Всегда ли хорош вектор?
Изложенное в предыдущей лекции понятие динамически растущего массива (вектора) пригодно для решения многих задач, требующих простой обработки различных последовательностей. Основным преимуществом вектора является его простота и эффективность размещения в памяти цельным блоком. Работа с уже заполненным данными вектором очень похожа на работу с обычным массивом. Любую ячейку можно адресовать по целочисленному индексу, представляющему собой смещение относительно начала блока, и такая операция обращения выполняется на процессоре за 1 действие. Вектор также очень эффективен, если добавлять и удалять хранящиеся в нем элементы с конца последовательности.
Вооружившись полученным ранее знанием, попробуем решить еще одну задачу. Предположим, пользователь вводит некоторую последовательность положительных целых чисел, завершая ввод нулем. Затем вводится порядковый номер позиции, и элемент, соответствующий этой позиции удаляется из последовательности. Программа печатает на экране последовательность после удаления элемента в указанной позиции. Используя предыдущие наработки по векторам и дополняя их несколькими полезными новыми вспомогательными функциями, решение могло бы выглядеть следующим образом:
#include "integer_vector.hpp"
intmain ()
{
// Создаем и инициализируем вектор
IntegerVector v;
IntegerVectorInit( v );
// Вводим числа до ввода 0
std::cout << "Input integers, stop with zero: ";
IntegerVectorReadTillZero( v, std::cin );
// Вводим позицию, которую требуется удалить
std::cout << "Input position to delete: ";
intposition2Delete;
std::cin >> position2Delete;
// Проверяем корректность введенной позиции
if( position2Delete < 0 || position2Delete >= v.m_nUsed )
// Сообщаем о некорректной позиции
std::cout << "Error: invalid position specified." << std::endl;
Else
{
// Удаляем элемент вектора
IntegerVectorDeleteAt( v, position2Delete );
// Печатаем результирующую последовательность
std::cout << "Result: ";
IntegerVectorPrint( v, std::cout );
std::cout << std::endl;
}
// Освобождаем память вектора
IntegerVectorDestroy( v );
}
В ходе решения было введено три дополнительные функции. Подразумеваем, что их объявления будут внесены в общий заголовочный файл, а приведенные ниже реализации будут размещены рядом с реализациями других функций. Ниже приведены объявления функций, которые требуется поместить в заголовочный файл:
voidIntegerVectorReadTillZero ( IntegerVector & _vector, std::istream & _stream );
voidIntegerVectorPrint ( constIntegerVector & _vector,
std::ostream & _stream,
char_sep = ' ' );
voidIntegerVectorDeleteAt ( IntegerVector & _vector, int_positionAt );
Первая из них добавленных функций должна осуществлять ввод последовательности в вектор до тех пор, пока не встретится число 0. Реализация такой функции похожа на предыдущую функцию ввода, ожидавшую завершения потока:
voidIntegerVectorReadTillZero ( IntegerVector & _vector, std::istream & _stream )
{
// Вводим числа до достижения условия выхода
while( true)
{
// Попытка ввода очередного числа
inttemp;
_stream >> temp;
// Если поток в корректном состоянии и введено число, отличное от 0,
// добавляем новые данные в конец вектора
if( _stream && temp != 0 )
IntegerVectorPushBack( _vector, temp );
Else
// Иначе - конец ввода
break;
}
}
Вторая введенная функция решает обратную задачу - выводит полученную последовательность в указанный поток через некоторый разделитель, по умолчанию используется символ-пробел (при желании, можно ее использовать для программ из предыдущей лекции):
voidIntegerVectorPrint ( constIntegerVector & _vector,
std::ostream & _stream,
char_sep )
{
for( inti = 0; i < _vector.m_nUsed; i++ )
_stream << _vector.m_pData[ i ] << _sep;
}
Отметим, что в данной функции, в отличие от других, передается ссылка на объект-вектор с модификатором const, запрещающим модификацию внутренних переменных структуры. Так следует поступать каждый раз, когда функция не намеревается изменять состояние переданного объекта, а лишь воспользуется его данными без изменений. Во-первых, это позволит избежать ошибок, связанных со случайной непреднамеренной модификацией данных в результате ошибки программиста (например, случайно записали оператор присвоения “=” вместо оператора сравнения “==”). Во-вторых, такую функцию будет можно использовать на константных данных. В-третьих, константность ссылки-аргумента подчеркивает намерение функции не притрагиваться к содержимому объекта, что облегчает понимание поведения функции в использующем ее коде. Наконец, компилятор, зная, что объект не будет модифицирован внутри функции, может применить более эффективные способы оптимизации кода.
Третья функция выполняет удаление элемента в указанной позиции из вектора, и представляет для обсуждаемой в данной лекции темы наибольший интерес:
voidIntegerVectorDeleteAt ( IntegerVector & _vector, int_position )
{
// Проверяем корректность позиции в переданном векторе
assert( _position >= 0 && _position < _vector.m_nUsed );
// Сдвигаем все элементы, стоящие после указанной позиции на 1 ячейку влево
for( inti = _position + 1; i < _vector.m_nUsed; i++ )
_vector.m_pData[ i - 1 ] = _vector.m_pData[ i ];
// Уменьшаем счетчик занятых элементов
-- _vector.m_nUsed;
}
Макрос assert - это простейшее средство внутренней диагностики программ. При сборке программы в отладочной конфигурации, указанные в скобках утверждения проверяются во время выполнения кода. Если утверждение истинно, не происходит ничего. Если же предположение нарушено, среда разработки тем или иным способом (достаточно заметно - например, большой диалог с восклицательными знаками, сопровождаемым звуковым оповещением) сигнализирует разработчику об ошибке. При сборке в релизной конфигурации макросы assert “вырезаются” препроцессором, а значит не оказывают никакого влияния на ход выполнения программы.
Следует четко различать обработку ошибок от средств внутренней диагностики. Хотя часто эти действия внешне похожи, их цели весьма различны. Обработка ошибок предполагает корректную реакцию программы на некорректный ввод пользователя, некорректное внешнее состояние, обычно сопровождается, по возможности, автоматическим исправлением или подсказкой, или, как минимум, вразумительным сообщением о произошедшей ситуации. При этом, программа должна попытаться восстановить свою работоспособность или хотя бы корректно завершиться.
Задача внутренней диагностики совсем другая - выявление некорректного использования кода со стороны программиста на этапе разработки и отладки программы. Речь о восстановлении работоспособности не идет, а наоборот, желательным является заметный однозначный сигнал о нарушении некоторого предположения. В такой ситуации, чем проблема виднее, тем лучше.
В частности, в рассмотренном выше примере проверка корректности позиции в векторе выполнялась дважды. Сначала в функции main осуществлялась обработка ошибок, и в случае ее обнаружения на консоли выдавалось сообщение об ошибке для внешнего пользователя программы. Внутри же вспомогательной функции была размещена диагностическая проверка при помощи макроса assert, созданная для разработчика.
И все же, ключевым дискуссионным вопросом является цикл, перемещающий ячейки в результате удаления указанного элемента:
// Сдвигаем все элементы, стоящие после указанной позиции на 1 ячейку влево
for( inti = _position + 1; i < _vector.m_nUsed; i++ )
_vector.m_pData[ i - 1 ] = _vector.m_pData[ i ];
Возникает вопрос - эффективно ли данное решение с точки зрения производительности? Ответ на этот вопрос зависит от конкретной указанной позиции.

Если речь идет о последней позиции, т.е., о конце вектора, цикл не выполнится ни разу. По мере удаления желаемой позиции от конца вектора цикл будет выполняться все большее количество раз. Худшим случаем является удаление из 0 позиции, предполагающее перемещение всех остальных данных вектора. Исходя из этого несложного фрагмента кода, очевидно, что вектор эффективен лишь для тех задач, в которых не происходит удаления элементов далеко от конца.
Аналогичная дилемма возникает и для задачи вставки нового значения в произвольную позицию. Допустим, потребуется аналогичная функция, которая вставит новое значение в вектор в указанную позицию. Все элементы вектора, находившиеся до начала изменения начиная с интересующей позиции и правее - придется перемещать вправо. Возможно, это потребует от вектора вырасти и сменить блок хранения данных. Ниже приведен пример похожей программы, которая просит пользователя ввести позицию и значение для вставки, а затем выводит измененную последовательность на экран:
#include "integer_vector.hpp"
intmain ()
{
IntegerVector v;
IntegerVectorInit( v );
std::cout << "Input integers, stop with zero: ";
IntegerVectorReadTillZero( v, std::cin );
std::cout << "Input position to insert: ";
intposition2Insert;
std::cin >> position2Insert;
if( position2Insert < 0 || position2Insert >= v.m_nUsed )
std::cout << "Error: invalid position specified." << std::endl;
Else
{
std::cout << "Input value to insert: ";
intvalue2Insert;
std::cin >> value2Insert;
IntegerVectorInsertAt( v, position2Insert, value2Insert );
std::cout << "Result: ";
IntegerVectorPrint( v, std::cout );
std::cout << std::endl;
}
IntegerVectorDestroy( v );
}
В заголовочный файл потребуется добавить объявление очередной полезной функции:
voidIntegerVectorInsertAt ( IntegerVector & _vector, int_position, int_data );
Прежде чем приступать к реализации этого нового средства, следует обратить внимание на его потенциальную возможность увеличить размер выделенной вектором памяти. Такая функциональность уже имеется в нашем решении, добавляющем новый элемент в конец вектора. Поскольку здесь требуется аналогичное поведение, а нами было взято на себя обещание осуществлять рефакторинг кода, когда обнаруживаются дупликации, следует выделить задачу роста вектора в отдельную функции. При этом, ее не стоит помещать в заголовочный файл, ведь данный механизм является деталью реализации вектора и врядли интересен использующим вектор программам.
voidIntegerVectorGrow ( IntegerVector & _vector )
{
intnAllocatedNew = _vector.m_nAllocated * 2;
int* pNewData = new int[ nAllocatedNew ];
memcpy( pNewData, _vector.m_pData, sizeof( int) * _vector.m_nAllocated );
delete[] _vector.m_pData;
_vector.m_pData = pNewData;
_vector.m_nAllocated = nAllocatedNew;
}
Соответственно, прежняя реализация функции добавления числа в конец вектора упрощается:
voidIntegerVectorPushBack ( IntegerVector & _vector, int_data )
{
// Если места в векторе для нового числа больше нет, следует вырасти
if( _vector.m_nUsed == _vector.m_nAllocated )
IntegerVectorGrow( _vector );
// Дописываем новый элемент в конец вектора
_vector.m_pData[ _vector.m_nUsed++ ] = _data;
}
Наконец, можно приступать к реализации функции вставки числа в произвольную позицию:
voidIntegerVectorInsertAt ( IntegerVector & _vector, int_position, int_data )
{
// Проверяем корректность позиции в переданном векторе
assert( _position >= 0 && _position < _vector.m_nUsed );
// Определяем необходимость в росте вектора
intnewUsed = _vector.m_nUsed + 1;
if( newUsed > _vector.m_nAllocated )
IntegerVectorGrow( _vector );
// Перемещаем существующие элементы правее на 1 позицию, начиная с интересующей
for( inti = _vector.m_nUsed; i > _position; i-- )
_vector.m_pData[ i ] = _vector.m_pData[ i - 1];
// Вставляем новое данное в интересующую позицию
_vector.m_pData[ _position ] = _data;
// Изменяем счетчик занятых элементов
_vector.m_nUsed = newUsed;
}
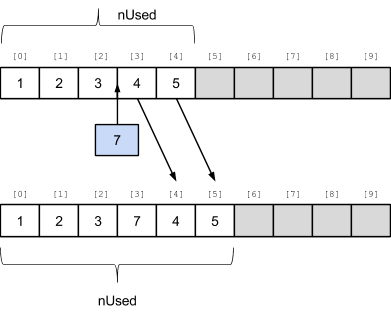
Точно так же, как и при удалении, чем дальше интересующая позиция от конца вектора, тем больше машинных инструкций по перемещению данных придется выполнить. Самый худший случай - вставка в нулевую позицию, при которой придется переместить правее все прежнее содержимое вектора.
Из изложенного следует сделать вывод о том, что вектор, несмотря на его простоту, эффективен для обработки последовательностей далеко не в любой ситуации. Если задача предполагает добавления и удаления элементов в произвольной позиции, а особенно в начальной - стоит подумать о совсем другой структуре данных.
Связные списки
Указанную проблему можно решить при помощи связных списков (linked list). Такая структура состоит из набора объектов-узлов, каждый их которых содержит хранимое значение, а также связи с соседними узлами. Под связями понимают указатели, содержащие адреса объектов-узлов. Собственно, главный объект-список хранит связь с начальным (pFirst) и конечным (pLast) элементом. Если узел имеет связь только со следующим узлом, такой список называется односвязным.Последний элемент списка не имеет связи со следующим, что эквивалентно значению 0:

Если же дополнительно присутствует связь с предыдущим узлом - список называют двусвязным. Списки с двумя связями требуют больше памяти, чем односвязные, и, обычно, их применяют лишь при необходимости двигаться между узлами в обратном направлении:
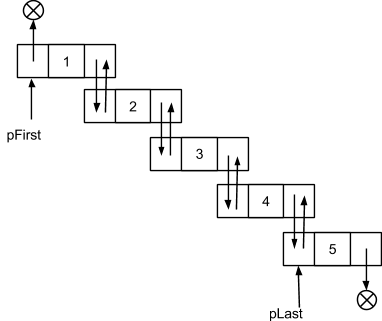
Очевидно, когда список пуст, связи pFirst и pLast обнулены, а когда список содержит только один элемент, обе эти связи указывают на него. Если список состоит хотя бы из двух элементов, связи pFirst и pLast будут указывать на разные объекты-узлы.
Основное преимущество такой структуры данных - это эффективность вставки и удаления элементов в произвольной позиции. В отличие от вектора, никаких данных сдвигать не требуется. Предположим в последовательности “1 2 3 4 5” нужно удалить элемент 3, находящийся в середине. Для этого достаточно отделить соответствующий узел от списка переназначением связей предшествующего и последующего элемента, а затем уничтожить сам объект-узел:

Аналогично, если в последовательности “1 2 3 4 5” требуется вставить еще один узел со значением “6” между элементами “3” и “4”, задача сводится к созданию нового узла и переназначению связей элементов-соседей:

Ниже демонстрируется пример реализации структуры односвязного списка. Руководствуясь принятым стилем, следует создать пару файлов заголовок/реализация для самой структуры данных, а затем включать этот заголовочный файл во все использующие программы. Заголовочный файл мог бы выглядеть следующим образом:
#ifndef _INTEGER_LIST_HPP_
#define _INTEGER_LIST_HPP_
#include <iostream>
// Структура-список
struct IntegerList
{
// Вспомогательная структура-узел
struct Node
{
// Хранящееся в узле значение
intm_value;
// Адрес следующего узла
Node * m_pNext;
};
// Адреса первого и последнего узла в списке
Node * m_pFirst, * m_pLast;
};
// Функция инициализации списка
voidIntegerListInit ( IntegerList & _list );
// Функция уничтожения списка
voidIntegerListDestroy ( IntegerList & _list );
// Функция определения пустоты списка
boolIntegerListIsEmpty ( constIntegerList & _list );
// Функция вставки нового элемента в конец списка
voidIntegerListPushBack ( IntegerList & _list, int_data );
// Функция вставки нового элемента в начало списка
voidIntegerListPushFront ( IntegerList & _list, int_data );
// Функция вставки элемента после указанного узла
voidIntegerListInsertAfter ( IntegerList & _list,
IntegerList::Node * _pPrevNode,
int_data );
// Функция вставки элемента перед указанным узлом
voidIntegerListInsertBefore ( IntegerList & _list,
IntegerList::Node * _pNextNode,
int_data );
// Функция удаления элемента с конца списка
voidIntegerListPopBack ( IntegerList & _list );
// Функция удаления элемента с начала списка
voidIntegerListPopFront ( IntegerList & _list );
// Функция удаления элемента после указанного узла
voidIntegerListDeleteAfter ( IntegerList & _list, IntegerList::Node * _pPrevNode );
// Функция удаления элемента до указанного узла
voidIntegerListDeleteBefore ( IntegerList & _list, IntegerList::Node * _pPrevNode );
// Функция чтения списка из входного потока до его завершения
voidIntegerListRead ( IntegerList & _list, std::istream & _i );
// Функция чтения списка из входного потока до обнаружения значения 0
voidIntegerListReadTillZero ( IntegerList & _list, std::istream & _i );
// Функция вывода списка в выходной потока через символ-разделитель
voidIntegerListPrint ( constIntegerList & _list,
std::ostream & _o,
char_sep = ' ' );
#endif // _INTEGER_FORWARD_LIST_HPP_
Структура-узел определяется как вложенная в структуре-списке. Такое объявление лишь подчеркивает логическую связь целое-часть между этими структурами. Сама по себе декларация вложенной структуры не создает ничего в памяти без переменных (pFirst, pLast).
В начальном состоянии список не содержит ни одного узла, и обе связи должны быть обнулены:
#include "integer_list.hpp"
#include <cassert>
voidIntegerListInit ( IntegerList & _list )
{
_list.m_pFirst = _list.m_pLast = nullptr;
}
При уничтожении следует пройти от начала до конца списка, удаляя все элементы один за другим:
voidIntegerListDestroy ( IntegerList & _list )
{
IntegerList::Node * pCurrent = _list.m_pFirst;
while( pCurrent )
{
IntegerList::Node * pTemp = pCurrent->m_pNext;
deletepCurrent;
pCurrent = pTemp;
}
_list.m_pFirst = _list.m_pLast = nullptr;
}
Функция определения пустоты списка может быть основана на сравнении связей pFirst/pLast с нулевыми указателями:
boolIntegerListIsEmpty ( constIntegerList & _list )
{
return_list.m_pFirst == nullptr;
}
При добавлении нового значения в конец списка следует создать новый узел и соединить его с прежним, считавшимся последним. Особый случай, который следует обработать - это добавление нового элемента в пустой список (обе связи pFirst и pLast должны указывать на новый узел).
voidIntegerListPushBack ( IntegerList & _list, int_data )
{
// Создаем новый узел:
// - сохраняем указанное значение в переменной m_value
// - новый узел пока не будет иметь следующего элемента
IntegerList::Node * pNewNode = newIntegerList::Node;
pNewNode->m_value = _data;
pNewNode->m_pNext = nullptr;
// Если список пуст, новый узел становится первым
if( ! _list.m_pFirst )
_list.m_pFirst = pNewNode;
// Если список содержит элементы, связываем прежний последний элемент с новым
Else
_list.m_pLast->m_pNext = pNewNode;
// Новый элемент теперь будет последним в списке
_list.m_pLast = pNewNode;
}
Ниже наглядно представлено несколько случаев добавления элемента в конец списка. Если список был пуст, при вставке в конец получаем список из 1 элемента с двумя указывающими на него связями:

Если список содержит только 1 элемент, будет добавлен второй и связи pFirst и pLast разойдутся:

Нетрудно представить дальнейший рост списка:
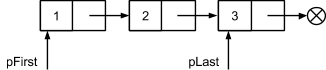
По аналогии реализовывается вставка элементов в начало списка. К слову, такая операция не предлагалась для векторов, как заведомо неэффективная. Список же, напротив, легко справится со вставкой нового элемента в начальную позицию:
voidIntegerListPushFront ( IntegerList & _list, int_data )
{
// Создаем новый узел:
// - сохраняем указанное значение в переменной m_value
// - новый узел точно будет связан с текущим началом списка
IntegerList::Node * pNewNode = newIntegerList::Node;
pNewNode->m_value = _data;
pNewNode->m_pNext = _list.m_pFirst;
// Новый узел становится первым в списке
_list.m_pFirst = pNewNode;
// Если раньше узлов не было, то еще и последним
if( ! _list.m_pLast )
_list.m_pLast = pNewNode;
}
Воспользовавшись новой функцией на аналогичной последовательности получаем обратный порядок следования элементов:

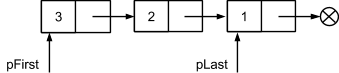
Еще один рассматриваемый вид вставки - после произвольного элемента. Здесь может быть 2 случая - общий в середине списка и частный, когда речь идет о последнем элементе:
voidIntegerListInsertAfter ( IntegerList & _list,
IntegerList::Node * _pPrevNode,
int_data )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Если запрошена вставка после последнего узла, задача сводится к уже решенной
if( _pPrevNode == _list.m_pLast )
IntegerListPushBack( _list, _data );
Else
{
// Создаем новый узел
IntegerList::Node * pNewNode = newIntegerList::Node;
pNewNode->m_value = _data;
// Следующий элемент предыдущего узла теперь следующий после нового узла
pNewNode->m_pNext = _pPrevNode->m_pNext;
// После предыдущего узла теперь следует новый
_pPrevNode->m_pNext = pNewNode;
}
}
Делать вставку нового элемента перед некоторым конкретным узлом не совсем удобно на односвязных списках, поскольку требуется пройти от самого начала до искомого элемента, чтобы обнаружить предыдущий узел. Если задачи требуют такой операции, следует предпочесть двусвязные списки, где связь с предыдущим элементом уже имеется в переданном узле. Односвязный список для этого случая работает неэффективно:
voidIntegerListInsertBefore ( IntegerList & _list,
IntegerList::Node * _pNextNode,
int_data )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Если запрошена вставка перед первым узлом, задача сводится к уже решенной
if( _pNextNode == _list.m_pFirst )
IntegerListPushFront( _list, _data );
Else
{
// Ищем узел, предшествующий указанному, с начала списка
IntegerList::Node * pCurrent = _list.m_pFirst;
while( pCurrent && pCurrent->m_pNext != _pNextNode )
pCurrent = pCurrent->m_pNext;
assert( pCurrent );
// Создаем новый узел
IntegerList::Node * pNewNode = newIntegerList::Node;
pNewNode->m_value = _data;
// Новый узел должен ссылаться на указанный
pNewNode->m_pNext = _pNextNode;
// Его предшественник - на новый
pCurrent->m_pNext = pNewNode;
}
}
Похожим образом реализуется удаление узлов. При удалении следует проверять граничные случае, когда в списке в результате остается 0 узлов. Удаление с начала списка выглядит следующим образом:
voidIntegerListPopFront ( IntegerList & _list )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Обрабатываем случай удаления единственного узла
IntegerList::Node * pFirst = _list.m_pFirst;
if( _list.m_pFirst == _list.m_pLast )
_list.m_pFirst = _list.m_pLast = nullptr;
Else
// Иначе, назначаем первым узлом текущий второй
_list.m_pFirst = pFirst->m_pNext;
// Первый узел больше не нужен
deletepFirst;
}
Удаление с конца списка также не слишком эффективно для односвязных структур, следует предпочесть двусвязные, если требуется такая операция:
voidIntegerListPopBack ( IntegerList & _list )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Обрабатываем случай удаления единственного узла
IntegerList::Node * pLast = _list.m_pLast;
if( _list.m_pFirst == _list.m_pLast )
_list.m_pFirst = _list.m_pLast = nullptr;
Else
{
// Иначе, находим предпоследний узел. Увы, только просмотрев весь список.
IntegerList::Node * pCurrent = _list.m_pFirst;
while( pCurrent->m_pNext != _list.m_pLast )
pCurrent = pCurrent->m_pNext;
// Назначаем последним узлом предпоследний
_list.m_pLast = pCurrent;
// Разрывам связь между предпоследним и последним узлами
pCurrent->m_pNext = nullptr;
}
// Последний узел больше не нужен
deletepLast;
}
Так выглядит удаление после произвольной позиции:
voidIntegerListDeleteAfter ( IntegerList & _list, IntegerList::Node * _pPrevNode )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Предполагаем, что указан не последний элемент
assert( _list.m_pLast != _pPrevNode );
// Связываем предыдущий узел с узлом, следующим за удаляемым
IntegerList::Node * pDyingNode = _pPrevNode->m_pNext;
_pPrevNode->m_pNext = pDyingNode->m_pNext;
// Обрабатываем случай, когда удаляется последний узел списка
if( _list.m_pLast == pDyingNode )
_list.m_pLast = _pPrevNode;
// Удалаемый узел больше не нужен
deletepDyingNode;
}
Наконец, приведем реализацию удаления до произвольной позиции :
voidIntegerListDeleteBefore ( IntegerList & _list, IntegerList::Node * _pNextNode )
{
// Предполагаем, что список не пустой
assert( ! IntegerListIsEmpty( _list ) );
// Предполагаем, что указан не первый элемент
assert( _list.m_pFirst != _pNextNode );
// Обрабатываем случай удаления первого узла списка
IntegerList::Node * pPrevNode = _list.m_pFirst,
* pCurrentNode = _list.m_pFirst->m_pNext;
if( pCurrentNode == _pNextNode )
{
delete_list.m_pFirst;
_list.m_pFirst = _pNextNode;
}
Else
{
// Ищем узел, предшествующий удаляемому
while( pCurrentNode->m_pNext != _pNextNode )
{
pPrevNode = pCurrentNode;
pCurrentNode = pCurrentNode->m_pNext;
}
// Связываем левого и правого соседа между собой
pPrevNode->m_pNext = _pNextNode;
// Удаляемый узел больше не нужен
deletepCurrentNode;
}
}
Функции ввода-вывода реализуются полностью аналогично векторам:
voidIntegerListRead ( IntegerList & _list, std::istream & _stream )
{
while( true)
{
inttemp;
_stream >> temp;
if( _stream )
IntegerListPushBack( _list, temp );
Else
break;
}
}
voidIntegerListReadTillZero ( IntegerList & _list, std::istream & _stream )
{
while( true)
{
inttemp;
_stream >> temp;
if( _stream && temp != 0 )
IntegerListPushBack( _list, temp );
Else
break;
}
}
voidIntegerListPrint ( constIntegerList & _list, std::ostream & _stream, char_sep )
{
constIntegerList::Node * pCurrent = _list.m_pFirst;
while( pCurrent )
{
_stream << pCurrent->m_value << _sep;
pCurrent = pCurrent->m_pNext;
}
}
Дата добавления: 2016-01-29; просмотров: 932;