Разомкнутые схемы моделей.
РАЗОМКНУТЫЕ И ЗАМКНУТЫЕ СХЕМЫ МОДЕЛЕЙ
План лекции
1. Разомкнутые и замкнутые модели
2. Разомкнутые схемы моделей.
3. Особенности замкнутых моделей информационных систем
Разомкнутые и замкнутые модели
Использование предложенной концепции имитационного моделирования позволяет разрабатывать два типа моделей: разомкнутые и замкнутые (так же, как и в теории стохастических сетей).
Разомкнутые модели позволяют сравнительно легко реализовать исследование внутренних процессов в фирме, но они не учитывают взаимосвязи с объектами внешней среды: рынком, госбюджетом, населением и другими.
Замкнутые модели выглядят сложнее (в смысле графа стохастической сети), но позволяют учесть влияние внешней среды и исследовать связь объекта экономики с другими объектами, финансово-кредитными учреждениями, рынком.
Модель состоит из двух характерных частей: секции инициализации
и блока описания стохастической сети. Все рассматриваемые ниже операторы - это программные функции, управляемые соответствующими аргументами.
Разомкнутые схемы моделей.
Относительно топологии можно рассматривать два типа структурных схем моделей: разомкнутые и замкнутые.
Рассмотрим пример разомкнутой модели «Эффективность компьютеров в АРМ бухгалтерии» (ветвление с использованием параметров транзактов)
Рассмотрим в несколько упрощенном изложении процесс обработки бухгалтерской информации в фирме с помощью экономической информационной системы, работающей в бухгалтерии. Такие системы часто называются автоматизированным рабочим местом (АРМ). Далее попытаемся создать структурную схему АРМ бухгалтерии и имитационную модель, соответствующую этой схеме.
В бухгалтерии выделим три подразделения (рис. 8.4):
• группа бухгалтеров в рабочей комнате бухгалтерии;
• архив, где документы, обработанные на компьютере, подшиваются в архивные папки;
• компьютерное подразделение, работающее в компьютерном зале бухгалтерии.
В рабочей комнате N бухгалтеров (N>1) готовят независимо друг от друга различные документы, которые направляются в компьютерный зал для дальнейшей подготовки или обработки. В этом зале имеется один столик, на котором каждый документ находится до того, как оператор возьмет его на обработку. На таком столике может возникнуть очередь документов, ожидающих обработки.
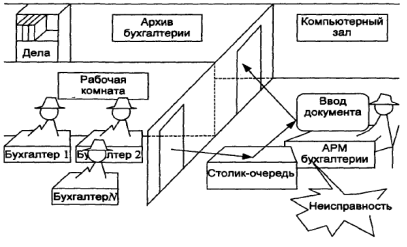
Рис. 8.4. Иллюстрация потока бухгалтерских документов
Обработка выполняется оператором, находящимся за компьютером, в течение какого-то интервала времени. Если в компьютерном зале несколько компьютеров, объединенных в сеть, то за каждым компьютером должен быть свой оператор. Общее число компьютеров М (М>1). Обработанные (или распечатанные) на компьютере документы поступают в архив. Состав сотрудников архива нас не интересует.
Обработка документов затруднена по причине возникновения неисправностей в компьютере. Поэтому в компьютерном зале следующий состав сотрудников:
• один оператор за каждым компьютером;
• один наладчик, который приводит компьютеры в рабочее состояние после возникновения неисправностей и делает ежедневную профилактику каждого компьютера в конце каждого рабочего дня.
В качестве неисправности будем рассматривать любое событие, приводящее компьютер в нерабочее состояние в течение рабочего дня: выход из строя микросхемы, необходимость замены картриджа в печатающем устройстве, неисправность монитора, клавиатуры и ряд других. В любом случае после возникновения неисправности обработка документа с номером к прерывается, после чего вместо оператора за компьютером находится наладчик, который в течение какого-то интервала времени приводит компьютер в рабочее состояние.
После ремонта компьютера оператор продолжает обработку документа с номером к (полагаем, что программное обеспечение позволяет не начинать обработку документа заново).
При организации работы такой экономической информационной системы возникают два вопроса:
1) сколько компьютеров необходимо для того, чтобы справиться с потоком документов в бухгалтерии?
2) сколько времени будет находиться документ, поступивший из рабочей комнаты, на столике в компьютерном зале, прежде чем его возьмет оператор на обработку?
Рассмотрим три основные причины, по которым компьютеры не смогут справиться с обработкой документов. Введем обозначения: tа - средний интервал времени между двумя последовательными поступлениями документов из двери рабочей комнаты на столик в компьютерном зале; ts - средний интервал времени обработки документа оператором на компьютере.
Первая причина, по которой компьютеры не справятся с обработкой потока документов, это высокая интенсивность потока:

Будем предполагать, что владелец фирмы достаточно хорошо владеет арифметическими расчетами, чтобы выбрать столько компьютеров, сколько необходимо для обработки потока.
Вторая причина заключается в том, что даже при выполнении соотношения
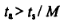
интервал поступления и интервал обработки - это случайные величины, которые имеют значительные отклонения от средних значений.
Третья причина - это ремонт компьютера в связи с неисправностями, возникающими в случайные моменты времени. Необходимый ремонт увеличивает разброс времени обработки документов и является дополнительной причиной снижения пропускной способности компьютера.
Если допустить, что в зале один компьютер и количество бухгалтеров велико ( т.е. N» 1), то можно считать поток документов простейшим, интервал поступления - случайной величиной, распределенной по экспоненциальному закону, а интервал обслуживания - случайной величиной, распределенной по любому закону со среднеквадратичным отклонением, обозначенным через с. ^
При таких допущениях можно применить точную формулу Поллачека-Хинчина и оценить среднее время задержки документа на столике tq. Следует отметить, что при произвольном числе компьютеров Л^> 1 также можно найти аналитическое решение для определения времени tq.
В нашем случае применение методов исследования операций становится невозможными по двум причинам: во-первых, число бухгалтеров не йожет быть большим и, во-вторых, присутствует фактор неисправности. Если попытаться создать математическую модель с помощью, например, аппарата вложенных цепей Маркова (метод Кендалла) или аппарата полумарковских процессов, то придется ввести большое число допущений, которые сделают погрешность метода при определении tq крайне большой (буквально «плюс-
минус в несколько раз»).
Обе отмеченные причины приводят к тому, что от построения математической модели приходится отказаться. Поэтому будем применять метод имитационного моделирования.
В аспекте системного анализа можно представить модель «АРМ бухгалтерии» в виде «черного ящика» и выделить параметры четырех потоков (два входных и два выходных):
• входного потока документов;
• входного потока неисправностей;
• обработанного потока документов;
• потока устраненных неисправностей.
Структурный анализ данной системы довольно просто закончить уже на втором слое. Рассмотрим возможную схему модели (рис. 8.5).
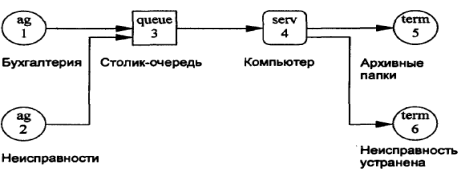
Рис. 8.5. Структурная схема модели «АРМ бухгалтерии»
Каждый бухгалтерский документ, исходящий из рабочей комнаты, будем считать неприоритетным транзактом. Тогда все бухгалтеры - это один генератор транзактов бесконечной емкости (узел 1 модели ag).
Представим неисправности в виде особых транзактов, которые могут занять компьютер, прервав обработку документа – неприоритетного транзакта. Для этого необходимо ввести в рассмотрение второй генератор транзактов бесконечной емкости (узел 2 модели ag).
Столик-очередь представим в виде узла типа очередь (узел 3 модели queue). Будем считать, что документы забираются со столика в хронологическом порядке по принципу «первый пришел – первым обслужен», т.е. оператор берет нижний документ, если вновь поступающие документы помещаются сверху на пачке необработанных документов.
Документы обрабатываются на одном (или нескольких) компьютере.
Процесс обработки представим в виде узла – обслуживающего прибора (узел 4 модели serv). Обслуживающий прибор имеет М независимых каналов обслуживания (М >1). Логично допустить, что каждый канал - это компьютер со своим оператором, обрабатывающим документы. Канал занят, если соответствующий оператор взял документ и обрабатывает его. Архив представим в виде особого узла - терминатора, в который транзакты входят и в нем остаются (узел 5 модели term).
Рассмотрим путь транзакта - неисправности. Такой нематериальный транзакт выходит из второго генератора. Этот транзакт должен обладать абсолютным приоритетом по сравнению с транзактом - документом. Если на столике находятся несколько документов, то неисправность их «отодвигает», проникает в компьютер, и если на АРМ проходила обработка документа, то транзакт-неисправность прерьшает эту обработку. Прерванный транзакт-документ после этого попадает в специальный накопитель (стек), где находится до тех пор, пока не будет отремонтирован компьютер.
По завершении ремонта транзакт-неисправность будет направлен в особый узел модели - терминатор (узел 6 модели term), в котором он уничтожается, а прерванный транзакт-документ возвращается из стека, и обработка его будет продолжена.
Средний интервал времени между двумя последовательными неисправностями - это случайная величина со средним значением te.
Транзакт - неисправность должен попасть на столик-очередь, отодвинуть все транзакты-документы, если они есть в очереди, войти в канал обслуживающего прибора и вытеснить из него транзакт- документ в особое хранилище. Наладчик должен заняться ремонтом соответствующего канала-компьютера. Через некоторое время, которое является случайной величиной со средним значением tr, наладчик починит компьютер. Это означает, что транзакт-неисправность должен покинуть канал обслуживающего прибора и уйти в особый узел-терминатор (узел 6 модели term), так как в архив такой транзакт, естественно, поступать не может. В этот же момент времени транзакт-документ, обработка которого была прервана из-за неисправности, извлекается из хранилища, и обработка его продолжается.
В соответствии с предельной теоремой о суперпозиции потоков событий, а также учитывая, что в компьютере может быть несколько сотен независимых потоков элементарных неисправностей, будем считать, что интервал между двумя последовательными неисправностями распределен по экспоненциальному закону (значение соответствующего параметра - expo).
Если допустить, что в бухгалтерии работает не менее трех сотрудников, которые могут подготавливать информацию для обработки, и характер их работы приблизительно одинаков, то в качестве закона распределения интервала поступления документов выбираем экспоненциальный закон (значение соответствующего параметра - также expo). Следует отметить, что если это допущение не выполняется, то можно выбрать и любой другой закон.
Длительность ремонта компьютера всегда можно представить в виде суммы длительностей многочисленных элементарных операций - случайных величин, распределенных по произвольному закону. Поэтому в соответствии с центральной предельной теоремой будем считать, что эта длительность распределена по нормальному закону (значение соответствующего параметра - norm). Если допустить, что процесс обработки оператором одного документа также можно представить в виде последовательности многочисленных элементарных операций и длительность каждой элементарной операции распределена по произвольному закону, то можно считать, что интервал обработки одного документа - это величина, распределенная по нормальному закону (значение соответствующего параметра - также norm).
Транзакты можно различать по значению приоритета. Например, если транзакт-документ неприоритетный, то значение его приоритета обозначается попе; а если транзакт-неисправность имеет приоритет 1, то это число можно сразу определить. Приоритет транзакта хранится в нем самом.
Результаты моделирования показаны в табл. 8.2, получаемой с помощью компьютера.
Таблица 8.2
Дата добавления: 2015-08-21; просмотров: 1580;