Мультикомпьютеры с передачей сообщений
Мультипроцессоры NUMA
Плохая масштабируемость симметричных систем привела к появлению систем с неоднородным доступом к памяти (NUMA, NonUniform Memory Access).
Машины NUMA имеют три ключевые характеристики:
1) Существует одно адресное пространство, видимое для всех процессоров.
2) Каждый процессор имеет свою локальную память, которая представляет собой часть общей памяти ВС. Ей выделяется свой диапазон адресов из общего адресного пространства. Благодаря общему адресному пространству, каждый процессор может обратиться как к своей памяти, так и к памяти любого другого процессора (удалённой памяти).
3) Доступ к удаленной памяти производится с использованием команд LOAD и STORE.
4) Т.к. доступ к «своей» памяти происходит напрямую, а к чужой – через коммутатор или коммуникационную сеть, то доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти.
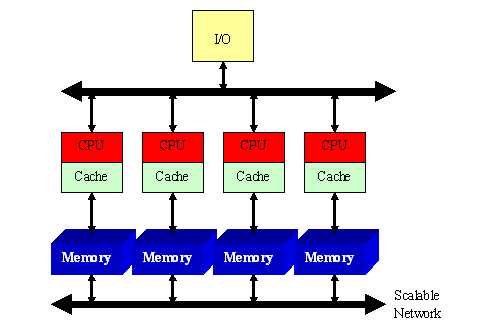
Часто строят системы, состоящие из однородных базовых модулей (плат), каждый из которых представляет собой SMP-систему (NUMA-SMP):
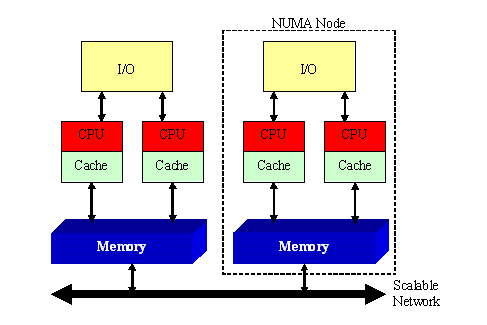
Например, система Tera 10 состоит из 544 SMP-узлов, каждый из которых содержит от 8 до 16-ти 64-х разрядных процессоров Itanium 2. В системе Origin SG поддерживается 1024 процессора R10000. Модули объединены с помощью высокоскоростного коммутатора.
Если время доступа к удаленной памяти не скрыто (поскольку кэш-память отсутствует), то такая система называется NC-NUMA (No Caching NUMA).
Если присутствуют согласованные кэши, то система называется CC-NUMA (Coherent Cache NUMA).
Мультикомпьютеры с передачей сообщений
В мультипроцессорах обращение к доступным областям памяти (как локальной, так и удаленной) можно получить с помощью обычных команд LOAD и STORE. Программы, написанные для мультипроцессора, могут получать доступ к любому месту в памяти, не имея никакой информации о внутренней топологии связей или схеме реализации.
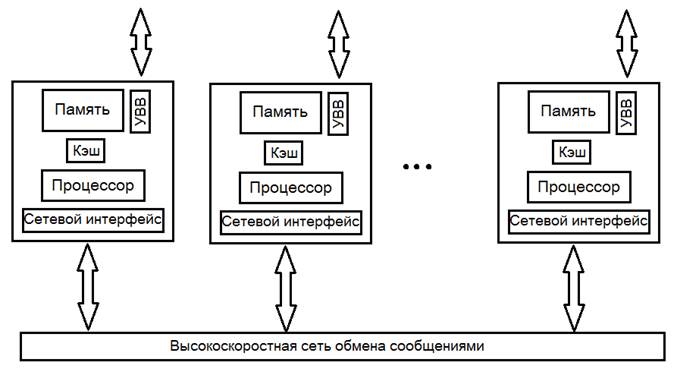
В мультикомпьютерах каждый процессор имеет свою собственную память, к которой другие процессоры не могут получить прямой доступ (NORMA – NO-Rremote Memory Access). Программы на разных процессорах в мультикомпьютере взаимодействуют друг с другом с помощью примитивов send и receive, которые используются для передачи сообщений (команды LOAD и STORE в этом случае неприменимы).
Все мультикомпьютеры сходны в одном: когда программа выполняет примитив send, процессор передачи данных получает уведомление и передает блок данных в целевую машину (воможно, после предварительного запроса и получения разрешения).
Мультикомпьютеры очень трудно нормально классифицировать. Однако можно выделить два наиболее общих типа: МРР и COW.
Системы с массовой параллельной обработкой (МРР)
 |
Массивно-параллельная система – высокопроизводительная параллельная вычислительная система, создаваемая с использованием специализированных вычислительных модулей и систем связи.
Вычислительные модули MPP состоят из:
ü одного или нескольких процессоров;
ü собственной оперативной памяти;
ü подсистемы ввода/вывода;
ü коммуникационного оборудования.
– то есть имеют все необходимое для независимого функционирования.
Изначально в качестве таких вычислительных узлов использовались транспьютеры (термин объединяет два понятия – «транзистор» и «компьютер»).
Транспьютер – это СБИС, включающая в себя центральный процессор, блок FPU, статическое ОЗУ, интерфейс с внешней памятью и несколько (вначале 4) каналов связи (линков). Первый транспьютер был разработан в 1986 году фирмой Inmos.
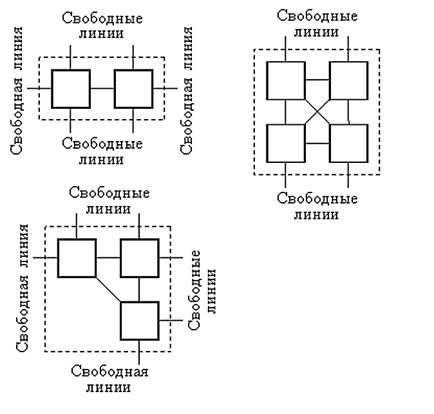 |
Основная особенность транспьютеров – возможность использования встроенных линков для соединения транспьютеров между собой и для подключения внешних устройств. Примеры возможного соединения:
Для перехода к более сложным топологиям количество коммуникационных каналов в вычислительных узлах современных систем может быть большим. Например, топология трехмерного тора (Cray T3D/T3E) или n-мерного гиперкуба (nCUBE) требует увеличения количества линков (до 6).
Примеры реализации вычислительных узлов современных MPP:
Тяньхэ-2, 16000 узлов – по 2 процессора Intel Xeon E5-2692 на архитектуре Ivy Bridge с 12 ядрами каждый (частота 2,2 ГГц) и 3 специализированных сопроцессора Intel Xeon Phi 31S1P (на архитектуре Intel MIC, по 57 ядер на ускоритель, частота 1.1 ГГц, пассивное охлаждение). На каждом узле установлено 64 ГБ DDR3 ECC памяти (16 модулей) и дополнительно по 8 ГБ GDDR5 в каждом Xeon Phi (всего 88 ГБ).
Titan (Cray XK7) – 18 688 вычислительных узлов – по шестнадцатиядерному процессору AMD Opteron 6200 и ускорителю NVIDIA Tesla K20.
Основной неформальный признак, по которому ВС относят к МРР – количество процессоровN. Обычно при N >128 считается, что это уже МРР, а при N <64 – еще нет.
Работу узлов системы координирует хост-компьютер, в качестве которого может использоваться отдельная машина или один из узлов системы. При выделенной хост-машине на ней функционирует полноценная ОС (пример: RS/6000), а на узлах – её урезанный вариант с функциями ядра ОС. При отсутствии хост-машины ОС устанавливается на каждый узел.
Схема взаимодействия хост-компьютера с узлами:
ü Хост формирует очередь заданий и назначает им уровни приоритета.
ü Задания из очереди передаются узлам при их освобождении.
ü Узлы оповещают хост о ходе выполнения задания или о потребностях в дополнительных ресурсах.
ü Хост обнаруживает нештатные ситуации, прерывает выполнение задания при появлении более приоритетной задачи.
Очевидно, что хост также является самым слабым местом MPP).
Самое важное свойство MPP-систем – высокая степень масштабируемости. Самая главная проблема – эффективность работы коммуникационной среды.
В настоящее время MPP возглавляют первые места рейтинга высокопроизводительных систем.
COW – Clusters of Workstations (кластеры рабочих станций)
Второй тип мультикомпьютеров – это системы COW (Cluster of Workstations – кластер рабочих станций) или NOW (Network of Workstations – сеть рабочих станций). Обычно кластер состоит из множества ПК или рабочих станций, соединенных посредством сетевых плат.
В отличие от МРР, COW полностью строится из стандартных распространенных компонентов.
Кластеры обычно делят на централизованные и децентрализованные.
Централизованные системы COW компактно монтируются в большой блок в одной комнате. При компоновке стараются длину связей. Такие структуры называют гомогенными кластерами (все компьютеры имеют одинаковую конфигурацию) и не имеют никаких периферических устройств, кроме сетевых карт и, обычно, дисковых подсистем.
Децентрализованная система COW состоит из территориально распределенных компьютеров, связанных через локальную сеть. Другое название – гетерогенные кластеры (используются компьютеры разной конфигурации с полным набором периферийных устройств).
Узлы кластера контролируют работоспособность друг друга (специальный сигнал heart-beat – «сердцебиение») и обмениваются информацией.
Специализированное ПО обеспечивает восприятие кластера в качестве единого ресурса. Т.е. с точки зрения пользователя, администратора или приложения имеется только одна сущность, в которой неразличимы отдельные составляющие элементы.
Выделяют три основных вида кластеров:
ü Fail-over (или High-availability clusters, HA) – кластеры высокой доступности (отказоустойчивые);
ü Load-balancing – балансировочные, распределяющие нагрузку;
ü High Performance Computing (HPC) высокопроизводительные вычислительные кластеры.
HA – кластеры используют выделенное контрольное (heartbeat) соединение для мониторинга состояния сервисов: как только заданный сервис на одной машине выходит из строя, то другая начинает выполнять её функции.
Пример использования балансировочных кластеров: в момент поступления запроса к веб-серверу кластер сначала определяет наименее загруженную машину, а затем направляет к ней запрос.
HPC используется специально для центров обработки информации, которым необходима максимально возможная производительность.
Пример: IBM Roadrunner.
-------------------------------------------------------------------
Одним из первых был реализован проект COCOA: на базе 25 двухпроцессорных ПК (DELL, Pentium II/400 MHz, 512 MB, 4-гигабайтный жесткий диск SCSI и сетевой адаптер Fast Ethernet) общей стоимостью порядка $ 100000 (1998 г.) была создана система с производительностью, эквивалентной 48-процессорному Cray T3D стоимостью несколько миллионов.
Коммуникационную среду можно достаточно полно охарактеризовать двумя параметрами: латентностью (время задержки при отправке сообщения) и пропускной способностью (скорость передачи информации). Для Cray T3D эти параметры составляют соответственно 1 мкс и 480 мб/с, а для кластера (на базе Fast Ethernet) 100 мкс и 10 мб/с.
Это частично объясняет очень высокую стоимость суперкомпьютера. При таких параметрах, как у рассматриваемого кластера, найдутся не так много задач, которые можно эффективно решать на довольно большом количестве процессоров.
GRID Computing (GRID вычисления, мета-компьютинг, NOW)
Грид-технологии (Grid) позволяют создать географически распределенные вычислительные инфраструктуры, объединяющие разнородные ресурсы и реализующие возможность коллективного доступа к этим ресурсам. Основными направлениями развития грид-технологий являются: вычислительный грид, грид для интенсивной обработки данных и семантический грид для оперирования данными из различных баз данных. Технология возникла вместе с развитием высокоскоростной сетевой инфраструктуры в начале 90-х годов.
Мета-компьютинг использует объединение разнородных территориально распределенных вычислительных ресурсов для решения одной задачи.
Для grid-вычислений характерно отсутствие постоянной конфигурации – отдельные компоненты могут включаться в сеть или отключаться от нее без потери системой функциональности.
Оптимальной оказывается работа NOW-систем в задачах переборного и поискового типа, где вычислительные узлы практически не взаимодействуют друг с другом и основную часть работы производят в автономном режиме.
Схема работы узла: специальный программный модуль, расположенный на вычислительном узле, определяет факт простоя (слабой загруженности) этого компьютера, соединяется с управляющим узлом мета-компьютера и получает от него очередную порцию работы (например, области в пространстве перебора). По окончании счета по данной порции вычислительный узел передает обратно отчет о результатах или сигнал о достижении цели поиска.
Пример ПО для grid – BOINC (Berkeley Open Infrastructure for Network Computing – открытая платформа Университета Беркли для сетевых вычислений). Система была разработана в Калифорнийском университете в Беркли под руководством Дэвида Андерсона (David Anderson) командой, создавшей легендарный проект SETI@home. Основным мотивом разработки системы послужила нехватка свободных вычислительных мощностей для обработки данных, поступающих от радиотелескопов.
Система BOINC состоит из:
ü программы-клиента, общей для всех BOINC-проектов;
ü составного сервера (физически сервер может состоять из нескольких отдельных компьютеров);
ü ПО сервера.
По состоянию на конец 2012 г. BOINC применяется в 87 открытых проектах распределённых вычислений (ещё 24 обходятся без него). Общее количество участников составляло около 2,5 миллионов. Число компьютеров, ведущих вычисления – свыше семи миллионов, а суммарная производительность оценивается в семь петафлопс.
| <== предыдущая лекция | | | следующая лекция ==> |
| Системы с общей шиной и разделением по времени | | | Раздел IV. Порядок контроля выполнения и проектировки ПОН |
Дата добавления: 2016-01-29; просмотров: 2709;