Принцип работы технологии Hyper-Threading в процессорах фирмы Intel
Технология Hyper-Threading позволяет организовать два логических ядра в одном физическом. С точки зрения операционной системы в системе существует два ядра, что дает возможность распределять потоки между ними. Технология Hyper-Threading позволяет одновременно обрабатывать два различных приложения или два различных потока одного приложения и тем самым увеличить количество команд, выполняемых ядром в секунду, что сказывается на росте его производительности.
В конструктивном плане ядро с поддержкой технологии Hyper-Threading состоит из двух логических ядер, каждое из которых имеет свои архитектурные регистры и контроллер прерываний. А значит, два параллельно выполняемые потока работают со своими собственными независимыми архитектурными регистрами и прерываниями, но при этом используют совместно ресурсы ядра для выполнения своих задач. После активизации каждое из логических ядер может самостоятельно и независимо от другого ядра выполнять свой поток, обрабатывать прерывания либо блокироваться. Таким образом, от реальной одноядерной конфигурации эта технология отличается только тем, что оба логических ядра используют одни и те же исполнительные ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и оперативную память. Использование двух логических ядер позволяет увеличить параллелизм на уровне потока, реализованный в современных операционных системах и высокоэффективных приложениях. Команды от выполняемых параллельно потоков одновременно посылаются для обработки в подсистему обработки ядра.
У ядра с технологией Hyper-Threading предусмотрены два основных режима работы: Single-Task (ST) и Multi-Task (MT). В режиме ST активным является только одно логическое ядро, которое безраздельно пользуется доступными ресурсами, другое логическое ядро остановлено командой HALT. При появлении второго программного потока бездействовавшее логическое ядро активируется (посредством прерывания), и физическое ядро переводится в режим работы с двумя потоками.
На рис. 33.4 представлена структура ядра Haswell.
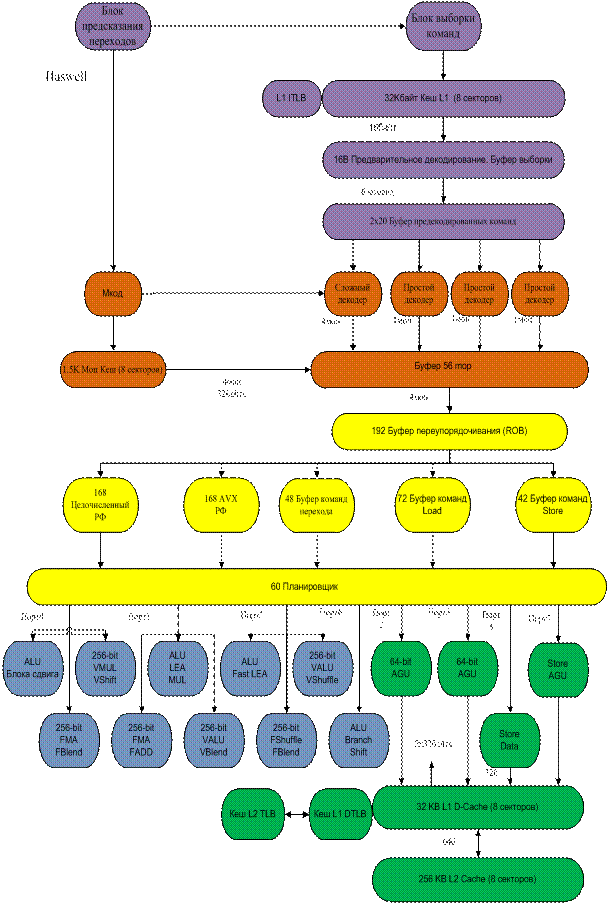
Рис. 33.4. Структура ядра Haswell
При работе двух потоков поддерживаются две очереди команд. Большая часть команд берется из кэш-памяти дешифрированных команд L0m, где они хранятся в декодированном виде. Доступ к кэш-памяти дешифрированных команд L0m два активных логических ядра получают поочередно, через такт. В то же время, когда активно только одно логическое ядро, оно получает монопольный доступ к кэш-памяти дешифрированных команд Lom без чередования по тактам.
Блоки выборки и трансляции команд (в том числе и ITLB - Instruction Translation Look-aside Buffer) действуют при отсутствии необходимых команд в кэш-памяти команд и доставляют команды, каждый для своего потока. Блок декодирования команд (Instruction Decode) является разделяемым и в случае, когда требуется декодирование команд для обоих потоков, обслуживает их поочередно (через такт).
Блоки очереди декодированных команд (Uop Queue) и блок распределения команд по исполнительным устройствам (Allocator) разделяются, отводя по половине элементов для каждого логического ядра. Планировщики (Schedulers) обрабатывают очереди декодированных команд, независимо от принадлежности их к какому либо потоку, и направляют команды на выполнение нужным исполнительным устройствам в зависимости от готовности к выполнению команд и доступности исполнительных устройств.
Кэш-память всех уровней является полностью разделяемой между двумя логическими ядрами, но для обеспечения целостности данных записи в буфер данных (DTLB - Data Translation Look-aside Buffer) снабжаются дескрипторами в виде идентификатора (ID) каждого логического ядра.
Кэш-память L0m содержит уже декодированные команды. Большинство команд при реальной работе ядра декодировано заранее и находится в кэш-памяти L0m. Кэш-память L0m не дублируется для каждого из логических ядер, а разделяется между ними. Тем не менее, у каждого логического ядра существует свой собственный блок, ссылающийся на следующую команду для выполнения. Команды из кэш-памяти L0m выбираются по очереди и становятся в очередь выборки, также индивидуальную для обоих логических ядер.
При отсутствии очередной команды в кэш-памяти L0m, являющемся по своей иерархии кэш-памятью первого уровня для команд, ядро должно декодировать очередную x86 команду из кэш-памяти команд первого уровня (L1К). Выборка команды осуществляется при участии блока трансляции адреса команд (Instruction Translation Lookaside Buffer- ITLB), переводящем виртуальный адрес, хранящийся в кэш-памяти L0m, в физический адрес. ITLB является также индивидуальным для каждого ядра, а кэш-память команд L1К разделяется между логическими ядрами. Декодер x86 команд в ядрах с технологией Hyper-Threading общий, поскольку его загрузка невелика – большинство декодированных команд уже хранится в кэш-памяти L0m. Если же оба логических ядра обращаются к декодеру одновременно, он чередует свою работу между логическими ядрами, но только после выполнения полного цикла для одного из логических ядер. Декодированные команды записываются в кэш-память L0m.
К исполнительным устройствам декодированные последовательности команд приходят в двух очередях – своя очередь для каждого из логических ядер. В первую очередь команды из двух входящих очередей проходят через блоки выделения ресурсов (Allocator) и переименования регистров (Register Rename). Здесь происходит выделение необходимых ресурсов для выполнения команд. Физические регистры и буферы делятся поровну между логическими ядрами, однако, при отказе одного из логических ядер от использования тех или иных ресурсов, они могут быть всецело выделены только одному логическому ядру. После прохождения этой стадии команды попадают в две отсортированные очереди – для операций с памятью и для остальных операций, которые также разделены пополам – для каждого из логических ядер.
Затем, рассортированные микрооперации приходят на стадию определения очередности выполнения – в планировщики (Scheduling), где выполняется сортировка порядка следования команд при поступлении на функциональные исполнительные устройства. Операции на блоки-планировщики приходят по мере поступления. При необходимости, планировщики переключаются с очередей одного логического ядра на очереди другого. На этом этапе, кстати, происходит окончательное смешение микроопераций, приходящих с логических ядер, для возможности их одновременного выполнения. Поскольку физические регистры физического ядра к этому моменту оказываются жестко привязанными к архитектурным регистрам обоих логических ядер, выполнение команд действительно становится возможным без разбора принадлежности команд к потоку. После этапа выполнения, на котором не различаются потоки (и, соответственно выполняющие их логические ядра), следует блок восстановления (Retirement), где восстанавливается изначальный порядок команд и их принадлежность к каждому из логических ядер. При этом буфер восстановления порядка (Re-Order Buffer) делится пополам между логическими ядрами. Хотя кэш-памяти первого и второго уровня являются общими (разделяемыми) для логических ядер, буфер трансляции данных (Data Translation Lookaside Buffer - DTLB), сопоставляющий виртуальные адреса данных и их физические адреса, хоть и делится между ядрами, но записи в нем дополнены идентификатором ядра, которому принадлежит каждая из строк буфера. Таким образом, технология Hyper-Threading действительно позволяет загрузить функциональные исполнительные устройства ядра значительно лучше за счет одновременного выполнения двух потоков.
Подсистема памяти ядер процессоров фирмы Intel, начиная со структуры Sandy Bridge, обслуживает два запроса за такт на чтение, и один запрос на запись в кэш-память данных первого уровня (L1D).
Технология Hyper-Threading обеспечивает дополнительную производительность, но также сказывается и на энергопотреблении. Приложения с интенсивной многопоточной нагрузкой обычно могут выигрывать от нескольких виртуальных ядер и одновременного выполнения нескольких потоков. В отличие от обычных программ, которые в той или иной степени оптимизированы под использование нескольких ядер.
Некоторые данные, иллюстрирующие эффективность технологии SMT, приведены на рис. 33.5.
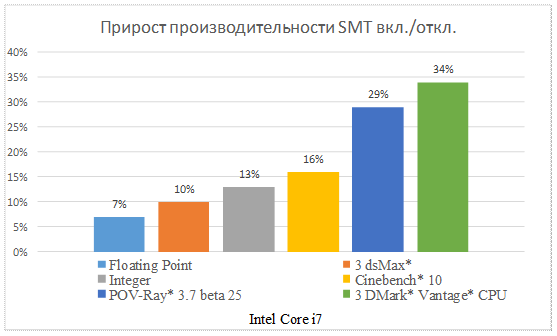
Рис. 33.5. Эффективность технологии SMT
Однако, следует понимать, что эффект от технологии Hyper-Threading не всегда может быть положительным.
Можно говорить о том, чтов среднем прирост производительности в многозадачных средах от использования Hyper-Threading составляет порядка 10-20%.
Контрольные вопросы
1. По какому закону увеличивается количество транзисторов в микросхеме?
2. Сколько транзисторов содержат современные процессора для ПК?
3. Какие частоты работы современных процессоров для ПК?
4. Почему нецелесообразно использовать новые ресурсы транзисторов в микросхеме для повышения производительности одноядерного процессора?
5. В чем проявляются преимущества многоядерности процессоров?
6. Что определяет закон Амдала?
7. В чем состоят трудности параллельного программирования?
8. Что такое виртуальная многопоточность?
9. Какие существуют варианты виртуальной многопоточности?
10. Какие особенности технологии Hyper Threading?
11. Как изменяется производительность ядра с технологией Hyper Threading?
Дата добавления: 2015-09-29; просмотров: 1153;