Модели доступа к данным.
Помимо разделения баз данных по методам обработки, можно классифицировать их по используемой модели (или структуре) данных. С помощью модели данных можно наглядно представить структуру объектов и установленные между ними связи. Модель данных непосредственно определяет наименование СУБД.

Иерархическая модель. БД состоит из упорядоченного набора древовидных структур данных. Организационные структуры, списки материалов, оглавления в книгах, планы проектов и многие другие совокупности данных могут быть представлены в иерархическом виде. При этом автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя, причём потомок имеет единственного родителя. Недостатком модели является сложность реорганизации данных и невозможность выполнения «горизонтальных» запросов к данным, не связанных с иерархической структурой.
Иерархическая модель появилась первой среди всех даталогических моделей: именно эту модель поддерживала первая из зарегистрированных промышленных СУБД IMS (Information Management System) IBM (1968 год). Каждая физическая база описывается набором операторов, определяющих как её логическую структуру, так и структуру хранения баз данных.
|
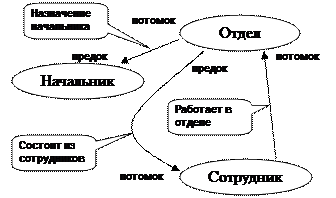 Сетевая модель. Является расширением иерархической модели. Здесь каждый порождённый элемент (потомок) может иметь более одного порождающего элемента (предка). Сетевая БД может представлять непосредственно все виды связей, присущих данным. По этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами. Однако любой запрос к сетевой БД предполагает выработку собственного механизма навигации по этой базе. При этом автоматически целостность данных СУБД не поддерживается.
Сетевая модель. Является расширением иерархической модели. Здесь каждый порождённый элемент (потомок) может иметь более одного порождающего элемента (предка). Сетевая БД может представлять непосредственно все виды связей, присущих данным. По этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами. Однако любой запрос к сетевой БД предполагает выработку собственного механизма навигации по этой базе. При этом автоматически целостность данных СУБД не поддерживается.
Базовыми понятиями модели являются:
Элемент данных – минимальная информационная единица, доступная пользователю с использованием СУБД.
Агрегат – поименованный набор данных. Агрегат данных типа «вектор» - линейный набор элементов данных (например агрегат «Адрес: город, улица, дом, квартира»). Агрегат данных типа «повторяющаяся группа» соответствует совокупности векторов данных. Например, агрегат «Зарплата: месяц, сумма (х 12)».
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Для записи вводятся понятия типа записи и экземпляра записи.
Связьили набор – двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи. Связи именуются. Для любых двух типов записей может быть задано любое количество связей.
Некоторые правила и термины построения сетевой модели:
Тип связи L определяется для типа записи предка P и потомка C. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. При этом (1) каждый экземпляр типа P является предком только в одном экземпляре L; (2) Каждый экземпляр C является потомком не более чем в одном экземпляре L.
Следствия таких правил таковы:
(1) Тип записи С в связи L1 может быть типом записи P в связи L2 (обычная иерархическая модель).
(2) Тип записи P может быть таковым в любом числе типов связи.
(3) Тип записи P может фигурировать как тип записи C в любом числе типов связи.
(4) Может существовать любое число типов связи с одним и тем же типом записи P и типом записи C.
(5) Одни и те же типы записей могут быть предком и потомком в связи L1 и потомком и предком в связи L2.
Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Language), которая определила базовые понятия модели и формальный язык описания. Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc.
Реляционная модель. Основная идея реляционной модели данных заключается в том, чтобы представить любой набор данных в виде двумерной таблицы. В простейшем случае реляционная модель описывает единственную двумерную таблицу, но чаще всего эта модель описывает структуру и взаимоотношения между несколькими таблицами. Реляционная модель не позволяет корректно представить данные, имеющие собственную сложную структуру. Создание реляционных отношений для таких данных может привести к потере значимых связей между данными.
Примеры широко известных реляционных БД: MS FoxPro, MS Access.
Объектно-ориентированная модель. Её структура описывается с помощью трёх ключевых понятий:
- Инкапсуляция – каждый объект хранит в себе набор данных (т.е. обладает некоторым внутренним содержанием) и набор методов, с помощью которых (точнее исключительно с помощью которых) можно получить доступ к данным этого объекта.
- Наследование – подразумевает возможность создавать из классов объектов новые классы объектов, которые наследуют структуру и методы своих предков, добавляя к ним (или исключая) структуру данных и методы, отражающие их собственную индивидуальность.
- Полиморфизм – различные объекты в зависимости от внешних событий могут вызывать одинаково названные методы, но по-разному реализованные.
Особенностью ООБД является невозможность применения к хранимым объектам понятий и алгоритмов реляционной модели. В этой связи необходим некоторый процедурный язык для оформления запросов и обработки данных. Обеспечение целостности данных заключается в (1) автоматической поддержке отношений наследования; (2) возможности объявлять поля и методы объекта как «скрытые» (т.е. невидимые для других объектов); (3) реализовывать процедуры контроля целостности данных внутри объектов.
Примеры ООБД: Caché, FastObjects, GemStone/S, Jasmine, к ним примыкает объектно-реляционная СУБД PostgeSQL.
Дата добавления: 2015-07-30; просмотров: 3033;