Систематические сверточные коды
Общий принцип построения систематических сверточных кодов сводится к следующему. С помощью линейных операций над информационными символами определяются проверочные, которые затем размещаются между информационными. В качестве линейной операции в двоичных кодах применяется преимущественно суммирование по модулю 2.
Рассмотрим простейший сверточный код, известный под названием кода Финка-Хагельбергера и широко применяемый в технике связи. В этих кодах на каждый информационный символ приходится один проверочный (т.е. избыточность составляет 0,5), они способны исправлять как одиночные ошибки, так и пачки ошибок, т.е. несколько ошибок подряд. Исправляются пачки длиной не более h символов при условии, что все соседние пачки разделены промежутком не менее 3h+1, т.е. между последним символом предыдущей пачки и первым символом следующей находится не менее 3h+1 неискаженных символов.
Проиллюстрируем построение и работу кода на конкретном примере. Рассмотрим код, исправляющий пачки ошибок длиной h≤4. Процесс формирования кодовой последовательности показан на рис. 3.2. Кодирование осуществляется следующим образом. По мере поступления на вход кодера информационных символов а формируются проверочные символы b путем суммирования по модулю 2 попарно информационных символов, взятых с интервалом h/2. В более сложных вариантах могут суммироваться не два, а большее число информационных символов.

| а1 | а2 | а3 | а4 | а5 | а6 | а7 | а8 | а9 | кодируемая последовательность | |
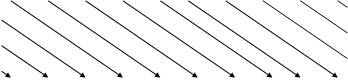
| Å | Å | Å | Å | Å | Å | Å | Å | Å | Å | |
| b1 | b2 | b3 | b4 | b5 | b6 | b7 | b8 | b9 | проверочные символы | ||
| а1b1 | a2b2 | a3b3 | a4b4 | a5b5 | a6b6 | a7b7 | a8b8 | a9 | сформированная последовательность | ||
| №1 | синдром ошибки в а1 | ||||||||||
| №2 | синдром ошибки в а2 | ||||||||||
| №3 | синдром ошибки в а3 | ||||||||||
| №4 | синдром ошибки в b1 | ||||||||||
| №5 | синдром ошибки в b2 | ||||||||||
| №6 | синдром ошибок в а1 и b1 | ||||||||||
| №7 | синдром ошибок в b1а2 | ||||||||||
| №8 | синдром ошибок в а1b1а2 | ||||||||||
| №9 | синдром ошибок в b1а2b2 | ||||||||||
| №10 | синдром ошибок в а1b1а2 b2 | ||||||||||
| №11 | синдром ошибок в b1а2b2а3 | ||||||||||
| №12 | синдром ошибок в а3b3 | ||||||||||
| №13 | синдром ошибок в а1b7 | ||||||||||
| №14 | синдром ошибок в а1а2 |
Рис. 3.2
В данном конкретном коде суммируются символы ai+ai+2=bj (нумерацию ведем отдельно по информационным и проверочным символам). Затем каждый полученный проверочный символ вставляется в общую последовательность после информационного символа ai+6, т.е. на расстоянии ℓ≥h=4 от последнего информационного символа, входящего в данную сумму. В итоге каждый информационный символ влияет на значение двух проверочных символов. Процесс кодирования продолжается непрерывно до тех пор, пока не будет закодирована вся последовательность поступающих символов.
Декодирование при приеме сводится к следующему.
Из принимаемой последовательности выделяется последовательность проверочных символов.
Из принятых информационных символов формируется последовательность проверочных символов аналогично тому, как это делалось на входе канала связи при кодировании.
Сформированная на месте приема последовательность проверочных символов суммируется по модулю 2 с принятой последовательностью проверочных символов. Полученная сумма используется в качестве синдрома ошибок.
Если данная сумма (синдром) состоит из одних нулей, это значит, что в полученной последовательности информационных символов ошибок нет, и она передается потребителю информации.
Если синдром получается не нулевым, специальная схема по синдрому формирует вектор ошибки, который затем суммируется по модулю 2 с принятой последовательностью информационных символов, и тем самым исправляется ошибка (или ошибки). Исправленная последовательность передается получателю информации.
На рис. 3.2 показаны синдрома одно-, двух-, трех- и четырехкратных ошибок. Среди них нет повторяющихся. Это означает, что такие ошибки могут опознаваться однозначно, а следовательно, и декодироваться. Легко убедиться, что синдрома кратных ошибок являются суммой синдромов соответствующих однократных.
Если последующая пачка ошибок начинается раньше, чем через 3h+1 после окончания предыдущей пачки, однозначность определения ошибки нарушается. Этот факт иллюстрируется показанными на рис. 2 синдромами №12 и 13, соответствующими ошибкам как в символах a3b3, так и в символах a1 и b7.
Выполнив аналогичные построения синдромов ошибок, можно убедиться, что в случае интервала между пачками 3h+1 однозначное определение ошибочных разрядов возможно, т.е. декодирование не приводит к неверным исправлениям.
Литература:
[1] стр. 256-260. [2] стр. 290-292.
Задание для самостоятельной работы:
В процессе изучения изложенного материала необходимо научиться самостоятельно формировать синдромы различных ошибок (по кратности и расположению), векторы ошибок и определять номера разрядов, ошибки в которых исправляют полученные векторы ошибок. Правильность полученных результатов можно проверить по примерам, показанным на рис. 3.2.
Рассмотрим один из возможных вариантов формирования вектора ошибок. Для наглядности разряды будем нумеровать в соответствии
с рис. 3.2.
Если произошло искажение одного информационного символа, то синдром будет содержать две единицы (см. векторы №1-3 на рис. 3.2). Вектор одиночной ошибки в информационном разряде можно сформировать так: задержать синдром на два такта и подать задержанный и незадержанный синдромы на логическую схему И(&) с двумя входами:
…001010000…
И(&) 000010100…
…000010000…
На выходе схемы И получаем последовательность, имеющую одну единицу. Эту последовательность и можно использовать в качестве вектора ошибки.
Если искажены два соседних информационных символа (например, а1, и а2, синдром ошибки будет содержать четыре единицы (см. синдром №14). При этом на выходе схемы И формируется последовательность с двумя единицами подряд, которую также можно использовать в качестве вектора ошибок.
Формирование вектора ошибок несколько усложняется, если кроме информационных искажаются рядом стоящие проверочные символы. Рассмотрим для наглядности следующий пример. Пусть искажены четыре символа подряд: a1b1a2b2. В этом случае в синдроме, кроме четырех единиц соответствующих ошибкам в информационных разрядах, перед ними будут еще две единицы за счет ошибок в проверочных разрядах b1 и b2, т.е. синдром ошибок будет выглядеть так: …0111111000… (см. синдром №10 на рис. 3.2). Если формировать в этом случае вектор ошибок по приведенной методике, получим следующий результат:
0011111100000…
И(&) 0000111111000…
0000111100000…
Сформированную последовательность нельзя использовать в качестве вектора указанных ошибок, так как она содержит не только две единицы, соответствующие ошибкам в информационных разрядах, но и еще две лишних единицы. Поэтому в общем случае алгоритм формирования вектора ошибок несколько усложняется:
1) инвертируется синдром, полученный в результате обработки принятой последовательности,
2) на один вход логической схемы И с тремя входами подается проинвертированный синдром, на остальные два входа – неинвертированные синдромы, задержанные по сравнению с инвертированным на 2 и 4 такта.
На выходе схемы М получаем требующийся вектор ошибок:
11000000111111…
И(&) 00001111110000…
00000011111100…
00000000110000…
3) просуммировав полученный вектор с задержанной на соответствующее количество тактов последовательностью информационных символов, получим исправленную последовательность:
| … | а-5 | а-4 | а-3 | а-2 | а-1 | а1 | а2 | а3 | а4 | ||
| Å | … | … | |||||||||
| … | а-5 | а-4 | а-3 | а-2 | а-1 | 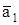
| 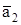
| а3 | а4 | … |
Здесь и - символы, противоположные соответственно символам а1 и а2.
Дата добавления: 2016-01-18; просмотров: 1173;