ПАРАЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ СИСИТЕМЫ
Повышение производительности ЭВМ приближается к физическим пределам. Время переключения электронных схем достигло долей наносекунд, а скорость распространения сигналов в проводниках физически ограничена значением 30см/нс (скорость света). Поэтому уменьшение времени переключения схем не позволяет существенно повысить производительность ЭВМ.
Альтернативным путем повышения производительности в настоявшее время является реализация принципа параллелизма устройств обработки информации и создания многомашинных и многопроцессорных (мультипроцессорных) ВС.
Второй причиной создания таких систем является необходимость решения проблемы обеспечения высокой надежности и готовности ВС, особенно работающих в системах реального времени.
Известный специалист М.ФЛИН выделил всего две причины порождающие вычислительный параллелизм:
- независимость потоков команд, одновременно существующих в системе
- несвязность данных, обрабатываемых в одном потоке команд.
Наиболее признанной классификацией программного параллелизма считается классификация предложенная П.ТРЕЛИВЕНОМ из университета Ньюкастела.
| Уровни Программного параллелизма | Средства параллельной обработки |
| Независимые задания | Мультипроцессирование |
| Шаги задания и программы | |
| Программы и подпрограммы | |
| Циклы и итерации | Векторная обработка |
| Операторы и команды | Многофункциональная |
| Фазы команд | Конвейер команд |
Если совместить такое ранжирование с категориями Флина "параллельные потоки команд" и " параллельные потоки данных", то можно заметить, что параллелизм первых трех уровней достигается за счет множества независимых командных потоков, а параллелизм последних трех градаций – главным образом за счет несвязных потоков данных.
Конвейер операций. Принцип совмещения операций.
Академик С.А.Лебедев в 2056 г. предложил повышать производительность ЭВМ используя принцип совмещения во времени отдельных операций(этапов, фаз) рабочего цикла и реализовал этот принцип в ЭВМ М-20 в форме параллельного выполнения во времени операций в АЛУ и выборки из памяти следующей команды.
Пусть рабочий цикл процессора состоит из k этапов (фаз), причем i–й этап имеет продолжительность ti. Тогда при последовательном выполнении этапов продолжительность выполнения всей процедуры (команды):
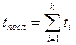 (1)
(1)
а производительность процессора, [операций/с]
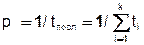 (2)
(2)
Скорость работы машины может быть увеличена, если для выполнения каждого этапа иметь отдельный аппаратный блок и соединить эти блоки в обрабатывающую линию (конвейер операций) так, чтобы результат выполнения в данном блоке некоторого этапа передавался для реализации очередного этапа на следующий блок и т.д. (рис.)
 |
_Синхронный конвейер операций . Если конвейер работает в понудительном темпе и для выполнения любого этапа выделено одно и тоже время - tT (такт конвейера), то такой конвейер называется синхронном.
Разбиение процедуры команды на этапы и выбор длительности такта конвейера производится согласно условиям:
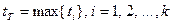 ; (3)
; (3)
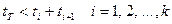 ; (4)
; (4)
причем в силу цикличности рабочего процесса в последнем неравенстве принимаем tk+1= t1
Если для каких-либо смежных этапов второе условие не выполняется, то их следует объединить в один этап, либо самый длинный этап разбить на несколько этапов. В последнем случае заново выбирается tT и вновь проверяются условия (4).
Пример. Команда выполняется последовательностью из пяти этапов (фаз):
1-выборка команды из памяти
2- формирование исполнительных адресов
3- выборка операндов из памяти
4 - выполнение операции в АЛУ
5- запоминание результата в ОЗУ
 |
Временная диаграмма выполнения команд A, B, C, D, E. F. G на 5-ти позиционном синхронном конвейере может быть представлена следующим образом
Одинаковыми символами помечены разные этапы рабочего цикла одной и той же команды. После того как все позиции конвейера окажутся заполненными, параллельно во времени обрабатывается столько команд, сколько в конвейере обрабатывающих блоков.
Конвейер характеризуется коэффициентом совмещения операций, равный числу одновременно выполняемых этапов обработки информации.
Номинальная производительность синхронного конвейера при его полной загрузке:
 (5)
(5)
Найдем отношение производительности процессора при конвейерной обработке и при последовательном выполнении этапов рабочего цикла.
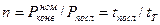
Из (1) и (3) имеем
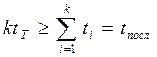 (6)
(6)
а из (1) и (5) получаем:

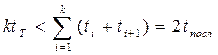 (7)
(7)
Из (6) и (7) получаем
k/2< n ≤ k
Рост реальной производительности ниже из-за простоев (задержек) конвейера. В процедурах (микропрограммах) выполнения некоторых команд ( например пересылки данных) отдельные этапы (фазы) рабочего цикла отсутствуют, и следовательно простаивают отдельные блоки конвейера.
Для команд условного перехода по результату предыдущей команды выборка следующей команды должна быть задержана (конвейер простаивает несколько тактов) пока не будет сформирован признак результата предыдущей операции, который формируется на более позднем этапе.
Наличие в CISC архитектуре команд память-память, для которых характерно существенно большее время выполнения за счет наличия 2-3 фаз обращения к ОЗУ.
Это делает практически невозможной глубокую конвейеризацию арифметики (разбиение на короткие фазы), то есть ограничивается тактовая частота а, следовательно, и производительность процессора.
Это обусловлено следующими факторами:
1. Чем мельче фаза дробления конвейерной обработки, тем выше частота работы процессора.
2.Длина конвейера или количество элементарных фаз в его составе не может быть слишком большим, поскольку мало сделать частоту его работы максимальной - необходимо обеспечить максимальную загрузку конвейера.
3.В идеальном случае процессор должен формировать один результат каждый такт, а для этого количество запущенных на исполнение (и естественно параллельных, независимых) операций должно быть не меньше количества фаз конвейера.
Простейшим примером параллельных и независимых операций является последовательность из двух команд:
A=B+C; D=E*F
Операнды А,В и С первой команды никак не связаны с операндами D,E и F
второй команды.
4.Количество параллельных операций в большинстве программ не велико. Линейные участки программ редко содержат больше 3-5 параллельных команд.
Поэтому добавление в арифметический конвейер длинной цепочки доступа к оперативной памяти (число фаз значительно превысит величину 3-5) неминуемо приведет к низкой эффективности его функционирования, то есть желаемого ускорения такой конвейер не даст.
В RISC-архитектуре эффективность конвейера операций достигается за счет исключения из набора команд процессора формата команд "память-память".
Многофункциональная обработка..
В этой архитектуре каждая команда программы выполняется на соответствующем ей функционально-специализированном устройстве, которые могут работать параллельно, т. е. одновременно.
Для эффективной работы обрабатываемые команды должны быть независимыми, а их состав в динамике счета должен соответствовать составу функциональных устройств.
Типичным примером функционально- магистральной обработки является система CDC 6600 (1964г.), в которой имеется 10 специализированных независимых функциональных устройств.
 |
Суперскалярная обработка.
Является современным развитием архитектуры многофункциональной конвейерной обработки.
В этой архитектуре в аппаратуру процессора закладывается средства, позволяющие одновременно выполнять две или более скалярные операции, то есть команды, каждая из которых обрабатывает пару чисел.
Два способа реализации:
1.Чисто аппаратный механизм выборки команд из буфера (КЭШа) несвязанных команд и параллельный запуск их на исполнение.
Этот метод хорош тем, что "прозрачен" для программиста. То есть составление программ для такого процессора не требует ни каких специальных усилий, вся ответственность за параллельное выполнение команд возлагается на аппаратные средства.
ПРИМЕР: PENTIUM, разработанный на базе суперскалярной RISC-архитектуры, который содержит два пятиступенчатых конвейерных блока исполнения команд, работающих независимо, что позволяет обрабатывать две команды за один такт синхронизации. ( Рис.)
  |
2.Второй способ реализации суперскалярной обработки – коренная перестройка всего процесса трансляции и исполнения программ. На этапе подготовки программ компилятор группирует несвязанные команды (операции) в пакеты, содержимое которых строго соответствует структуре процессора.
Например: если процессор содержит четыре функциональных независимых устройств: - сложения, умножения, сдвига и деления, то максимум, что сможет уложить компилятор в один пакет это четыре разнотипных операции сложения, умножения, сдвига и деления.
Сформированные пакеты операций преобразуются компилятором в командные слова, которые называются "суперкомандами", а соответствующая им архитектура называется - VLIW (Very Large Instruction Word)
Основная идея этой архитектуры заключается в том, что затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, который освобождается от "интеллектуальной" работы по поиску параллелизма несвязанных операций.
Практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции. В настоящее время эта проблема решается совместными усилиями фирм Sun Microsystem и SPARC-центром под руководством проф. Бориса Бабаяна.(Москва)
Векторная обработка.
Во многих программах встречаются циклы, в которых одни и те же операции выполняются многократно. Исследования многочисленных Фортран - программ (Д.Ктутц D.Knuth) показали, что циклы занимают менее 4% кода таких программ, но требуют более половины времени выполнения задачи.
Пример DO 10 i=1,N
10 C(I)=A(I)+B(I)
Обработка такого цикла ЭВМ с архитектурой фон Неймана потребует N сложений элементов векторов А и В, не считая 2N количества команд приращения индекса и условного перехода.
Идея векторной обработки циклов такого рода заключается в том, что в систему команд ЭВМ вводится векторная операция сложения <А+В>, которая задает сложение всех элементов векторов операндов. При этом:
1.Сокращается число выполняемых процессором команд объектного кода, поскольку отпадает необходимость в пересчете индексов и организации условного перехода;
2.Все операции сложения могут быть выполнены одновременно, в силу параллелизма(несвязности) этих операций.
Все рассмотренные ранее архитектуры :конвейер операций и конвейер команд относятся к архитектурам класса SISD(одиночный поток команд и одиночный поток данных)
Векторная обработка тесно связана с понятием множественности потока данных и может быть отнесена к архитектуре класса SIMD (одиночный поток команд и множественный поток данных).
. Этот подход реализуется в системах двух типов: матричных и векторно-конвейерных.
Оба подхода в принципе позволяют достичь значительного ускорения по сравнению со скалярными машинами.
Дата добавления: 2015-07-24; просмотров: 1106;