL фирмы Огас1е. Также для выполнения аналитических запросов могут быть использованы приложения, написанные специально для решения тех или иных аналитических задач.
Для того чтобы можно было извлекать полезную информацию из данных, они должны быть организованы особым, отличным от принятого в ОLTР-системах образом. Связано это со следующими факторами.
Во-первых, для выполнения аналитических запросов необходима обработка больших информационных массивов. Чем выше степень нормализации базы данных, и чем больше в ней таблиц, тем медленнее выполняется анализ. Происходит это прежде всего потому, что увеличивается число операций соединения отношений. В системах обработки транзакций нормализация таблиц БД позволяет устранить избыточность данных, уменьшив тем самым объем действий, необходимых при обновлении информации. Поэтому в нормализованных БД нет необходимости менять одни и те же значения в различных отношениях. В аналитических системах данные практически не обновляются - в системе производится лишь их накопление и чтение. Поэтому проблема нормализации БД в них не столь актуальна, как в системах обработки транзакций.
Во-вторых, выполнение некоторых аналитических запросов, например, анализ тенденций и прогнозирование, требует хронологической упорядоченности данных. Реляционная модель не предполагает существования порядка записей в таблице.
В-третьих, данные, используемые для целей анализа, как правило, отличаются от данных систем обработки транзакций. При обслуживании аналитических запросов чаще используются не детальные, а обобщенные (агрегированные) данные. Так, например, для прогнозирования объема продаж сети универмагов будет излишним иметь информацию о каждой сделанной покупке, достаточно знать значение прогнозируемой величины за несколько предыдущих лет.
Принципы, лежащие в основе систем поддержки принятия решений, не позволяют эффективно обрабатывать транзакции, поэтому данные, применяемые для анализа, стали выделять в отдельные базы данных. Впоследствии эти базы данных стали называть хранилищами данных (ХД) или информационными хранилищами. В литературе используется также англоязычный термин "Data Warehouse".
2 Концепция информационного хранилища
Отцом концепции использования хранилищ данных в аналитических системах считают Билла Инмона (Bill Inmon), технического директора компании "Призм Сольюшнс" (Prism Solution). В начале 90-х годов он опубликовал ряд работ, которые стали отправной точкой для последующих исследований в области аналитических систем. Большое влияние на разработку концепции хранилищ данных оказала также американская корпорация "Аи Би Эм" (IВМ).
Концепция хранилищ данных - это концепция подготовки данных для последующего анализа. Она предполагает выполнение следующих положений:
1) интеграции и согласования данных из различных источников: традиционных систем операционной обработки данных, информации из внутренних и внешних по отношению к организации электронных архивов;
2) разделения наборов данных, используемых системами обработки транзакций и системами поддержки принятия решений.
В работе "Создание хранилища данных" ("Building the Data Warehouse") Билл Инмон определил хранилище данных как "предметно-ориентированный, интегрированный, неизменяемый и поддерживающий хронологию набор данных, предназначенный для обеспечения принятия управленческих решений". Позднее мы вернемся к этому определению и подробнее рассмотрим черты ХД, указанные Инмоном.
Рассмотрим схему функционирования СППР, основанной на концепции хранилища данных, проведя аналогии с процессами производства и реализации промышленной продукции.
Технология ИХ напоминает модель функционирования промышленного предприятия. Деятельность любой компании, независимо от того, что выпускается, можно условно разделить на три составляющие: производство (цеха), хранение (склад) и реализация товара (магазин). Похожая схема действует и в информационном бизнесе, если рассматривать его как способ производства и доставки нужной информации пользователю-клиенту.
Исходные данные для анализа производятся системами операционной обработки (бухгалтерских, приема и обработки заявок клиентов, финансовых и т.д.), поступают из электронных архивов и от поставщиков информации, например, онлайновых информационных агентств. Эти источники слабо связаны между собой, поэтому и данные, которые они предоставляют, имеют различную структуру и форматы представления. Эти данные мало пригодны для использования рядовыми пользователями. Данные с различных информационных конвееров отправляются на склад для хранения, расфасовки и последующей доставки пользователям. Роль склада и играют информационные хранилища.
Необходимо произвести согласование данных разных источников, чтобы ими было удобно оперировать при анализе. Это подразумевает приведение их к единому формату, устранение дублирующихся и некорректных значений.
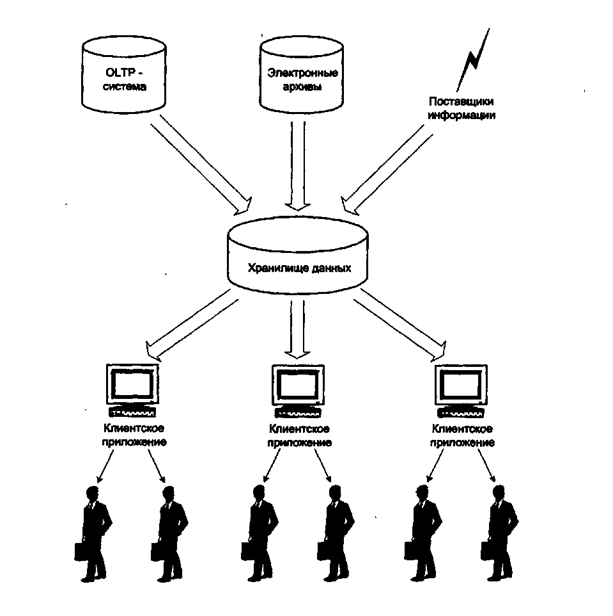
Рис. 1. Упрощенная логическая схема аналитической системы
Подготовленные данные загружаются в хранилище.
И наконец, реализацией товара, т.е. доставкой информации конечному пользователю занимаются специальные информационные системы, которые обеспечивают пользователям простой доступ к данным за счет удобных средств генерации запросов и анализа результатов. Если в супермаркете стоимость товара повышается за счет красивой упаковки, то и в информационных системах ценность информационного товара увеличивается благодаря использованию разнообразных методов анализа и статистической обработки. Такие системы имеют удобный и интуитивно понятный интерфейс.
Сформировался новый класс систем поддержки принятия решений – OLAP (Online Analisis Prosessing).
Под OLAP системойпринято понимать СППР, основанную на концепции хранилищ данных и обеспечивающую малое время выполнения аналитических запросов.
Пользователи-аналитики осуществляют доступ к нему через клиентские приложения. Эти приложения могут осуществлять трансляцию запросов потребителей информации либо производить аналитическую обработку данных хранилища. В отличие от систем операционной обработки данных в СППР, использующих концепцию ХД, критерии поиска и состав выдаваемой в виде отчета информации не фиксируются при ее разработке, пользователи оперируют в основном заранее не регламентированными запросами.
Использование концепции хранилища данных в системе поддержки принятия решений преследует следующие цели:
1) своевременное обеспечение аналитиков всей информацией, необходимой
для выработки решений;
2) создание единой модели данных организации;
3) создание интегрированного источника данных, предоставляющего удобный доступ к разнородной информации и гарантирующего получение одинаковых ответов на одинаковые запросы из различных аналитических подсистем (единый "источник истины").
3 Свойства хранилищ данных
Вернемся к определению, данному Б. Инмоном, чтобы подробнее рассмот-. реть свойства, присущие хранилищам данных. Инмон рассматривает четыре основных свойства хранилищ данных.
1) Ориентация на предметную область. Хранилище должно разрабатываться с учетом специфики предметной области, а не приложений, оперирующих данными. Структура хранилища должна отражать представления аналитика об информации, с которой ему приходится работать. Например, если система операционной обработки поставщика товаров работает с понятиями "сделка" и "заявка", то хранилище должно использовать понятия "клиенты", "товары" и "производители".
2) Интегрированность. Информация загружается в хранилище из приложений, созданных разными разработчиками. Необходимо объединить данные этих приложений, приведя их к единому синтаксическому и семантическому виду. Например, в таблицах БД, полученных из разных источников, могут встречаться атрибуты, которые определены на разных доменах, но обозначают те же понятия. Например, месяц года может быть задан полным наименованием (январь, февраль и т.д.), сокращенным наименованием (янв, фев и т.д.) и номером (1,2 и т.д.). В процессе загрузки хранилища требуется преобразовать эти атрибуты к единому представлению. Важно также провести проверку поступающих данных на целостность и непротиворечивость. Характерный для информационных хранилищ прием - хранение агрегированных данных. Аналитика редко интересует информация о конкретных днях и часах, ему более важны данные о месяцах, кварталах и даже годах. Чтобы при выполнении аналити-ческих запросов избежать выполнения операций группирования, данные должны обобщаться (агрегироваться) при загрузке хранилища. Объем накопленных данных должен быть достаточным для решения аналитических задач с требуемым качеством. Используемые в настоящее время ХД содержат информацию, накопленную за годы и даже десятилетия.
3) Неизменяемость данных (Стабильность). Важное отличие аналитических систем от систем операционной обработки данных состоит в том, что данные после загрузки в них остаются неизменными, внесения каких-либо изменений, кроме добавления записей, не предполагается. Именно поэтому для СППР не столь актуальны средства для обеспечения отката транзакций, борьбы с взаимными блокировками процессов - разработчики подобных систем сосредоточивают основные усилия на достижении высокой скорости доступа к данным. Важное условие неизменности информации в хранилище - использование для его реализации надежного оборудования, которое обеспечивает защиту от сбоев.
4) Поддержка хронологии. Для выполнения большинства аналитических запросов необходим анализ тенденций развития явлений или характера изменения значений переменных во времени. Учет хронологии достигается введением ключевых атрибутов типа "ДАТА" и/или "ВРЕМЯ" в структуры хранилища данных. Время выполнения аналитических запросов можно уменьшить, если физически упорядочить записи по времени, то есть расположить записи по возрастанию значений атрибута "ДАТА/ВРЕМЯ".
Нельзя не заметить, что данные и принципы их хранения в СППР и системах операционной обработки различаются. Основные отличия перечислены в таблице 1.
Таблица 3.1. Свойства данных в СППР и системах операционной обработки (ОLТР)
| Свойство ОLТР СППР Назначение данных Оперативный поиск, Аналитическая обработка, несложные виды прогнозирование, обработки моделирование Уровень агрегации Детализированные Агрегированные данных Период хранения От нескольких месяцев От нескольких лет данных до одного года до десятков лет до одного года до десятков лет Частота обновления Высокая частота, Малая частота, обновление обновление большими порциями маленькими порциями |
К числу основных задач, которые требуется решать при создании ХД, относятся:
1) выбор оптимальной структуры хранения данных с точки зрения обеспечения приемлемого времени отклика на аналитические запросы и требуемого объема памяти;
2) первоначальное заполнение и последующее пополнение хранилища данными;
3) обеспечение удобства доступа пользователей к данным.
Рассмотрим пути решения этих задач более детально.
4 Модели данных, используемые для построения хранилищ
Задачи, решаемые ОLТР и аналитическими системами, существенно различаются, поэтому их БД тоже построены на разных принципах. Критерием эффективности для систем операционной обработки данных служит число транзакций, которое они способны выполнить в единицу времени. Для аналитических систем важнее скорость выполнения сложных запросов и прозрачность структуры хранения информации для пользователей. Важная особенность СППР на основе ХД состоит в том, что загрузка данных выполняется сравнительно редко, но большими порциями (до нескольких миллионов записей за один раз), поэтому в таких системах обычно не предусматриваются развитые средства обеспечения целостности, восстановления, устранения взаимных блокировок. Это не только существенно облегчает и упрощает сами средства реализации, но и значительно снижает внутренние накладные расходы при доступе к информации и, следовательно, повышает производительность анализа.
В настоящее время существуют два в чем-то конкурирующих, а в чем-то взаимодополняющих друг друга подхода к построению хранилищ данных: подход, основанный на использовании многомерной модели БД (Multidimensional ОLАР - МОLАР), и подход, использующий реляционную модель БД (Relational ОLАР - RОLАР).
Прежде чем рассказать о каждом из них, попытаемся разобраться, какие данные могут находиться в хранилище, и как они могут быть представлены. Чаще всего там содержатся сведения о значении некоторых параметров, характеризующих предметную область в определенные моменты или за определенные промежутки времени. Пусть, например, требуется создать хранилище, накапливающее информацию об изменении социально-экономической обстановки в Рос9ии. Эта обстановка характеризуется многими параметрами, в числе которых: объем промышленного производства, индекс потребительских цен и др. Госкомстат России собирает их значения для различных субъектов Российской Федерации помесячно, поквартально или за год.
В хранилище должны попадать факты вида:
Название параметра в субъекте Российской Федерации в момент времени был равен {значение}.
Например, индекс потребительских цен в городе Москве в декабре 2004 года был равен 101%. В рассматриваемом примере каждое значение связано с точкой в трехмерном пространстве (N, S, Т) с измерениями: N-название параметра; S - субъект федерации; Т- момент времени. Число возможных параметров, субъектов РФ, а также рассматриваемых моментов времени конечно, поэтому все возможные значения можно представить в виде гиперкуба (см. рис.3).
В этом гиперкубе каждое значение находится в строго определенной ячейке, что значительно упрощает обращение к ней.
Представленный пример, конечно, упрощен, но он позволяет понять, что такое многомерный взгляд на данные; В реальной задаче число измерений может быть больше трех. Представление данных в виде гиперкуба более наглядно, чем совокупность нормализованных таблиц, оно понятно не только администратору БД, но и рядовым сотрудникам. .Это дает им дополнительные возможности построения аналитических запросов к системе, использующей хранилище данных. Кроме того, использование многомерной модели данных позволяет резко уменьшить время поиска в ХД, обеспечивая выполнение аналитических запросов в реальном времени.
Гиперкуб может быть реализован в рамках реляционной модели или существовать как отдельная БД специальной многомерной структуры. В зависимости от этого и принято различать реляционный (RОLАР) и многомерный (МОLАР) подходы к построению ХД.
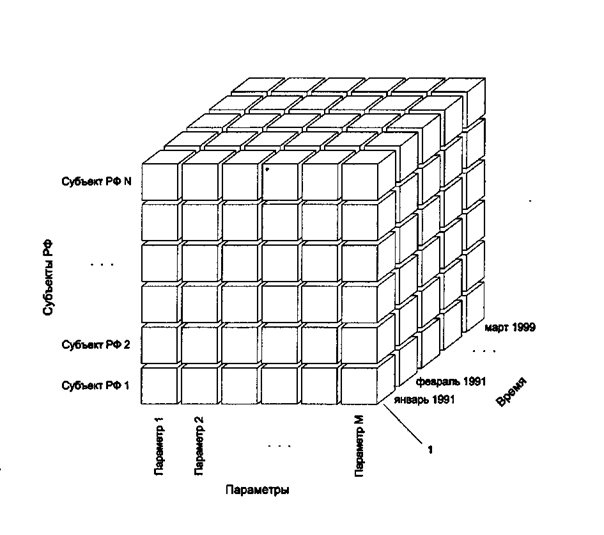
Рис. 3. Представление данных в виде гиперкуба: 1 - значение "Параметра М" для "Субъекта РФ 1" в январе 1991 года
4.1 Многомерная модель хранилища
Многомерная модель БД появилась довольно давно, однако в силу присущих ей ограничений применение получила лишь в последнее время. При использовании этой модели данные хранятся не в виде плоских таблиц, как в реляционных БД, а в виде гиперкубов - упорядоченных многомерных массивов. То есть многомерное представление данных здесь реализуется физически. Конечно, такой подход требует большего объема памяти для хранения данных, при его использовании сложно модифицировать структуру данных. Например, добавление еще одного измерения приводит к необходимости полной перестройки гиперкуба. Однако многомерные СУБД обеспечи-
вают более быстрый по сравнению с реляционными системами поиск и чтение данных, избавляют от необходимости многократно соединять таблицы. Среднее время ответа на сложный аналитический запрос при использовании многомерных СУБД обычно в 10-100 раз меньше, чем в случае реляционной СУБД с нормализованной структурой.
Основные понятия многомерной модели - измерение и значение (ячейка). Измерение - это множество, образующее одну из граней гиперкуба (аналог домена в реляционной модели). Измерения играют роль индексов, используемых для идентификации конкретных значений в ячейках гиперкуба. Значения - это подвергаемые анализу количественные или качественные данные, которые находятся в ячейках гиперкуба (см. рис. 3.3).
В многомерной модели вводятся следующие основные операции манипулирования измерениями: 1) сечение; 2) вращение; 3) детализация; 4) свертка.
При выполнении операции сечения формируется подмножество гиперкуба, в котором значение одного или более измерений фиксировано. Например, если на рис. 3.3 зафиксировать значение измерения "Время" равным "январь 1991 года", то мы получим двухмерную таблицу с информацией о значениях всех параметров для всех субъектов РФ в январе 1991 года.
Операция вращения изменяет порядок представления измерений. Она обычно применяется к двухмерным таблицам, обеспечивая представление их в более удобной для восприятия форме. Если в исходной таблице по горизонтали были расположены субъекты РФ, а по вертикали параметры социально-экономической сферы, то после операции вращения параметры будут размещены по горизонтали, а названия субъектов РФ - по вертикали.
Для выполнения операций свертки и детализации должна существовать иерархия значений измерения, то есть некоторая подчиненность одних значений другим. Например, 12 месяцев образуют год, субъекты РФ образуют регионы. При выполнении операции свертки одно из значений измерения заменяется значением более высокого уровня иерархии. Например, аналитик, узнав значения параметров для января 1991 года, желает получить их значения за весь 1991 год. Чтобы это сделать, необходимо выполнить операцию свертки. Операция детализации - это операция, обратная свертке. Она обеспечивает переход от обобщенных к детализированным данным.
Основное назначение СУБД, поддерживающих многомерную модель, -реализация систем, ориентированных на аналитическую обработку. Многомерные СУБД лучше других справляются с задачами выполнения сложных нерегламентированных запросов.
Однако у многомерных БД имеются серьезные недостатки, сдерживающие их применение. Многомерные СУБД неэффективно по сравнению с реляцион-
ными используют память. В многомерной СУБД заранее резервируется место для всех значений, даже если часть из них заведомо будет отсутствовать. Другой недостаток состоит в том, что выбор высокого уровня детализации при реализации гиперкуба может очень сильно увеличить размер многомерной БД. В силу этих, а также некоторых других причин доступные на рынке многомерные СУБД не в состоянии оперировать данными большого объема. Объем, доступный им для хранения, ограничен 10-20 гигабайт.
Целесообразно использовать многомерную модель, если объем БД невелик и гиперкуб использует стабильный во времени набор измерений.
4.2 Реляционная модель хранилища данных
Основой при построении хранилища данных может служить и традиционная реляционная модель данных. В этом случае гиперкуб эмулируется СУБД на логическом уровне. В отличие от многомерных реляционные СУБД способны хранить огромные объемы данных, однако они проигрывают по скорости выполнения аналитических запросов.
При использовании РСУБД для организации хранилища данные организуются специальным образом. Чаще всего используется так называемая радиальная схема. Другое ее название - "звезда" (star). В этой схеме используются два типа таблиц: таблица фактов (фактологическая таблица) и несколько справочных таблиц (таблицы измерений).
В таблице фактов обычно содержатся данные, наиболее интенсивно используемые для анализа. Если проводить аналогию с многомерной моделью, то запись фактологической таблицы соответствует ячейке гиперкуба. В справочной таблице перечислены возможные значения одного из измерений гиперкуба. Каждое измерение описывается своей собственной справочной таблицей. Фактологическая таблица индексируется по сложному ключу, скомпонованному из индивидуальных ключей справочных таблиц. Это обеспечивает связь справочных таблиц с фактологической по ключевым атрибутам. В качестве примера на рис. 3.4 приведена упрощенная схема структуры хранилища данных, используемого для накопления информации из рассмотренного ранее примера (см. рис. 3.3).
В реальных системах количество строк в фактологической таблице может составлять десятки и сотни миллионов. Число справочных таблиц обычно не превышает двух десятков. Для увеличения производительности анализа в фактологической таблице могут храниться не только детализированные, но и предварительно вычисленные агрегированные данные.
Если БД включает большое число измерений, можно использовать схему "снежинка" (зпошйаке). В этой схеме атрибуты справочных таблиц могут быть детализированы в дополнительных справочных таблицах (см. рис. 3.5).
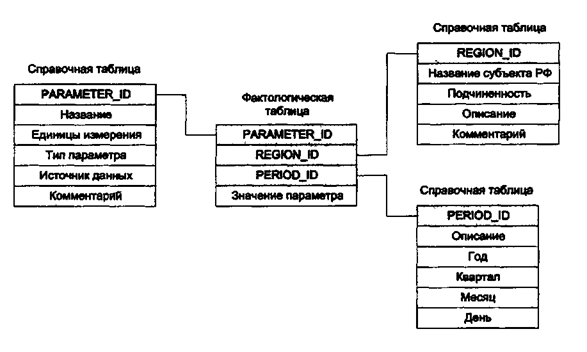
Рис. 3.4. Пример БД с радиально связанными таблицами (схема звезда): линиями показаны связи между таблицами; ключевые атрибуты таблиц выделены
серым цветам
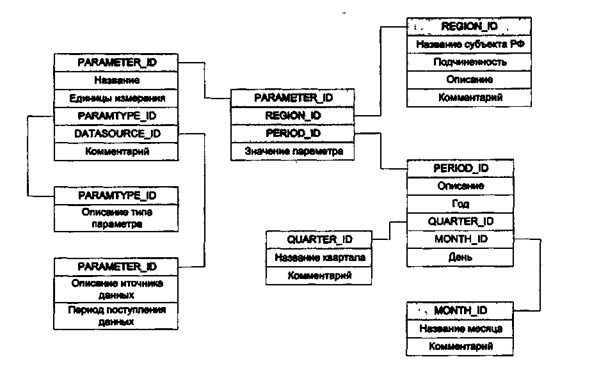
Рис. 3.5. Пример БД со схемой "снежинка"
Для сокращения времени, требуемого для получения отклика от аналитической системы, можно использовать некоторые специальные средства. В состав мощных реляционных СУБД обычно входят оптимизаторы запросов. При создании хранилищ данных на основе РСУБД их наличие приобретает особую важность. Оптимизаторы анализируют запрос и определяют лучшую, с позиции некоторого критерия, последовательность операций обращения к БД для его выполнения. Например, может минимизироваться число физических обращений к дискам при выполнении запроса. Оптимизаторы запросов используют сложные алгоритмы статистической обработки, которые оперируют числом записей в таблицах, диапазонами ключей и т.д.
3.5. Комбинация многомерного и реляционного подхода: киоски данных
Каждая из описанных моделей имеет как преимущества, так и недостатки. Многомерная модель позволяет производить быстрый анализ данных, но не позволяет хранить большие объемы информации. Реляционная модель, напротив, практически не имеет ограничений по объему накапливаемых данных, однако СУБД на ее основе не обеспечивают такой скорости выполнения аналитических запросов, как МСУБД. Нельзя ли совместить два этих подхода так, чтобы скрыть их недостатки и сделать более заметными их достоинства? Удачные проекты реализации хранилищ данных, появившиеся в последнее время, показывают, что это возможно.
Ситуация, когда для анализа необходима вся информация, находящаяся в хранилище, возникает довольно редко. Обычно каждый аналитик или аналитический отдел обслуживает одно из направлений деятельности организации, поэтому в первую очередь ему необходимы данные, характеризующие именно это направление. Реальный объем этих данных не превосходит ограничений, присущих многомерным СУБД. Возникает идея выделить данные, которые реально нужны конкретным аналитическим приложениям, в отдельный набор. Такой набор мог бы быть реализован в многомерной БД. Источником данных для него должно быть центральное хранилище организации.
Если проводить аналогии с производством и "реализацией продукции, то многомерные БД выполняют роль мелких складов. В концепции ХД их принято именовать киосками данных (Data Marts). Киоск данных - это специализированное тематическое хранилище, обслуживающее одно из направлений деятельности организации. Логическая схема СППР, использующей центральное ХД организации и киоски данных аналитических отделов [12], представлена на рис. 3.6.
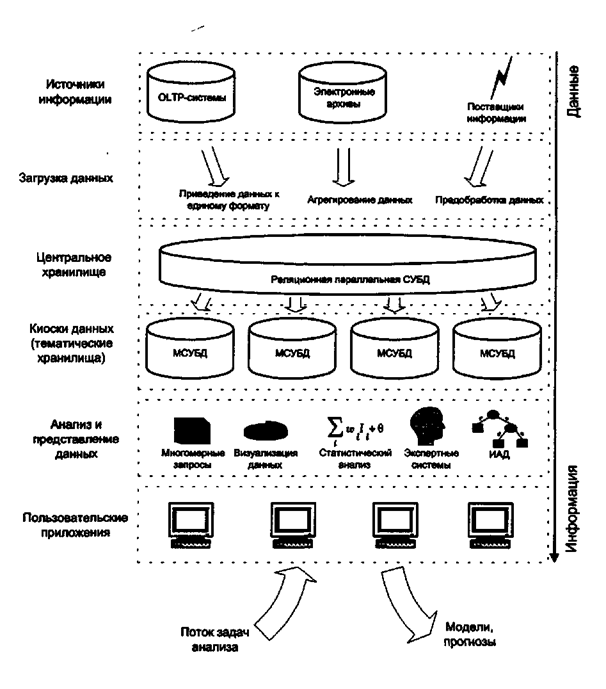
Рис. 3.6. Логическая схема СППР, использующей ХД и киоски данных
Такая схема, позволяет эффективно использовать возможности реляционных СУБД по хранению огромных объемов информации и способность многомерных СУБД обеспечивать высокую скорость выполнения аналитических запросов.
| <== предыдущая лекция | | | следующая лекция ==> |
| Возникновение и развитие судебной медицины. | | | Лексико-фразеологическое и семантическое богатство речи |
Дата добавления: 2016-02-04; просмотров: 4494;