ОРГАНИЗАЦИЯ ОБСЛУЖИВАНИЯ ВЫЧИСЛИТЕЛЬНЫХ ЗАДАЧ
В зависимости от вида вычислительной системы (одно- или многомашинной), в которой организуется и планируется процесс обработки данных, возможны различные методы организации и обслуживания очередей заданий. При этом преследуется цель получения как можно лучших значений таких показателей, как производительность, загруженность ресурсов, малое время простоя, высокая пропускная способность, разумное время ожидания в очереди заданий (задание не должно ожидать „вечно“).
При организации обслуживания вычислительных задач на логическом уровне создается модель задачи обслуживания, которая может иметь как прямой, так и оптимизационный характер. При постановке прямой задачи ее условиями являются значения параметров вычислительной системы, а решением - показатели эффективности ОВП. При постановке обратной или оптимизационной задачи условиями являются значения показателей (или показателя) эффективности ОВП, а решением - параметры ВС.
В общем случае момент появления заданий в вычислительной системе является случайным, случайным является и момент окончания вычислительной обработки, так как заранее не известно, по какому алгоритму, а значит и сколько времени, будет протекать процесс. Тем не менее, для конкретной системы управления всегда можно получить статистические данные о среднем количестве поступающих в единицу времени на обработку в ВС вычислительных задач (заданий), а так же о среднем времени решении одной задачи. Наличие этих данных позволяет формально рассмотреть процедуру организации вычислительного процесса с помощью теории систем массового обслуживания (СМО). В этой теории при разработке аналитических моделей широко используются понятия и методы теории вероятности.
На рис. 3.11 изображена схема организации вычислительной многомашинной системы, где упорядочение очереди из потока заданий осуществляется диспетчером Д1, а ее обслуживание ЭВМ осуществляется через диспетчера Д2.
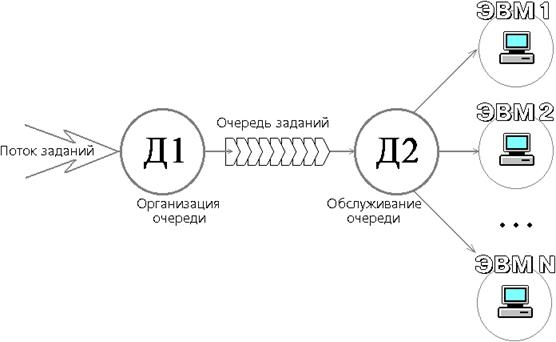
Рис. 3.11 Схема организации обслуживания заданий в многомашинной вычислительной системе
Такая система может быть охарактеризована как система с дискретными состояниями и непрерывным временем. Под дискретными состояниямипонимается то, что в любой момент времени система может находиться только в одном состоянии, а число состояний ограничено (может быть пронумеровано). Говоря о непрерывном времени, подразумевают, что границы переходов из состояния в состояние не фиксированы заранее, а неопределенны, случайны, и переход может произойти, в принципе, в любой момент времени.
Система (в нашем случае вычислительная система) изменяет свои состояния под действием потока заявок (заданий) - поступающие заявки (задания) увеличивают очередь. Число заданий в очереди плюс число заданий, которые обрабатываются ЭВМ (т.е. число заданий в системе), - это характеристика состояния системы. Очередь уменьшается, как только одна из ЭВМ заканчивает обработку (обслуживание) задания. Тотчас же на эту ЭВМ из очереди поступает стоящее впереди (или по какому-либо другому приоритету) задание, и очередь уменьшается. Таким образом, число заданий в системе (в очереди плюс на обслуживание) растет благодаря потоку заданий, а уменьшается - благодаря окончанию обслуживания с помощью ЭВМ. Устройства обработки заявок в теории СМО называют каналами обслуживания. В этой теории поток заданий (заявок на обслуживание) характеризуется интенсивностью l - средним количеством заявок, поступающих в единицу времени (скажем, в час). Среднее время обслуживания (обработки) одного задания tобопределяет, так называемую, интенсивность потока обслуживания - µ, равную
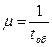 .
.
То есть m показывает, сколько в среднем заданий обслуживается системой в единицу времени. Следует напомнить, что моменты появления заданий и моменты окончания обслуживания случайны, а интенсивности потоков являются результатом статистической обработки случайных событий на достаточно длинном промежутке времени и позволяют получить, хотя и приближенные, но хорошо обозримые аналитические выражения для расчетов параметров и показателей эффективности системы массового обслуживания.
Для примера рассмотрим модель обслуживания вычислительных заданий в системе рис. 3.11, введя следующие предположения:
1. в системе протекают марковские случайные процессы;
2. потоки событий (появление заданий и окончание их обработки) являются простейшими;
3. число заданий в очереди не ограничено, но кончено.
Случайный процесс, протекающий в системе, называется марковским (по фамилии русского математика), если для любого момента времени вероятностные характеристики процесса в будущем зависят только от его состояния в данный момент и не зависят от того, когда и как система пришла в это состояние. Реально марковские случайные процессы в чистом виде в системах не протекают. Тем не менее, реальный случайный процесс можно свести при определенных условиях к марковскому. А в этом случае для описания системы можно построить довольно простую математическую модель.
Простейший поток событий характеризуется стационарностью, ординарностью и „без последействием“. Стационарность случайного потока событий означает независимость во времени его параметров (например, интенсивностей l и m). Ординарность указывает на то, что события в потоке появляются по одиночке, а “без последействия” - на то, что появляющиеся события не зависят друг от друга (то есть поступившее задание не обязано своим появлением предыдущему).
Третье предположение позволяет не ограничивать длину очереди (скажем, не более десяти заявок), хотя и содержит в себе требования конечности, то есть можно посчитать число заявок в очереди.
Обозначим состояние рассматриваемой вычислительной системы.
S0- в системе нет заданий;
S1- в системе одно задание и оно обрабатывается на ЭВМ 1;
S2 - в системе два задания и они обрабатываются на ЭВМ 1 и ЭВМ 2;
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ;
Sn - в системе n заданий и они обрабатываются на ЭВМ 1, ЭВМ 2,..., ЭВМ N;
Sn+1 - в системе 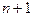 заданий, n заданий обрабатываются ЭВМ, а одно стоит в очереди
заданий, n заданий обрабатываются ЭВМ, а одно стоит в очереди
Sn+2 - в системе 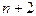 заданий, два задания стоят в очереди;
заданий, два задания стоят в очереди;
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ;
Sn+m - в системе 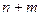 заданий, m заданий стоят в очереди.
заданий, m заданий стоят в очереди.
Учитывая, что увеличение числа заявок (заданий) в системе (т.е. номера состояния) происходит под воздействием их потока с интенсивностью l, а уменьшение - под воздействием потока обслуживания с интенсивностью m, изобразим размеченный граф состояний нашей системы. Он показан на рисунке 3.12. 
Рис. 3.12 Граф состояний многоканальной системы обслуживания с неограниченной очередью
Здесь окружности - состояния, дуги со стрелками - направления переходов в следующие состояния. Дуги помечены интенсивностями потоков событий, которые заставляют систему менять состояния. Переходы слева направо увеличивают номер состояния (то есть число заявок в системе), справа налево - наоборот. Как уже указывалось, увеличение числа заявок в системе происходит под воздействием входного потока заявок с постоянной интенсивностью l. Уменьшение числа заявок в системе (уменьшение номера состояния) происходит под воздействием потока обслуживания, интенсивность которого определяется средним временем обслуживания задания одной ЭВМ и числом ЭВМ, участвующих в обработке заданий при данном состоянии системы. Если одна ЭВМ дает интенсивность потока обслуживания m (например, в среднем 30 заданий в час), то одновременно работающие две ЭВМ дадут интенсивность обслуживания 2m, три ЭВМ - 3m., „n“ ЭВМ - nm. Такое увеличение интенсивности обслуживания будет происходить вплоть до состояния Sn, когда „n“ заданий параллельно находятся на обработке на „n“ ЭВМ. Появление в этот момент заявки переводит систему в состояние Sn+1, при котором одна заявка стоит в очереди. Появление еще одной - в состояние Sn+2 и т.д. Интенсивность же потока обслуживания при этом будет оставаться неизменной и равной nm, так как все ЭВМ вычислительной системы уже задействованы.
При исследовании такой вероятностной системы важно знать значение вероятностей состояний, с помощью которых можно вычислить показатели эффективности такие, как количество заданий в системе, время ожидания обработки, пропускную способность и т.д. Как известно, значение вероятности лежит в пределах от 0 до 1. Так как мы рассматриваем дискретную систему, то в любой момент времени она может находиться только в одном из состояний и, следовательно, сумма вероятностей состояний всегда равна 1, т.е.
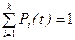 ,
,
где k- число возможных состояний системы;
i - номер состояния.
Для того, чтобы определить значение Pi(t), приведенной формулы не достаточно. Кроме нее составляется еще система дифференциальных уравнений Колмогорова, решение которой и дает искомые значения Pi(t). Чаще всего реальные вычислительные системы быстро достигают установившегося режима, и тогда вероятности состояний перестают зависеть от времени и практически показывают, какую долю достаточно длинного промежутка времени система будет находиться в том или ином состоянии. Например, если система имеет три возможных состояния P1=0,2, P2=0,6, P3=0,1, то это означает, что в состоянии S1 система в среднем находится 20% времени, в S2- 60%, а в S3 - 10% времени. Такие не зависимые от времени вероятности называют финальными.
Финальные вероятности системы вычислить уже проще, так как уравнения Колмогорова при этом превращаются в алгебраические. В нашем случае на основе графа рис. 3.12. для определения финальных вероятностей вычислительной системы может быть записана следующая система алгебраических уравнений.
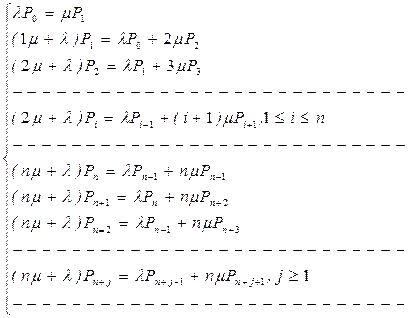
Это система однородных уравнений (свободный член равен нулю), но благодаря тому, что
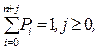
система разрешима. Финальные вероятности состояний системы в результате решения описываются следующими математическими отношениями.
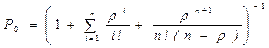
где P0 - вероятность состояния S0, при котором в системе заявок нет;
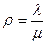 - параметр системы, показывающий, сколько в среднем заявок приходит в систему за среднее время обслуживания заявки одной ЭВМ (одним каналом обслуживания).
- параметр системы, показывающий, сколько в среднем заявок приходит в систему за среднее время обслуживания заявки одной ЭВМ (одним каналом обслуживания).

где Pi -вероятность состояния Si.

где Pn - вероятность того, что все ЭВМ заняты.
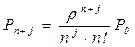
где Pn+j - вероятность того, что все ЭВМ системы заняты обработкой заданий и ‘j’ заявок стоят в очереди.
Приведенные формулы имеют смысл только в том случае, если очередь конечна. Условием конечности длины очереди является 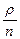 <1.
<1.
Или, если заменить r его выражением через l и m,
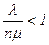 .
.
Практически это выражение говорит о том, что в среднем число заданий, приходящих в вычислительную систему в единицу времени, должно быть меньше числа обрабатываемых заданий в единицу времени всеми ЭВМ системы. Если же 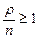 , то очередь растет до бесконечности и такая вычислительная система не справится с потоком заданий. Вот тут и могут появиться задания, ожидающие обработки „вечно“.
, то очередь растет до бесконечности и такая вычислительная система не справится с потоком заданий. Вот тут и могут появиться задания, ожидающие обработки „вечно“.
Основными показателями эффективности рассматриваемой системы являются: среднее число занятых каналов (т.е. ЭВМ) - 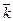 , среднее число заданий в очереди Lоч и в системе Lсис, среднее время пребывания задания в системе Wсис и в очереди Wоч.
, среднее число заданий в очереди Lоч и в системе Lсис, среднее время пребывания задания в системе Wсис и в очереди Wоч.
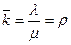 ;
;
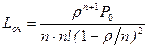 ;
;
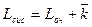 ;
;
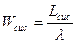 ;
;
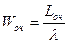 .
.
Как видно, полученная математическая модель довольно проста и позволяет легко рассчитать показатели эффективности вычислительной системы. Из модели очевидно, что для уменьшения времени пребывания задания в системе, а значит и в очереди, требуется, при заданной интенсивности потока заявок, либо увеличивать число обслуживающих ЭВМ, либо уменьшать время обслуживания каждой ЭВМ, либо и то и другое вместе.
С помощью теории массового обслуживания можно получить аналитические выражения и при других дисциплинах обслуживания очереди и конфигурациях вычислительной системы. Рассматривая модель обслуживания заданий, мы исходим из предположений того, что процессы в системе - марковские, а потоки - простейшие. Если эти предположения не верны, то получить аналитические выражения трудно, а чаще всего - невозможно. Для таких случаев моделирование проводится с помощью метода статистических испытаний (метода Монте-Карло), который позволяет создать алгоритмическую модель, включающую элементы случайности, и путем ее многократного запуска, получить статистические данные, обработка которых дает значения финальных вероятностей состояний.
Как указывалось, организация очереди, поддержание ее структуры возлагается на диспетчера Д1, а передача заданий из очереди на обработку в вычислительные машины, поддержание дисциплины обслуживания в очереди (поддержка системы приоритетов) осуществляется диспетчером Д2
(рис. 3.11). В вычислительной системе диспетчеры реализуются в виде управляющих программ, входящих в состав операционных систем ЭВМ.
Появление заданий при технологическом процессе обработки данных является случайным, но при решении задачи по программе должны быть учтены и минимизированы связи решаемой задачи с другими функциональными задачами, оптимизирован процесс обработки по ресурсному и временному критериям. Поэтому составной частью процедуры организации вычислительного процесса является планирование последовательности решения задач по обработке данных.
ОРГАНИЗАЦИЯ ПЛАНИРОВАНИЯ ОБРАБОТКИ ВЫЧИСЛИТЕЛЬНЫХ ЗАДАЧ
Эффективность обслуживания вычислительных задач (их программ) зависит, прежде всего, от среднего времени обслуживания 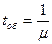 , поэтому в вычислительной системе (и в многомашинной, и в одномашинной особенно) требуется решать проблему минимизации времени обработки поступивших в систему заданий. Иногда эта проблема трансформируется в задачу максимизации загрузки устройств ЭВМ, являющихся носителями ресурсов.
, поэтому в вычислительной системе (и в многомашинной, и в одномашинной особенно) требуется решать проблему минимизации времени обработки поступивших в систему заданий. Иногда эта проблема трансформируется в задачу максимизации загрузки устройств ЭВМ, являющихся носителями ресурсов.
При решении вычислительной задачи ЭВМ использует различные свои ресурсы в объеме и последовательности, определяемыми алгоритмом решения. К ресурсам ЭВМ относятся объемы оперативной и внешней памяти, время работы процессора, время обращения к внешним устройствам (внешняя память, устройства отображения). Естественно, что эти ресурсы ограничены. Поэтому и требуется определить наилучшую последовательность решения поступивших на обработку вычислительных задач. Процесс определения последовательности решения задач во времени называется планированием. Для того, чтобы осуществить планирование, необходимо знать, какие ресурсы и в каком количестве требует каждая из поступивших задач. Анализ потребности задачи в ресурсах производится на основе ее программы решения. Программа состоит, как правило, из ограниченного набора процедур (по крайней мере, к этому стремятся) с известными для данной ВС затратами ресурсов. После анализа поступивших программ решения задач становится ясно, какая задача требует каких ресурсов, и в каком объеме. Наличие этих данных позволяет перейти к планированию вычислительного процесса. Критерии, используемые при планировании, зависят от степени определенности алгоритмов решаемых задач. Крайними случаями являются: а) порядок использования устройств ЭВМ при решении задач строго задан их алгоритмами; б) порядок использования устройств ВС в задачах заранее не известен. Для первого случая приемлемым является критерий минимизации суммарного времени решения вычислительных задач, для второго - максимизации загрузки устройств ВС.
Рассмотрим модель планирования вычислительного процесса при минимизации суммарного времени [28].
Обозначим ресурсы вычислительной системы (ВС) через R1, R2, …,Rn. Каждая программа решения задачи обработки данных включает типовые процедуры из набора П1, П2, …,Пm. Тогда матрица T ресурсозатрат, приведенных к времени, будет выглядеть, так 
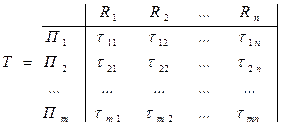 ,
,
где 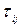 - затраты j-го ресурса при выполнении i-й процедуры, i=1,...., m; j=1,...., n. Знание матриц ресурсозатрат при выполнении программ позволяет вычислить суммарные затраты каждого из ресурсов по всем программам решения вычислительных задач, поступивших в ВС, и составить их матрицу ресурсозатрат. Обозначим поступившие в ВС программы решения задач через З1, З2, …,Зm; tij - затраты j- го ресурса, приведенного к времени, на выполнение i - й задачи (i=1,....,m; j=1,....,n); R1, R2, …,Rm - ресурсы ВС. Матрица ресурсозатрат по задачам запишется в виде
- затраты j-го ресурса при выполнении i-й процедуры, i=1,...., m; j=1,...., n. Знание матриц ресурсозатрат при выполнении программ позволяет вычислить суммарные затраты каждого из ресурсов по всем программам решения вычислительных задач, поступивших в ВС, и составить их матрицу ресурсозатрат. Обозначим поступившие в ВС программы решения задач через З1, З2, …,Зm; tij - затраты j- го ресурса, приведенного к времени, на выполнение i - й задачи (i=1,....,m; j=1,....,n); R1, R2, …,Rm - ресурсы ВС. Матрица ресурсозатрат по задачам запишется в виде
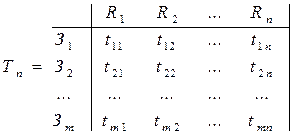 .
.
В вычислительной системе чаще всего ресурсы используются последовательно. Поэтому на основе матрицы Tn можно выделить последовательность прохождения через обработку задач, которая минимизирует суммарное время. Одним из методов нахождения такой последовательности, то есть планирования, является метод решения задачи Джонсона [39], относящийся к теории расписаний и дающий эффективный и строгий алгоритм. При этом учитываются следующие ограничения:
1) для любого устройства ВС выполнение последующей вычислительной задачи не может начаться до окончания предыдущей;
2) каждое устройство в данный момент может выполнять только одну вычислительную задачу;
3) начавшееся выполнение задачи не должно прерываться до полного его завершения.
Если в процессе обработки данных используется „n“ устройств (ресурсов) ВС, нахождение оптимальной последовательности поступающих на решение „m“ задач, минимизирующих суммарное время обработки, потребует перебора (m!)n вариантов. Например, если в ВС поступило всего 6 заданий (m=6), использующих всего 2 ресурса (n=2), то для нахождения оптимальной последовательности, после составления матрицы Tn, потребуется произвести (6!)2 переборов, т.е. 518400. Если же m=10, то потребуется порядка 1013 переборов. Ясно, что даже для ЭВМ это многовато.
Алгоритм Джонсона, полученный для n=2, требует перебора только m(m+1)/2 вариантов. То есть для нашего примера (m=6) необходимо будет проделать 21 перебор, что значительно меньше, чем 518400. При n>2, задачу планирования по критерию минимума суммарного времени обработки, сводят к задаче Джонсона путем преобразования матрицы Tn. Например, если n=3 (то есть три ресурса), то производится попарное сложение первого и второго, второго и третьего столбцов, и таким образом получают двухстолбцовую матрицу Tn. После преобразования следует проверить, выполняются ли вышеперечисленные условия. Если это не так, то задача планирования не имеет строгого решения, и используют эвристические алгоритмы.
Для пояснения алгоритма Джонсона представим матрицу Tn как двухстолбцовую:
 .
.
Алгоритм Джонсона состоит в следующем :
1. В матрице Tn определяется tmin = min{t11, t12, …,tm2}.
2. Из задач З1, …,Зm выбираются задачи, для которых ресурсоемкость хотя бы по одному устройству была равна tmin , т.е. выбирают задачи Зi, у которых хотя бы одна из двух tij= tmin . (Напомним, что i- это номер задачи, j- номер устройства, i=1,...., m , j=1;2 ).
3. Задачи группируют по минимальному времени их исполнения tmin на первом и втором устройствах, т.е. Зi(tmin, ti2) и Зi(ti1, tmin).
4. В начало последовательности обрабатываемых задач ставят Зi(tmin, ti2) в конец - Зi(ti1, tmin).
5. Вставленные в последовательность задачи исключаются из матрицы Tn.
6. Для новой матрицы повторяются пункт (1-3).
7. Задачи Зi(tmin, ti2), Зi(ti1, tmin), полученные из новой матрицы, ставятся в середину составленной ранее последовательности и т. д.
В основе эвристических алгоритмов лежат процедуры выбора из поступивших задач наиболее трудоемких и расположения их в порядке убывания времени выполнения.
При планировании по критерию максимума загрузки устройств вычислительной системы, матрицы ресурсоемкости преобразуются в матрицы загрузки устройств. Из этих матриц формируют по каждому устройству потоки задач, выборки их которых позволяют сформировать оптимальную последовательность задач, подлежащих обработке.
Реализация функций и алгоритмов планирования вычислительного процесса происходит с помощью управляющих программ операционной системы ВС. Программа планировщик определяет ресурсоемкость каждой поступившей на обработку задачи и располагает их в оптимальной последовательности. Подключение ресурсов в требуемых объемах к программам выполнения задач осуществляет по запросу планировщика управляющая программа супервизор, которая тоже входит в состав операционной системы.
Таким образом, одной из важнейших процедур информационного процесса обработки данных является организация вычислительного процесса, которая выполняет функции обслуживания поступающих на обработку заданий (очередей) и планирования (оптимизации последовательности) их обработки. На программно-аппаратном уровне эти функции выполняют специальные управляющие программы, являющиеся составной частью операционных систем, то есть систем, организующих выполнение компьютером операций обработки данных. Разнообразие методов и функций, используемых в алгоритмах организации вычислительного процесса, зависит от допустимых режимов обработки данных в ВС. В наиболее простой ВС, такой как персональный компьютер (ПК), не требуется управление очередями заданий и планирование вычислительных работ. В ПК применяют, в основном однопрограммный режим работы. Поэтому их операционные системы не имеют в своем составе программ диспетчерирования, планировщика и супервизора. Но в более мощных ЭВМ, таких как серверы и, особенно, мэйнфреймы, подобные управляющие программы оказывают решающее влияние на работоспособность и надежность ВС. Например, к UNIX-серверам могут обращаться с заданиями одновременно сотни пользователей, а к мэйнфреймам типа S/390-тысячи.
Дата добавления: 2015-11-06; просмотров: 1907;