Автоматический статический анализ программ
Статические анализаторы программ – это инструментальные программные средства, которые сканируют исходный текст программы и выявляют возможные ошибки и противоречия. Для анализаторов не требуется исполняемая программа. Они выполняют синтаксический разбор текста программы и опознают различные типы операторов. Таким образом, с помощью анализаторов можно проверить, правильно ли составлены операторы, сделать выводы относительно потока управления в программе и во многих случаях вычислить множество значений данных, используемых программой. Анализаторы дополняют средства обнаружения ошибок, предоставляемых компилятором языка.
Цель автоматического статического анализа – привлечь внимание проверяющего к аномалиям в программе, например к переменным, которые используются без инициализации или совсем не используются, или к данным, значения которых превышают заданное, и т.п.
Статический анализ состоит из нескольких этапов.
1. Анализ потока управления. На этом этапе идентифицируются и выделяются циклы, их точки входа и выхода, а также неиспользуемый код (это код, окруженный безусловными операторами перехода, или код одной из ветвей условного оператора, условие перехода к которой никогда не будет истинным).
2. Анализ использования данных. На этом этапе проверяется использование переменных в программе. Анализ позволяет обнаружить переменные, которые используются без предварительной инициализации, переменные, которые описаны дважды без промежуточного присвоения, а также объявленные, но нигде не используемые переменные. На этом этапе также можно выявить условные операторы с избыточными условиями. Это такие условия, значения которых никогда не изменяются: они либо всегда истинны, либо всегда ложны.
3. Анализ интерфейса. На этом этапе проверяется согласованность различных частей программы, правильность объявления процедур и их использования. Данный этап оказывается лишним, если используется язык со строгим контролем типов, например Java, так как подобный анализ выполняет компилятор этого языка. Анализ интерфейса помогает выявить ошибки в программах, написанных на языках со слабым контролем типов, например FORTRAN или С. В процессе анализа интерфейса можно также выявить объявленные функции и процедуры, которые нигде не вызываются, и функции, результаты которых не используются.
4. Анализ потоков данных. На этом этапе анализа определяются зависимости между исходными (входными) и результирующими (выходными) переменными. Хотя такой анализ не выявляет конкретных ошибок, он дает полный список значений, используемых в программе, благодаря чему легче обнаружить ошибочный вывод данных. На этом этапе также можно явно определить условия, которые влияют на значения переменных.
5. Анализ ветвей программы. На этом этапе семантического анализа определяются все ветви программы и выделяются операторы, исполняемые в каждой ветви. Анализ ветвей программы существенно помогает разобраться в управлении программой и позволяет проанализировать каждую ветвь отдельно.
Анализ потока данных ианализ ветвей генерируют огромное количество информации. Эта информация не выявляет конкретных ошибок, а представляет программу в разных аспектах. Из-за огромного количества генерируемой информации эти этапы статического анализа иногда исключают из процесса анализа и используют только на ранних стадиях для обнаружения аномалий в разрабатываемой программе.
Статические анализаторы особенно полезны в тех случаях, когда используются языки программирования, подобные С. В языке С нет строгого контроля типов, и потому проверка, осуществляемая компилятором языка С, ограниченна. В этом случае средствами статического анализа можно автоматически выявить широкий спектр ошибок программирования. Данный анализ особенно важен при разработке критических систем. В этом случае статический анализ позволяет значительно сократить расходы на тестирование. В системах Unix и Linux есть статический анализатор LINT для программ, написанных на С. Он обеспечивает статическую проверку, эквивалентную проверке компилятором в языках со строгим контролем типов, например Java.
20.4. Метод "чистая комната"
При разработке ПО методом "чистая комната" (cleanroom) для устранения дефектов используется процесс строгого инспектирования. Цель данного метода– создание ПО без дефектов. Название "чистая комната" взято по аналогии с производством кристаллов полупроводников, где выращивание кристаллов без дефектов происходит в сверхчистой атмосфере (чистых комнатах).
На рис. 20.5 представлена модель процесса разработки ПО методом "чистая комната".
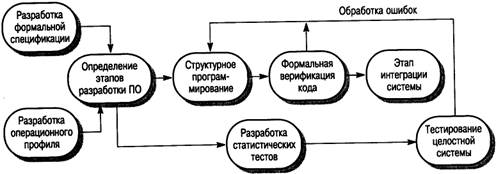
Рис. 20.5. Процесс разработки ПО методом "чистая комната"
В разработке ПО методом "чистая комната" можно выделить пять ключевых моментов:
1. Формальная спецификация. Длясоздаваемой системы разрабатывается формальная спецификация. Для записи спецификации используется модель состояний, в которой отображены отклики системы на стимулы.
2. Пошаговая разработка. Разработка ПО разбивается на несколько этапов, которые выполняются и проверяются методом "чистая комната" независимо друг от друга. Этапы определяются совместно с заказчиком на ранних стадиях процесса создания программного продукта.
3. Структурное программирование. Используется только ограниченное количество управляющих конструкций и абстракций данных. Процесс разработки программы – это процедура поэтапной детализации спецификации.
4. Статическая верификация. Разрабатываемое ПО проверяется статическим методом строгого инспектирования ПО. Для модулей или отдельных элементов тестирование кода не проводится.
5. Статистическое тестирование системы. На каждом шаге разработки проводится тестирование статистическими методами, позволяющими оценить надежность программной системы. Как показано на рис. 20.5, статистические тесты базируются на операционном профиле, который разрабатывается параллельно созданию спецификации системы.
Процесс разработки ПО методом "чистая комната" планируется таким образом, чтобы обеспечить строгое инспектирование программ. Спецификация системы представлена моделью состояний, которая через ряд последовательных моделей постепенно преобразуется в исполняемую программу. Инспектирование программ дополняются строгими математическими доказательствами согласованности и корректности преобразований.
Обычно разработкой больших систем методом "чистая комната" занимаются три группы разработчиков.
1. Группа спецификации. Отвечает за разработку и поддержку системной спецификации. Этой группой создаются спецификации пользовательских требований и формальные спецификации для верификации системы. В некоторых случаях, например после окончания разработки спецификации, эта группа может присоединиться к группе разработки.
2. Группа разработки. Занимается разработкой и проверкой ПО. При проверке используется структурированный формальный подход, основанный на инспектировании кода, подкрепленный доказательством правильности работы системы.
3. Группа сертификации. Занимается разработкой статистических тестов, применяемых после окончания разработки ПО. Все тесты основаны на использовании формальной спецификации. Контрольные тесты разрабатываются параллельно с созданием системы и используются для сертификации надежности ПО.
В результате использования метода "чистая комната" готовый программный продукт содержит крайне мало ошибок и его стоимость меньше, чем у разработанного традиционными методами. В процессе разработки методом "чистая комната" оказывается рентабельной статическая проверка. Огромное количество дефектов обнаруживается еще до исполнения программы и исправляется в процессе разработки ПО. Во время тестирования проектов, которые разрабатывались с использованием метода "чистая комната", в среднем обнаруживается только 2,3 дефекта на тысячу строк исходного кода. В целом расходы на разработку не увеличиваются, так как сокращаются расходы на тестирование и исправление ошибок в разрабатываемой программной системе.
Дата добавления: 2015-08-14; просмотров: 2689;