Индексирование
Индекс представляет собой средство ускорения поиска записей в таблице, а также других операций, использующих поиск: извлечение, модификацию, сортировку и т. д. Таблицу, для которой используют индекс, называют индексированной.
Индекс содержит отсортированную по колонке или нескольким колонкам информацию и указывает на строки, в которых хранится конкретное значение колонки.
Индекс выполняет роль оглавления таблиц, просмотр которого предшествует обращению к записям таблицы.
В некоторых системах индексы хранятся в индексных файлах отдельно от табличных.
Решение проблемы организации физического доступа к информации зависит в основном от следующих факторов:
- вида содержимого в поле ключа записей индексного файла;
- типа используемых ссылок (указателей) на запись основной таблицы;
- метода поиска нужных записей.
Индексный файл — это хранимый файл особого типа, в котором каждая запись состоит из двух значений: данное и RID-указатель.
На практике чаще всего используются два метода поиска: последовательный и бинарный (основан на делении интервала поиска пополам – см. пример ниже).
Поиск необходимых записей при индексации может происходить по одноуровневой либо двухуровневой схеме индексации.
При одноуровневой схеме в индексном файле хранятся короткие записи, имеющие два поля: поле содержимого старшего ключа (хеш-кода ключа) адресуемого блока и поле адреса начала этого блока (рис. 5.1).
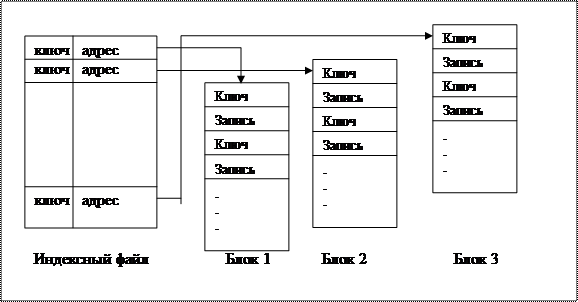 |
Рис. 5.1. Одноуровневая схема индексации
В каждом блоке записи располагаются в порядке возрастания значения ключа (или свертки).
Старшим ключом каждого блока является ключ его последней записи.
Если в индексном файле хранятся хеш-коды ключевых полей индексированной таблицы, то алгоритм поиска нужной записи включает три этапа:
1. Образование свертки значения ключевого поля искомой записи.
2. Поиск в индексном файле записи о блоке, значение первого поля которого больше полученной свертки (это гарантирует нахождение искомой свертки в данном блоке).
3. Последовательный просмотр записей блока до совпадения сверток искомой записи и записи блока файла. В случае коллизий (нескольким разным ключам может соответствовать одно значение хеш-функции, т. е. один адрес) сверток ищется запись, значение ключа которой совпадает со значением ключа искомой записи.
Недостаток одноуровневой схемы — ключи (свертки) записей хранятся вместе с записями, что приводит к увеличению времени поиска записей из-за большой длины просмотра (значения данных в записях приходится пропускать).
В двухуровневой схеме ключи (свертки) записей отделены от содержимого записей (рис. 5.2).
В данном случае индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей.
На практике при создании индекса для некоторой таблицы базы данных указывают поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, называются файлами первичных индексов.
Индексы, создаваемые не для ключевых полей, называются вторичными (пользовательскими) индексами. Введение этих индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, называются файлами вторичных индексов.
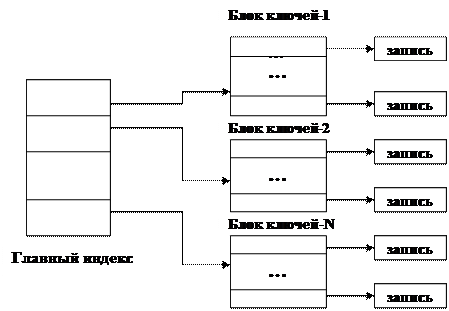 |
Рис. 5.2. Двухуровневая схема индексации
Некоторые СУБД поддерживают кластеризованные и кластеризованные хешированные индексы.
Кластеризация — помещение в один блок записей таблиц, которые с большой вероятностью будут часто подвергаться соединению.
Кластеризованный индекс — специальная техника индексирования, при которой данные в таблице физически располагаются в индексированном порядке. Использование кластеризованного индекса значительно ускоряет выполнение запросов по индексированной колонке. Для каждой таблицы может существовать только один кластеризованный индекс. При создании кластеризованного индекса не по первичному ключу автоматически снимается кластеризация по первичному ключу.
Хеширование — альтернативный способ хранения данных в заранее заданном порядке с целью ускорения поиска (прямой доступ). Хеширование избавляет от необходимости поддерживать и просматривать индексы.
Кластеризованный хешированный индекс значительно ускоряет операции поиска и сортировки, но добавление и удаление строк замедляется из-за необходимости реорганизации данных для соответствия индексу.
Хеширование применяется в том случае, когда необходим прямой доступ (без индексов), например, при бронировании авиабилетов, мест в гостиницах, прокате машин, а также электронных денежных переводах. Однако недостатком хеширования являются необходимость нахождения соответствующей хеш-функции, необходимость выполнения операции свертки (требует определенного времени), возможные коллизии (свертка различных значений может дать одинаковый хеш-код) и промежутки между записями неопределенной протяженности. При хешировании RID-указатель вычисляется с помощью некоторой хеш-функции и называется хеш-кодом. В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (хеш-код). Длина хеш-кода всегда постоянна и имеет достаточно малую величину (например, 4 байта), а это существенно снижает время поисковых операций.
Общим недостатком индексных схем является необходимость хранения индексов, к которым требуется обращаться для обнаружения записей [20, С. 48-52].
Пример индексирования
Исходная таблица.
| Номер записи | Индексированное поле | Неиндексированное поле |
| a | ||
| c | ||
| d | ||
| a | ||
| e | ||
| c | ||
| a | ||
| d | ||
| b |
Индекс.
| Номер записи | Индексированное поле (упорядоченное) |
Если таблица проиндексирована, то все команды, связанные с движением таблицы (на следующую запись, в начало, в конец) перемещают указатель записи в соответствующий с индексом, а не с физическим расположением в исходной таблицы.
При поиске в исходной таблице записи со значением 4, нужно последовательно пройти все предыдущие записи. В худшем случае нужно просмотреть число записей = числу записей в таблице = N.
При индексировании осуществляются специальные алгоритмы поиска. Указатель устанавливается на середину области поиска. Сравниваем искомое значение. Если искомое меньше, то указатель ставится на середину верхней части области. В общем случае максимальное число шагов = log2N.
Тема 6
Дата добавления: 2015-08-08; просмотров: 2103;