СОЗДАНИЕ ПРЕДСТАВЛЕНИЙ
Представлением называется именованный запрос на выборку, сохраненный в базе данных. Иногда представления называют “виртуальными таблицами”, содержимое которых определяется запросом. Для пользователя базы данных представление выглядит подобно обычной таблице, состоящей из строк и столбцов. Однако, в отличие от таблицы, представление как совокупность значений в базе данных реально не существует. Строки и столбцы данных, которые пользователь видит с помощью представления, являются результатами запроса, лежащего в его основе. При создании представление получает имя, и его определение сохраняется в базе данных.
Представления используются по нескольким причинам:
- позволяют разным пользователям базы данных видеть структуру таблиц по-разному, в более удобном для них виде;
- ограничивают доступ к данным, разрешая пользователям видеть только некоторые из строк и столбцов таблицы;
- упрощают доступ к базе данных, показывая каждому пользователю структуру хранимых данных в наиболее подходящем для него виде.
Создание представлений. Инструкция CREATE VIEW, синтаксическая диаграмма которой изображена на рисунке, используется для создания представлений. В ней указываются имя представления и запрос, лежащий в его основе. Для успешного создания представления необходимо иметь разрешение на доступ ко всем таблицам, входящим в запрос.
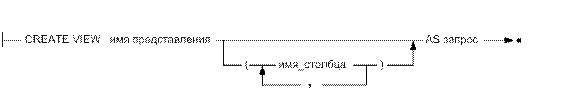
При необходимости в инструкции CREATE VIEW можно задать имя для каждого столбца создаваемого представления. Если указывается список имен столбцов, то он должен содержать столько элементов, сколько столбцов содержится в запросе, причем в списке задаются только имена столбцов; тип данных, длина и другие характеристики берутся из определения столбца в исходной таблице. Если список имен столбцов в инструкции CREATE VIEW отсутствует, каждый столбец представления получает имя соответствующего столбца запроса. Если в запрос входят вычисляемые столбцы или два столбца с одинаковыми именами, то без такого списка обойтись невозможно.
Приведем примеры инструкций, создающих различные виды представлений:
Пример
Создать представление, показывающее информацию о служащих, работающих в отделении компании города Минска.
create view Minsk AS
select * from staff
where bno in (select bno
from branch
where city=‘Минск’);
Это пример создания простого горизонтального представления, т.е. представления которое позволяет видеть в исходной таблице STAFF не все строки, а только те, которые удовлетворяют условию отбора запроса, лежащего в его основе.
Пример
Создать представление, показывающее информацию о ФИО и должности служащих.
create view info AS
select fname, lname, position
from staff;
Это пример создания простого вертикального представления, т.е. представления, ограничивающее доступ к столбцам исходной таблицы.
Пример
Создать представление, включающее избранную информацию обо всех квартирах сотрудника …
create view property AS
select street, area, type, rent
from property_for_rent
where sno = (select sno from staff
where fname=’…’ and lname=’…’);
Конечно, на практике при создании представлений обычно требуется разделять таблицу и по вертикали, и по горизонтали – такие представления получили название смешенных.
Пример
Создать представление с информацией о средней заработной плате сотрудников по каждому отделению.
create view average_salary as
select bno, avg(salary)
from staff
group by bno;
Это пример создания сложного сгруппированного представления. В отличие от горизонтальных, вертикальных и смешанных представлений, каждой строке сгруппированного представления не соответствует какая-то одна строка исходной таблицы. Сгруппированное представление не является просто фильтром исходной таблицы, скрывающим некоторые строки и столбцы. Оно отображает исходную таблицу в виде резюме, поэтому поддержка такой виртуальной таблицы требует от СУБД значительного объема вычислений и отслеживания проблем с обновлением.
Когда СУБД встречает в инструкции SQL ссылку на представление, она отыскивает его определение, сохраненное в базе данных, преобразует пользовательский запрос, ссылающийся на представление, в эквивалентный запрос к исходным таблицам представления, и выполняет этот запрос. Таким образом, СУБД создает иллюзию существования представления в виде отдельной таблицы и в то же время сохраняет целостность исходных таблиц.
Если определение представления простое, то СУБД формирует каждую строку представления "на лету", извлекая данные из исходных таблиц. Если же определение сложное, СУБД приходится материализовывать представление. Это означает, что СУБД выполняет запрос, определяющий представление, и сохраняет его результаты во временной таблице. Из нее СУБД берет данные для формирования результатов пользовательского запроса, а когда временная таблица становится ненужной, удаляет ее. Но независимо от того, как СУБД выполняет инструкцию, являющуюся определением представления, для пользователя результат будет одним и тем же. Ссылаться: на представление в инструкции SQL можно так же, как если бы оно было реальной таблицей базы данных. Так после определения представления к нему можно обращаться с помощью инструкции SELECT как к обычной таблице:
select * from average_salary;
Также можно изменять, удалять или добавлять данные, определять права доступа, т.е. проделывать практически все допустимые для таблиц операции.
Преимущества использования представлений. В локальных БД на персональных компьютерах представления применяются для удобства и позволяют упрощать запросы. В промышленных базах данных представления играют главную роль в создании собственной структуры базы данных для каждого пользователя и обеспечении ее безопасности. Основные преимущества представлений:
- Безопасность. Каждому пользователю можно разрешить доступ к небольшому числу представлений, содержащих только ту информацию, которую ему позволено знать (примеры горизонтальных и вертикальных представлений). Таким образом, можно осуществить ограничение доступа пользователей к хранимой информации.
- Простота запросов. С помощью представления можно извлечь данные из нескольких таблиц и представить их как одну таблицу, превращая тем самым запрос ко многим таблицам в однотабличный запрос к представлению (такие представления также называют объединенными).
- Простота структуры. С помощью представлений для каждого пользователя можно создать собственную “структуру” базы данных, определив ее как множество доступных пользователю виртуальных таблиц.
- Защита от изменений. Представление может возвращать непротиворечивый и неизменный образ структуры базы данных, даже если исходные таблицы разделяются, реструктуризируются или переименовываются.
- Целостность данных. Если доступ к данным или ввод данных (возможно не для всех представлений) осуществляется с помощью представления, СУБД может автоматически проверять, выполняются ли определенные условия целостности.
Недостатки представлений. Наряду с перечисленными выше преимуществами, представления обладают и двумя существенными недостатками:
- Производительность. Представление создает лишь видимость существования соответствующей таблицы, и СУБД приходится преобразовывать запрос к представлению в запрос к исходным таблицам. Если представление отображает многотабличный запрос, то простой запрос к представлению становится сложным объединением и на его выполнение может потребоваться много времени.
- Ограничения на обновление. Когда пользователь пытается обновить строки представления, СУБД должна установить их соответствие строкам исходных таблиц, а также обновить последние. Это возможно только для простых представлений; сложные представления обновлять нельзя, они доступны только для выборки.
Указанные недостатки означают, что не стоит без разбора применять представления вместо исходных таблиц. В каждом конкретном случае необходимо учитывать перечисленные преимущества и недостатки.
Обновление представлений. Для простых представлений операции добавления, изменения и удаления можно преобразовать в эквивалентные операции по отношению к исходным таблицам представления. Например, вернемся к представлению Minsk, рассмотренному ранее в примере. Это простое горизонтальное представление, основанное на одной исходной таблице. Добавление строки в данное представление имеет смысл; оно означает, что новая строка должна быть вставлена в таблицу staff, лежащую в основе представления. Аналогично, имеет смысл удаление строки из представления Minsk – это удаление соответствующей строки из таблицы staff. Наконец, обновление строки представления Minsk также имеет смысл: оно будет обновлением соответствующей строки таблицы staff. Во всех случаях требуемое действие можно выполнить по отношению к соответствующей строке исходной таблицы, тем самым, сохраняя целостность исходной таблицы и представления.
Согласно стандарту, представление можно обновлять в том случае, если определяющий его запрос соответствует перечисленным ниже требованиям:
1. Должен отсутствовать предиката DISTINCT, т.е. повторяющиеся строки не должны исключаться из результата запроса.
2. В предложении FROM должна быть задана только одна таблица или представление.
3. Каждое имя в списке возвращаемых столбцов должно быть ссылкой на простой столбец, не должны содержаться выражения, вычисляемые столбцы и статистические функции.
4. В предложении WHERE не должен содержаться подчиненный запрос
5. В запросе не должны присутствовать предложения GROUP BY и HAVING.
Обобщая сказанное можно отметить, что если между строками представления и строками исходной таблицы есть соответствие “один – к - одному”, то такое представление можно считать обновляемым. Если между строками представления и исходной таблицы нет однозначного соответствия, то добавление, удаление и изменение строк представления не имеет смысла и поэтому запрещены. Однако некоторые коммерческие СУБД позволяют обновлять “неоднозначные” представления. Так в ORACLE такие обновления возможны посредством триггеров INSTEAD OF .
Контроль над обновлением представлений (предложение WITH CHECK OPTION). Если представление создается посредством запроса с предложением WHERE, то в представлении будут видны только строки, удовлетворяющие условию отбора. Остальные строки в исходной таблице присутствуют, но в представлении их нет. Например, представление Minsk, которое уже рассматривалось ранее в настоящем разделе, содержиттолько строки таблицы staff с определенными значениями в столбце bno .
Это представление является обновляемым как по стандарту ANSI/ISO, так и в большинстве коммерческих СУБД. В него можно добавить информацию о новом служащем посредством инструкции INSERT:
insert into Minsk (sno, fname, lname, address, position, sex, dob, salary, bno)
values ( ‘s129’, ‘…’, ‘…’, ‘…’, ‘менеджер’, ‘f’, ’01.01.81’, 300, 1).
СУБД добавит новую строку в исходную таблицу staff; она будет видна также в представлении Minsk. Однако если воспользоваться следующей инструкцией для добавления строки в представление Minsk:
insert into Minsk (sno, fname, lname, address, position, sex, dob, salary, bno)
values ( ‘s129’, ‘…’, ‘…’, ‘…’, ‘менеджер’, ‘f’, ’01.01.81’, 300, 2).
и сразу после неё выполнить запрос: select * from Minsk, то только что добавленная строка в ней будет отсутствовать. Тот факт, что в результате выполнения инструкции INSERT или UPDATE из представления исчезают строки, в лучшем случае вызывает замешательство. SQL позволяет организовать своеобразный контроль целостности представлений путем создания их с режимом контроля. Данный режим задается в инструкции CREATE VIEW посредством предложения WITH CHECK OPTION:
create view Minsk as
select * from staff
where bno in (select bno
from branch
where city=‘Минск’)
with check option;
Когда для представления установлен режим контроля, СУБД автоматически проверяет каждую операцию INSERT или UPDATE, выполняемую над представлением, чтобы удостовериться в том, что полученные в результате строки удовлетворяют условиям отбора в определении представления. Если добавляемая или обновляемая строка не удовлетворяет этим условиям, то выполнение инструкции INSERT или UPDATE завершается ошибкой; другими словами, операция не выполняется.
В заключение текущего раздела следует отметить, что удаляются представления посредством инструкции DROP VIEW. Так представление Minsk может быть удалено при выполнении инструкции:
drop view Minsk;
23. ПСЕВДОНИМЫ ТАБЛИЦ (ИНСТРУКЦИИ CREATE / DROP SYNONYM)
Промышленные базы данных часто бывают организованы так, что все основные таблицы собраны вместе и принадлежат администратору. Администратор базы данных дает другим пользователям разрешения на доступ к таблицам, руководствуясь правилами обеспечения безопасности. Поэтому и только в случае получения разрешения на доступ к таблицам другого пользователя, для ссылки на них необходимо использовать полные имена таблиц. На практике это означает, что в каждом запросе к таким таблицам следует указывать полные имена таблиц, в результате чего запросы становятся длинными, а их ввод – утомительным:
Для решения этой проблемы во многих СУБД вводится понятие псевдонима или синонима. Псевдоним – это назначаемое пользователем имя, которое заменяет имя некоторой таблицы.
В ORACLE для создания псевдонимов используется инструкция CREATE SYNONYM. В других СУБД для аналогичных целей используется инструкция CREATE ALIAS.
CREATE [PUBLIC] SYNONYM имя_синонима
FOR [схема.] имя_таблицы[@связь_БД]
После создания псевдонима его можно использовать в запросах SQL как обычное имя таблицы. Применение псевдонимов смысл запроса не изменяет, так как и в этом случае необходимо иметь разрешение на доступ к таблицам других пользователей. Тем не менее, псевдонимы упрощают инструкции SQL, и последние приобретают такой вид, как если бы вы обращались к своим собственным таблицам. Если позднее вы решите, что больше не нуждаетесь в псевдонимах, то можете их удалить посредством инструкции DROP ALIAS.
24. ИНДЕКСЫ (ИНСТРУКЦИИ CREATE/DROP INDEX)
Одним из структурных элементов физической памяти, присутствующим в большинстве реляционных СУБД, является индекс. Индекс – это средство, обеспечивающее быстрый доступ к строкам таблицы на основе значений одного или нескольких столбцов. СУБД пользуется индексом так же, как читатели пользуетесь предметным указателем книги. В индексе хранятся значения данных и указатели на строки, где эти данные встречаются. Данные в индексе располагаются в отсортированном по убыванию или возрастанию порядке, чтобы СУБД могла быстро найти требуемое значение. Затем по указателю СУБД может быстро локализовать строку, содержащую искомое значение.
Наличие или отсутствие индекса совершенно незаметно для пользователя, обращающегося к таблице.
Например, в случае поиска сотрудника по фамилии будем использовать столбец lname. Если бы индекса для столбца не существовало, то СУБД была бы вынуждена выполнять запрос путем последовательного “сканирования” таблицы staff, строка за строкой, просматривая в каждой строке значения столбца lname. Для получения гарантии того, что найдены все строки, удовлетворяющие условию отбора, СУБД должна просмотреть каждую строку таблицы. Если таблица имеет сотни тысячи строк, то ее просмотр может занять достаточно много времени.
Если для столбца lname имеется индекс, СУБД находит требуемые данные, просматривая индекс, чтобы найти требуемое значение, а затем с помощью указателя находит требуемую строку (строки) таблицы. Поиск в индексе осуществляется достаточно быстро, так как индекс отсортирован (сортировка “строковых” столбцов осуществляется в лексикографическом порядке) и его строки достаточно коротки. Переход от индекса к строке (строкам) также происходит довольно быстро, поскольку в индексе содержится информация о том, где на диске располагается эта строка (строки).
Как видно из примера, индекс имеет то преимущество, что ускоряет выполнение инструкций с условиями отбора, имеющими ссылки на индексный столбец (столбцы). К недостаткам индекса относится то, что, во-первых, он занимает на диске дополнительную память и, во-вторых, индекс необходимо обновлять каждый раз, когда в таблицу добавляется строка или обновляется индексный столбец таблицы. Это требует дополнительных затрат на выполнение инструкций INSERT и UPDATE, которые обращаются к данной таблице.
В общем-то, полезно создавать индекс лишь для тех столбцов, которые часто используются в условиях отбора. Индексы удобны также в тех случаях, когда инструкции SELECT обращаются к таблице гораздо чаще, чем инструкции INSERT и UPDATE. СУБД всегда создает индекс для первичного ключа таблицы, так как ожидает, что доступ к таблице чаще всего будет осуществляться через первичный ключ.
В стандартах SQL ничего не говорится об индексах и о том, как их создавать. Они относятся к “деталям реализации”, выходящим за рамки ядра языка SQL. Тем не менее, индексы весьма важны для обеспечения требуемой производительности любой серьезной, корпоративной или промышленной, базы данных.
На практике в большинстве популярных СУБД (включая ORACLE, SQServer, INFORMIX, SYBASE) для создания индекса используется та или иная форма инструкции CREATE INDEX. В инструкции указывается имя индекса и таблица, для которой он создается, индексируемый столбец и порядок его сортировки (по возрастанию или убыванию).
В Oracle можно создать, изменить или удалить индекс для одного или нескольких столбцов таблицы используя следующий синтаксис:
CREATE [OR REPLACE] [UNIQUE | BITMAP] INDEX [схема.] имя_индекса
ON [схема.] имя_таблицы [псевдоним] (столбец | выражение_для_столбца [ASC | DESC][, …]);
где UNIQUE – означает, что значения столбцов, на которые ссылается индекс должны быть уникальными; BITMAP – изменение структуры индекса со сбалансированного дерева на структуру растровой карты.
25. Последовательности (инструкция CREATE/DROP SEQUENCE)
Использование последовательностей полезно для автоматической генерации уникальных первичных ключей для данных, а также для координирования ключей между различными строками или таблицами.
Без генератора последовательностей порядковые номера можно создавать лишь программным способом. Новое значение первичного ключа можно было бы получать выбором последнего программно вычисленного значения и наращиванием его. Этот метод требует блокировки во время выполнения транзакции и заставляет одновременно работающих пользователей ожидать очередного значения первичного ключа; такое ожидание известно как СЕРИАЛИЗАЦИЯ (буквально – "выстраивание в очередь"). Если есть в пользовательских приложениях такие программные конструкции, то их нужно заменять на обращения к последовательностям. Последовательности устраняют сериализацию и улучшают конкурентные способности приложений.
Рассмотрим, как создавать, изменять и удалять последовательности с помощью команд SQL.
Создание последовательностей осуществляется с помощью команды SQL CREATE SEQUENCE. Например, следующая команда создает последовательность, которую можно использовать для генерации номеров сотрудников для столбца sno таблицы staff:
CREATE SEQUENCE sno_sequence
INCREMENT BY 1
START WITH 1
NOMAXVALUE
NOCYCLE
CACHE 10;
Для управления работой последовательности могут быть специфицированы некоторые параметры. С помощью этих параметров можно указать, должна ли последовательность возрастать или убывать, задать начальную точку последовательности, ее минимальное и максимальное значения, а также интервал приращения. Опция NOCYCLE указывает, что последовательность не сможет генерировать больше значений, когда достигнет своего максимального или минимального значения.
Опция CACHE команды CREATE SEQUENCE обеспечивает предварительную генерацию нескольких номеров последовательности и поддерживает их в памяти (кэширует), так что доступ к ним ускоряется. Когда использован последний из номеров в кэше, ORACLE считывает в кэш очередную группу номеров.
Чтобы изменить последовательность (за исключением начального номера) используется команда SQL ALTER SEQUENCE. Например, следующее предложение изменяет последовательность:
ALTER SEQUENCE EMP sno_sequence
INCREMENT BY 10
MAXVALUE 10000
CYCLE
CACHE 20;
Чтобы изменить начальную точку последовательности, удалите эту последовательность и заново создайте ее.
Однажды определенная, последовательность может быть сделана доступной многим пользователям, которые могут обращаться к этой последовательности и вызывать ее приращения, не прибегая к ожиданию. ORACLE не ждет завершения транзакции, выполнившей приращение последовательности, для того чтобы осуществить очередное приращение этой последовательности.
Обращение к последовательности осуществляется в предложениях SQL через псевдостолбцы NEXTVAL и CURRVAL; каждый новый номер данной последовательности генерируется обращением к ее псевдостолбцу NEXTVAL, тогда как текущий номер последовательности можно извлекать неоднократно путем обращения к ее псевдостолбцу CURRVAL.
NEXTVAL и CURRVAL не являются зарезервированными или ключевыми словами; их можно использовать как имена псевдостолбцов в предложениях SQL, таких как SELECT, INSERT или UPDATE.
Чтобы сгенерировать и возвратить очередной номер данной последовательности, обратитесь к seq_name.NEXTVAL, где seq_name – имя последовательности. Например, предположим, что заказчик размещает заказ. Номер последовательности можно специфицировать в списке вставляемых значений как номер нового заказа, например:
INSERT INTO orders (orderno, custno)
VALUES (order_seq.NEXTVAL, 1032);
или во фразе SET предложения UPDATE, например:
UPDATE orders
SET orderno=order_seq.NEXTVAL
WHERE orderno=10112;
или в самом внешнем списке SELECT запроса или подзапроса, например:
SELECT order_seq.NEXTVAL FROM dual;
По определению, первое обращение к order_seq.NEXTVAL возвратит значение 1. Каждое последующее предложение, обращающееся к order_seq.NEXTVAL, возвратит очередной номер данной последовательности (2, 3, 4 и т.д.). Псевдостолбец NEXTVAL может генерировать столько новых номеров последовательности, сколько потребуется. Однако на одно предложение генерируется лишь один новый номер; иными словами, если в данном предложении SQL псевдостолбец NEXTVAL встречается несколько раз, то лишь для первого обращения будет возвращен новый номер последовательности, а все остальные обращения в этом предложении возвратят тот же самый номер. После того как очередной номер последовательности сгенерирован, этот номер доступен лишь сессии, сгенерировавшей его. Независимо от подтверждения или отката транзакций, все пользователи, обращающиеся к order_seq.NEXTVAL, получают уникальные значения. Поэтому, если несколько пользователей одновременно обращаются к одной и той же последовательности, каждый из них может получать номера этой последовательности с промежутками, потому что номера генерируются также другими пользователями.
Чтобы обратиться к текущему значению номера последовательности, которое уже было сгенерировано для вашей сессии, используйте обозначение seq_name.CURRVAL, где seq_name – имя последовательности. Псевдостолбец CURRVAL может использоваться лишь в том случае, если в текущей сессии уже было выдано обращение к seq_name.NEXTVAL для данной последовательности (не обязательно в текущей транзакции). CURRVAL можно использовать сколько угодно раз, в том числе несколько раз в одном и том же предложении. Очередной номер последовательности не будет сгенерирован, пока не будет выполнено очередное обращение к NEXTVAL. Продолжая предыдущий пример, вы могли бы завершить размещение заказа, вставив в детальную таблицу строки элементов заказа:
INSERT INTO line_items (orderno, partno, quantity)
VALUES (order_seq.CURRVAL, 20321, 3);
INSERT INTO line_items (orderno, partno, quantity)
VALUES (order_seq.CURRVAL, 29374, 1);
Если предложение INSERT в предыдущей секции сгенерировало для номера нового заказа, скажем, число 347, то оба эти предложения вставят строки с тем же номером заказа 347.
NEXTVAL и CURRVAL могут использоваться во фразе VALUES предложения INSERT, в списке SELECT предложения SELECT, во фразе SET предложения UPDATE.
NEXTVAL и CURRVAL не могут использоваться в следующих местах: в подзапросе; в запросе, определяющем представление или моментальный снимок; в предложении SELECT с оператором DISTINCT; в предложении SELECT с фразой GROUP BY или ORDER BY; в предложении SELECT, скомбинированном с другим предложением SELECT одним из операторов множеств UNION, INTERSECT или MINUS; во фразе WHERE предложения SELECT; в выражении DEFAULT для столбца в предложении CREATE TABLE или ALTER TABLE; в условии ограничения CHECK.
Если последовательность больше не нужна, вы можете удалить ее с помощью команды SQL DROP SEQUENCE. Например, следующее предложение удаляет последовательность order_seq:
DROP SEQUENCE order_seq;
При удалении последовательности ее определение удаляется из словаря данных. Все синонимы для последовательности остаются, но возвращают ошибку при обращении к ним.
──CREATE SEQUENCE──┬─────────┬─sequence────────>
└─schema.─┘
v──────────────────────────────────┐
>──┬───────────────────────────────┬─┴──────────><
├─┬───INCREMENT BY────┬─integer─┤
│ └───START WITH──────┘ │
├─┬───MAXVALUE integer─┬────────┤
│ └───NOMAXVALUE───────┘ │
├─┬───MINVALUE integer─┬────────┤
│ └───NOMINVALUE───────┘ │
├─┬───CYCLE────────────┬────────┤
│ └───NOCYCLE──────────┘ │
├─┬───CACHE integer────┬────────┤
│ └───NOCACHE──────────┘ │
└─┬───ORDER────────────┬────────┘
└───NOORDER──────────┘
SQL> CREATE SEQUENCE peak_no
2 INCREMENT BY 1
3 START WITH 1
4 NOMAXVALUE
5 NOCYCLE
6 NOCACHE
7 ORDER;
Sequence created.
Дата добавления: 2015-08-26; просмотров: 1528;