Понятия об измерениях и единицах физических величин
Деятельность мультипрограммной операционной системы состоит из цепочек операций, выполняемых над различными процессами, и сопровождается переключением процессора с одного процесса на другой (рис.4).
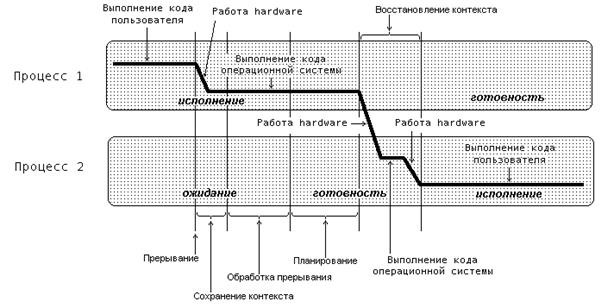
Рис 4. Выполнение операции разблокирования процесса. Использование термина "код пользователя" не ограничивает общности рисунка только пользовательскими процессами
При исполнении процессором некоторого процесса (на рисунке - процесс 1) возникает прерывание от устройства ввода-вывода, сигнализирующее об окончании операций на устройстве. Над выполняющимся процессом производится операция приостановка. Далее, операционная система разблокирует процесс, инициировавший запрос на ввод-вывод (на рисунке - процесс 2), и осуществляет запуск приостановленного или нового процесса, выбранного при выполнении планирования (на рисунке был выбран разблокированный процесс). Как видим, в результате обработки информации об окончании операции ввода-вывода возможна смена процесса, находящегося в состоянии исполнение.
Для корректного переключения процессора с одного процесса на другой необходимо сохранить контекст исполнявшегося процесса и восстановить контекст процесса, на который будет переключен процессор. Такая процедура сохранения/восстановления работоспособности процессов называется переключением контекста. Время, затраченное на переключение контекста, не используется вычислительной системой для совершения полезной работы и представляет собой накладные расходы, снижающие производительность системы. Оно меняется от машины к машине и обычно находится в диапазоне от 1 до 1000 микросекунд. Существенно сократить накладные расходы в современных операционных системах позволяет расширенная модель процессов, включающая в себя понятие threads of execution (нити исполнения или просто нити).
Алгоритмы планирования процессов.
Уровни планирования
В ОС принято разделять два вида планирования в: планирование заданий и планирование использования процессора. Планирование заданий появилось в пакетных системах после того, как для хранения сформированных пакетов заданий начали использоваться магнитные диски. Планирование использования процессора впервые возникает в мультипрограммных вычислительных системах, где в состоянии готовность могут одновременно находиться несколько процессов. Именно для процедуры выбора из них одного процесса, который получит процессор в свое распоряжение, т.е. будет переведен в состояние исполнение. Оба этих вида планирования рассматриваются как различные уровни планирования процессов.
Планирование заданий выступает в качестве долгосрочного планирования процессов. Оно отвечает за порождение новых процессов в системе, определяя ее степень мультипрограммирования, т. е. количество процессов, одновременно находящихся в ней. Если степень мультипрограммирования системы поддерживается постоянной, т. е. среднее количество процессов в компьютере не меняется, то новые процессы могут появляться только после завершения ранее загруженных. Поэтому долгосрочное планирование осуществляется достаточно редко, между появлением новых процессов могут проходить минуты и даже десятки минут. Решение о выборе для запуска того или иного процесса оказывает влияние на функционирование вычислительной системы на протяжении достаточно длительного интервала времени. Отсюда и проистекает название этого уровня планирования — долгосрочное. В некоторых операционных системах долгосрочное планирование сведено к минимуму или совсем отсутствует. Так, например, во многих интерактивных системах разделения времени порождение процесса происходит сразу после появления соответствующего запроса. Поддержание разумной степени мультипрограммирования осуществляется за счет ограничения количества пользователей, которые могут работать в системе, и человеческой психологии. Если между нажатием на клавишу и появлением символа на экране проходит 20-30 секунд, то многие пользователи предпочтут прекратить работу и продолжить ее, когда система будет менее загружена.
Планирование использования процессора выступает в качестве краткосрочного планирования процессов. Оно проводится, к примеру, при обращении исполняющегося процесса к устройствам ввода-вывода или просто по завершении определенного интервала времени. Поэтому краткосрочное планирование осуществляется весьма часто, как правило, не реже одного раза в 100 миллисекунд. Выбор нового процесса для исполнения оказывает влияние на функционирование системы до наступления очередного аналогичного события, т. е. в течение короткого промежутка времени, что и обусловило название этого уровня планирования — краткосрочное.
В некоторых вычислительных системах бывает выгодно для повышения их производительности временно удалить какой-либо частично выполнившийся процесс из оперативной памяти на диск, а позже вернуть его обратно для дальнейшего выполнения. Такая процедура в англоязычной литературе получила название swapping. Когда и какой из процессов нужно перекачать на диск и вернуть обратно, решается дополнительным промежуточным уровнем планирования процессов — среднесрочным.
Критерии планирования и требования к алгоритмам
Для каждого уровня планирования процессов можно предложить много различных алгоритмов. Выбор конкретного алгоритма определяется классом задач, решаемых вычислительной системой, и целями, которых мы хотим достичь, используя планирование. К числу таких целей можно отнести:
- справедливость: гарантировать каждому заданию или процессу определенную часть времени использования процессора в компьютерной системе, стараясь не допустить возникновения ситуации, когда процесс одного пользователя постоянно занимает процессор, в то время как процесс другого пользователя фактически не приступал к выполнению;
- эффективность: постараться занять процессор на все 100% рабочего времени, не позволяя ему простаивать в ожидании процессов готовых к исполнению. В реальных вычислительных системах загрузка процессора колеблется от 40 до 90 процентов;
- сокращение полного времени выполнения (turnaround time): обеспечить минимальное время между стартом процесса или постановкой задания в очередь для загрузки и его завершением;
- сокращение времени ожидания (waiting time): минимизировать время, которое проводят процессы в состоянии готовность и задания в очереди для загрузки;
- сокращение времени отклика (response time): минимизировать время, которое требуется процессу в интерактивных системах для ответа на запрос пользователя.
Независимо от поставленных целей планирования желательно также, чтобы алгоритмы обладали следующими свойствами:
были предсказуемыми. Одно и то же задание должно выполняться приблизительно за одно и то же время. Применение алгоритма планирования не должно приводить, к примеру, к извлечению корня квадратного из 4 за сотые доли секунды при одном запуске и за несколько суток при втором запуске;
имели минимальные накладные расходы, связанные с их работой. Если на каждые 100 миллисекунд, выделенных процессу для использования процессора, будет приходиться 200 миллисекунд на определение того, какой именно процесс получит процессор в свое распоряжение, и на переключение контекста, то такой алгоритм, очевидно, использовать не стоит;
равномерно загружали ресурсы вычислительной системы, отдавая предпочтение тем процессам, которые будут занимать малоиспользуемые ресурсы;
обладали масштабируемостью, т.е. не сразу теряли работоспособность при увеличении нагрузки. Например, рост количества процессов в системе в два раза не должен приводить к увеличению полного времени выполнения процессов на порядок.
Многие из приведенных выше целей и свойств являются противоречивыми. Улучшая работу алгоритма с точки зрения одного критерия, мы ухудшаем ее с точки зрения другого. Приспосабливая алгоритм под один класс задач, мы тем самым дискриминируем задачи другого класса.
Параметры планирования
Для осуществления поставленных целей разумные алгоритмы планирования должны опираться на какие-либо характеристики процессов в системе, заданий в очереди на загрузку, состояния самой вычислительной системы, иными словами, на параметры планирования. В этом разделе мы опишем ряд таких параметров, не претендуя на полноту изложения.
Все параметры планирования можно разбить на две большие группы: статические параметры и динамические параметры. Статические параметры не изменяются в ходе функционирования вычислительной системы, динамические же, напротив, подвержены постоянным изменениям.
К статическим параметрам вычислительной системы можно отнести предельные значения ее ресурсов (размер оперативной памяти, максимальное количество памяти на диске для осуществления свопинга, количество подключенных устройств ввода-вывода и т.п.). Динамические параметры системы описывают количество свободных ресурсов в текущий момент времени.
К статическим параметрам процессов относятся характеристики, как правило, присущие заданиям уже на этапе загрузки:
Каким пользователем запущен процесс или сформировано задание?
Насколько важной является поставленная задача, т.е. каков приоритет ее выполнения?
Сколько процессорного времени запрошено пользователем для решения задачи?
Каково соотношение процессорного времени и времени, необходимого для осуществления операций ввода-вывода?
Какие ресурсы вычислительной системы (оперативная память, устройства ввода-вывода, специальные библиотеки и системные программы и т.д.) и в каком количестве необходимы заданию?
Алгоритмы долгосрочного планирования используют в своей работе статические и динамические параметры вычислительной системы и статические параметры процессов (динамические параметры процессов на этапе загрузки заданий еще не известны). Алгоритмы краткосрочного и среднесрочного планирования дополнительно учитывают и динамические характеристики процессов. Для среднесрочного планирования в качестве таких характеристик может выступать следующая информация:
Сколько времени прошло со времени выгрузки процесса на диск или его загрузки в оперативную память.
Сколько оперативной памяти занимает процесс.
Сколько процессорного времени было уже предоставлено процессу.
Для краткосрочного планирования используются еще два динамических параметра. Деятельность любого процесса можно представить как последовательность циклов использования процессора и ожидания завершения операций ввода-вывода. Промежуток времени непрерывного использования процессора носит на английском языке название CPU burst, а промежуток времени непрерывного ожидания ввода-вывода – I/O burst. На рис. 5. показан фрагмент деятельности некоторого процесса на псевдоязыке программирования с выделением указанных промежутков. Значения продолжительности последних и очередных CPU burst и I/O burst являются важными динамическими параметрами процесса.
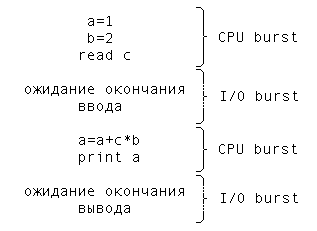
Рис 5. Фрагмент деятельности процесса с выделением промежутков
непрерывного использования процессора и ожидания ввода-вывода.
Вытесняющее и невытесняющее планирование
Процесс планирования осуществляется частью операционной системы, называемой планировщиком. Планировщик может принимать решения о выборе для исполнения нового процесса, из числа находящихся в состоянии готовность, в следующих четырех случаях:
1 когда процесс переводится из состояния исполнение в состояние завершение;
2 когда процесс переводится из состояния исполнение в состояние ожидание;
3 когда процесс переводится из состояния исполнение в состояние готовность (например, после прерывания от таймера);
4 когда процесс переводится из состояния ожидание в состояние готовность (завершилась операция ввода-вывода или произошло другое событие).
В случаях 1 и 2 процесс, находившийся в состоянии исполнение, не может дальше исполняться, и для выполнения всегда необходимо выбрать новый процесс. В случаях 3 и 4 планирование может не проводиться, процесс, который исполнялся до прерывания, может продолжать свое выполнение после обработки прерывания. Если планирование осуществляется только в случаях 1 и 2, говорят, что имеет место невытесняющее (nonpreemptive) планирование. В противном случае говорят о вытесняющем (preemptive) планировании. Термин “вытесняющее планирование” возник потому, что исполняющийся процесс помимо своей воли может быть вытеснен из состояния исполнение другим процессом.
Невытесняющее планирование используется, например, в MS Windows 3.1 и ОС Apple Macintosh. При таком режиме планирования процесс занимает столько процессорного времени, сколько ему необходимо. При этом переключение процессов возникает только при желании самого исполняющегося процесса передать управление (для ожидания завершения операции ввода-вывода или по окончании работы). Этот метод планирования относительно просто реализуем и достаточно эффективен, так как позволяет использовать большую часть процессорного времени на работу самих процессов и до минимума сократить затраты на переключение контекста. Однако при невытесняющем планировании возникает проблема возможности полного захвата процессора одним процессом, который вследствие каких-либо причин (например, из-за ошибки в программе) зацикливается и не может передать управление другому процессу. В такой ситуации спасает только перезагрузка всей вычислительной системы.
Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме планирования процесс может быть приостановлен в любой момент своего исполнения. Операционная система устанавливает специальный таймер для генерации сигнала прерывания по истечении некоторого интервала времени — кванта. После прерывания процессор передается в распоряжение следующего процесса. Временные прерывания помогают гарантировать приемлемые времена отклика процессов для пользователей, работающих в диалоговом режиме, и предотвращают “зависание” компьютерной системы из-за зацикливания какой-либо программы.
Алгоритмы планирования
Существует достаточно большой набор разнообразных алгоритмов планирования, которые предназначены для достижения различных целей и эффективны для разных классов задач. Многие из них могут быть использованы на нескольких уровнях планирования.
First-Come, First-Served (FCFS)
Простейшим алгоритмом планирования является алгоритм, который принято обозначать аббревиатурой FCFS по первым буквам его английского названия — First Come, First Served (первым пришел, первым обслужен). Представим себе, что процессы, находящиеся в состоянии готовность, организованы в очередь. Когда процесс переходит в состояние готовность, он, а точнее ссылка на его PCB, помещается в конец этой очереди. Выбор нового процесса для исполнения осуществляется из начала очереди с удалением оттуда ссылки на его PCB. Очередь подобного типа имеет в программировании специальное наименование FIFO — сокращение от First In, First Out (первым вошел, первым вышел.
Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения своего текущего CPU burst. После этого для выполнения выбирается новый процесс из начала очереди.
Преимуществом алгоритма FCFS является легкость его реализации, в то же время он имеет и много недостатков. Рассмотрим следующий пример. Пусть в состоянии готовностьнаходятся три процесса p0, p1 и p2, для которых известны времена их очередных CPU burst. Эти времена приведены в табл. 1 в некоторых условных единицах.
Таблица 1.
| Процесс | p0 | p1 | p2 |
| Продолжительность очередного CPU burst |
Для простоты полагается, что вся деятельность процессов ограничивается использованием только одного промежутка CPU burst, что процессы не совершают операций ввода-вывода, и что время переключения контекста пренебрежимо мало. Если процессы расположены в очереди процессов готовых к исполнению в порядке p0, p1, p2, то картина их выполнения выглядит так, как показано на рисунке 6.
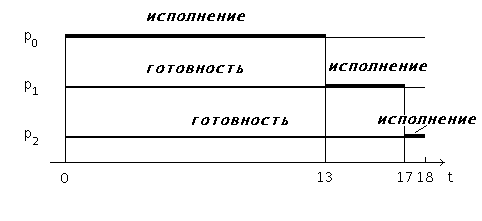
Рис 6. Выполнение процессов при порядке p0,p1,p2
Первым для выполнения выбирается процесс p0, который получает процессор на все время своего CPU burst, т.е. на 13 единиц времени. После его окончания в состояние исполнение переводится процесс p1, занимая процессор на 4 единицы времени. И, наконец, возможность работать получает процесс p2. Время ожидания для процесса p0 составляет 0 единиц времени, для процесса p1 – 13 единиц, для процесса p2—13+4=17 единиц. Таким образом, среднее время ожидания в этом случае — (0+13+17)/3=10 единиц времени. Полное время выполнения для процесса p0 составляет 13 единиц времени, для процесса p1—13+4=17 единиц, для процесса p2—13+4+1=18 единиц. Среднее полное время выполнения оказывается равным (13+17+18)/3=16 единицам времени.
Если те же самые процессы расположены в порядке p2, p1, p0, то картина их выполнения будет соответствовать рисунку 7.
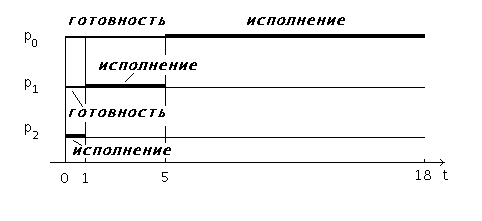
Рис 7. Выполнение процессов при порядке p2,p1,p0
Время ожидания для процесса p0 равняется 5 единицам времени, для процесса p1 — 1 единице, для процесса p2 — 0 единиц. Среднее время ожидания составит (5 + 1 + 0)/3 = 2 единицы времени. Это в 5 (!) раз меньше, чем в предыдущем случае. Полное время выполнения для процесса p0 получается равным 18 единицам времени, для процесса p1 — 5 единицам, для процесса p2 — 1 единице. Среднее полное время выполнения составляет (18 + 5 + 1)/3 = 6 единиц времени, что почти в 2,7 раза меньше чем при первой расстановке процессов.
Как видим, среднее время ожидания и среднее полное время выполнения для этого алгоритма существенно зависят от порядка расположения процессов в очереди. Если есть процесс с длительным CPU burst, то короткие процессы, перешедшие в состояние готовность после длительного процесса, будут очень долго ждать начала своего выполнения. Поэтому алгоритм FCFS практически неприменим для систем разделения времени. Слишком большим получается среднее время отклика в интерактивных процессах.
Round Robin (RR)
Модификацией алгоритма FCFS является алгоритм, получивший название Round Robin (Round Robin – это вид детской карусели в США) или сокращенно RR. По сути дела это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически — процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10 - 100 миллисекунд (рис. 8.). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.
Реализуется такой алгоритм так же, как и предыдущий, с помощью организации процессов, находящихся в состоянии готовность, в очередь FIFO. Планировщик выбирает для очередного исполнения процесс, расположенный в начале очереди, и устанавливает таймер для генерации прерывания по истечении определенного кванта времени.
При выполнении процесса возможны два варианта:
- время непрерывного использования процессора, требующееся процессу, (остаток текущего CPU burst) меньше или равно продолжительности кванта времени. Тогда процесс по своей воле освобождает процессор до истечения кванта времени, на исполнение выбирается новый процесс из начала очереди и таймер начинает отсчет кванта заново.
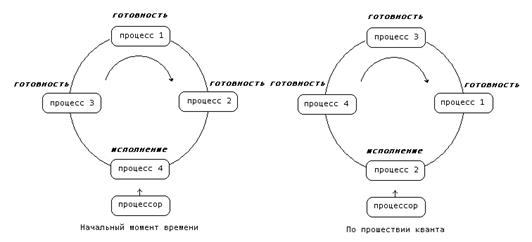
Рис. 8. Процессы на карусели.
- продолжительность остатка текущего CPU burst процесса больше, чем квант времени. Тогда по истечении этого кванта процесс прерывается таймером и помещается в конец очереди процессов готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
Для исходных данных предыдущего примера величиной кванта времени принимается равной 4. Выполнение этих процессов иллюстрируется табл. 2. Обозначение “И” используется в ней для процесса, находящегося в состоянии исполнение, обозначение “Г” — для процессов в состоянии готовность, пустые ячейки соответствуют завершившимся процессам. Состояния процессов показаны на протяжении соответствующей единицы времени, т.е. колонка с номером 1 соответствует промежутку времени от 0 до 1.
Таблица 2
| время | ||||||||||||||||||
| p0 | И | И | И | И | Г | Г | Г | Г | Г | И | И | И | И | И | И | И | И | И |
| p1 | Г | Г | Г | Г | И | И | И | И | ||||||||||
| p2 | Г | Г | Г | Г | Г | Г | Г | Г | И |
Первым для исполнения выбирается процесс p0. Продолжительность его CPU burst больше, чем величина кванта времени, и поэтому процесс исполняется до истечения кванта, т.е. в течение 4 единиц времени. После этого он помещается в конец очереди готовых к исполнению процессов, которая принимает вид p1, p2, p0. Следующим начинает выполняться процесс p1. Время его исполнения совпадает с величиной выделенного кванта, поэтому процесс работает до своего завершения. Теперь очередь процессов в состоянии готовность состоит из двух процессов p2, p0. Процессор выделяется процессу p2. Он завершается до истечения отпущенного ему процессорного времени, и очередные кванты отмеряются процессу p0 — единственному, не закончившему к этому моменту свою работу. Время ожидания для процесса p0 (количество символов “Г” в соответствующей строке) составляет 5 единиц времени, для процесса p1 — 4 единицы времени, для процесса p2 — 8 единиц времени. Таким образом, среднее время ожидания для этого алгоритма получается равным (5 + 4 + 8)/3 = 5,6(6) единицы времени. Полное время выполнения для процесса p0 (количество непустых столбцов в соответствующей строке) составляет 18 единиц времени, для процесса p1 — 8 единиц, для процесса p2 — 9 единиц. Среднее полное время выполнения оказывается равным (18 + 8 + 9)/3 = 11,6(6) единицам времени.
Легко видеть, что среднее время ожидания и среднее полное время выполнения для обратного порядка процессов не отличаются от соответствующих времен для алгоритма FCFS и составляют 2 и 6 единиц времени соответственно.
На производительность алгоритма RR сильно влияет величина кванта времени. Тот же самый пример c порядком процессов p0, p1, p2 для величины кванта времени равной 1 (табл. 3.). Время ожидания для процесса p0 составит 5 единиц времени, для процесса p1 — тоже 5 единиц, для процесса p2 — 2 единицы. В этом случае среднее время ожидания получается равным (5 + 5 + 2)/3 = 4 единицам времени. Среднее полное время исполнения составит (18 + 9 + 3)/3 = 10 единиц времени.
Таблица 3.
| время | ||||||||||||||||||
| p0 | И | Г | Г | И | Г | И | Г | И | Г | И | И | И | И | И | И | И | И | И |
| p1 | Г | И | Г | Г | И | Г | И | Г | И | |||||||||
| p2 | Г | Г | И |
При очень больших величинах кванта времени, когда каждый процесс успевает завершить свой CPU burst до возникновения прерывания по времени, алгоритм RR вырождается в алгоритм FCFS. При очень малых величинах создается иллюзия того, что каждый из n процессов работает на своем собственном виртуальном процессоре с производительностью ~ 1/n от производительности реального процессора. Правда, это справедливо лишь при теоретическом анализе при условии пренебрежения временами переключения контекста процессов. В реальных условиях при слишком малой величине кванта времени и, соответственно, слишком частом переключении контекста, накладные расходы на переключение резко снижают производительность системы.
Shortest-Job-First (SJF)
Из рассмотрения алгоритмов FCFS и RR видно, насколько существенным для них является порядок расположения процессов в очереди процессов готовых к исполнению. Если короткие задачи расположены в очереди ближе к ее началу, то общая производительность этих алгоритмов значительно возрастает. Если известно время следующих CPU burst для процессов, находящихся в состоянии готовность, то можно выбрать для исполнения не процесс из начала очереди, а процесс с минимальной длительностью CPU burst. Если же таких процессов два или больше, то для выбора одного из них можно использовать уже известный нам алгоритм FCFS. Квантование времени при этом не применяется. Описанный алгоритм получил название “кратчайшая работа первой” или Shortest Job First (SJF).
SJF алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF планировании процессор предоставляется избранному процессу на все требующееся ему время, независимо от событий происходящих в вычислительной системе. При вытесняющем SJF планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
Пример работы невытесняющего алгоритма SJF. Пусть в состоянии готовностьнаходятся четыре процесса p0, p1, p2 и p3, для которых известны времена их очередных CPU burst. Эти времена приведены в табл.4. полагается, что вся деятельность процессов ограничивается использованием только одного промежутка CPU burst, что процессы не совершают операций ввода-вывода, и что время переключения контекста пренебрежимо мало.
Таблица 4.
| Процесс | p0 | p1 | p2 | p3 |
| Продолжительность очередного CPU burst |
При использовании невытесняющего алгоритма SJF первым для исполнения будет выбран процесс p3, имеющий наименьшее значение очередного CPU burst. После его завершения для исполнения выбирается процесс p1, затем p0 и, наконец, p2. Вся эта картина изображена в табл.5.
Таблица 5.
| время | ||||||||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | |||||||
| p1 | Г | И | И | И | ||||||||||||
| p2 | Г | Г | Г | Г | Г | Г | Г | Г | Г | И | И | И | И | И | И | И |
| p3 | И |
Среднее время ожидания для алгоритма SJF составляет (4 + 1 + 9 + 0)/4 = 3,5 единицы времени. Легко посчитать, что для алгоритма FCFS при порядке процессов p0, p1, p2, p3 эта величина будет равняться (0 + 5 + 8 + 15)/4 = 7 единицам времени, т. е. будет в 2 раза больше, чем для алгоритма SJF. Можно показать, что для заданного набора процессов (если в очереди не появляются новые процессы) алгоритм SJF является оптимальным с точки зрения минимизации среднего времени ожидания среди класса всех невытесняющих алгоритмов.
Для рассмотрения примера вытесняющего SJF планирования используется ряд процессов p0, p1, p2 и p3с различными временами CPU burst и различными моментами их появления в очереди процессов готовых к исполнению (табл.6.).
Таблица 6.
| Процесс | Время появления в очереди | Продолжительность очередного CPU burst |
| p0 | ||
| p1 | ||
| p2 | ||
| p3 |
В начальный момент времени в состоянии готовность находятся только два процесса p0 и p4. Меньшее время очередного CPU burst оказывается у процесса p3, поэтому он и выбирается для исполнения (табл.7).
Таблица 7.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | И | И | И |
| p1 | И | И | ||||||||
| p2 | Г | Г | Г | Г | ||||||
| p3 | И | И | Г | Г | И | И | И |
| время | ||||||||||
| p0 | И | И | И | |||||||
| p1 | ||||||||||
| p2 | ||||||||||
| p3 | Г | Г | Г | И | И | И | И | И | И | И |
По прошествии 2-х единиц времени в систему поступает процесс p1. Время его CPU burst меньше, чем остаток CPU burst у процесса p3, который вытесняется из состояния исполнение и переводится в состояние готовность. По прошествии еще 2-х единиц времени процесс p1 завершается, и для исполнения вновь выбирается процесс p3. В момент времени t = 6 в очереди процессов готовых к исполнению появляется процесс p2, но поскольку ему для работы нужно 7 единиц времени, а процессу p3 осталось трудиться всего 2 единицы времени, то процесс p3 остается в состоянии исполнение. После его завершения в момент времени t = 7 в очереди находятся процессы p0 и p2, из которых выбирается процесс p0. Наконец, последним получит возможность выполняться процесс p2.
Основную сложность при реализации алгоритма SJF представляет невозможность точного знания времени очередного CPU burst для исполняющихся процессов. В пакетных системах количество процессорного времени, требующееся заданию для выполнения, указывает пользователь при формировании задания. Величина этого параметра может использоваться для осуществления долгосрочного SJF планирования. Если пользователь укажет больше времени, чем ему нужно, он будет ждать получения результата дольше, чем мог бы, так как задание будет загружено в систему позже. Если же он укажет меньшее количество времени, задача может не досчитаться до конца. Таким образом, в пакетных системах решение задачи оценки времени использования процессора перекладывается на плечи пользователя. При краткосрочном планировании можно делать только прогноз длительности следующего CPU burst, исходя из предыстории работы процесса. Пусть t(n) – величина n-го CPU burst, T(n + 1)– предсказываемое значение для n + 1-го CPU burst, a – некоторая величина в диапазоне от 0 до 1.
Определим рекуррентное соотношение
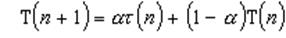
T(0) положим произвольной константой. Первое слагаемое учитывает последнее поведение процесса, тогда как второе слагаемое учитывает его предысторию. При a = 0 прекращается отслеживание поведения процесса, фактически полагая
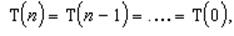
т.е. оценивая все CPU burst одинаково, исходя из некоторого начального предположения.
Положив a = 1, предыстория процесса во внимание не принимается. В этом случае полагается, что время очередного CPU burst будет совпадать со временем последнего CPU burst:
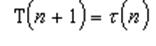
Обычно выбирают
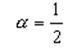
для равноценного учета последнего поведения и предыстории. Надо отметить, что такой выбор a удобен и для быстрой организации вычисления оценки T(n + 1). Для подсчета новой оценки нужно взять старую оценку, сложить с измеренным временем CPU burst и полученную сумму разделить на 2, например, с помощью ее сдвига на 1 бит вправо. Полученные оценки T(n + 1) применяются как продолжительности очередных промежутков времени непрерывного использования процессора для краткосрочного SJF планирования.
Гарантированное планирование
При интерактивной работе N пользователей в вычислительной системе можно применить алгоритм планирования, который гарантирует, что каждый из пользователей будет иметь в своем распоряжении ~ 1/N часть процессорного времени. Пронумеруем всех пользователей от 1 до N. Для каждого пользователя с номером i введем две величины: Ti - время нахождения пользователя в системе, или, другими словами длительность сеанса его общения с машиной, и ti - суммарное процессорное время уже выделенное всем его процессам в течение сеанса. Справедливым для пользователя было бы получение Ti/N процессорного времени. Если
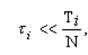
то i - й пользователь несправедливо обделен процессорным временем. Если же
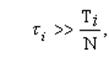
то система явно благоволит к пользователю с номером i. Вычислим для каждого пользовательского процесса значение коэффициента справедливости
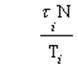
и будем предоставлять очередной квант времени процессу с наименьшей величиной этого отношения. Предложенный алгоритм называют алгоритмом гарантированного планирования. К недостаткам этого алгоритма можно отнести невозможность предугадать поведение пользователей. Если некоторый пользователь отправится на пару часов пообедать и поспать, не прерывая сеанса работы, то по возвращении его процессы будут получать неоправданно много процессорного времени.
Приоритетное планирование
Алгоритмы SJF и гарантированного планирования представляют собой частные случаи приоритетного планирования. При приоритетном планировании каждому процессу присваивается определенное числовое значение — приоритет, в соответствии с которым ему выделяется процессор. Процессы с одинаковыми приоритетами планируются в порядке FCFS. Для алгоритма SJF в качестве такого приоритета выступает оценка продолжительности следующего CPU burst. Чем меньше значение этой оценки, тем более высокий приоритет имеет процесс. Для алгоритма гарантированного планирования приоритетом служит вычисленный коэффициент справедливости. Чем он меньше, тем больше приоритет у процесса.
Принципы назначения приоритетов могут опираться как на внутренние критерии вычислительной системы, так и на внешние по отношению к ней. Внутренние используют различные количественные и качественные характеристики процесса для вычисления его приоритета. Это могут быть, например, определенные ограничения по времени использования процессора, требования к размеру памяти, число открытых файлов и используемых устройств ввода-вывода, отношение средних продолжительностей I/O burst к CPU burst и т.д. Внешние критерии исходят из таких параметров, как важность процесса для достижения каких-либо целей, стоимость оплаченного процессорного времени и других политических факторов.
Планирование с использованием приоритетов может быть как вытесняющим, так и невытесняющим. При вытесняющем планировании процесс с более высоким приоритетом, появившийся в очереди готовых процессов, вытесняет исполняющийся процесс с более низким приоритетом. В случае невытесняющего планирования он просто становится в начало очереди готовых процессов. Пример.
Пусть в очередь процессов, находящихся в состоянии готовность, поступают те же процессы, что и в примере 1. для вытесняющего алгоритма SJF, только им дополнительно еще присвоены приоритеты (табл.8). В вычислительных системах не существует определенного соглашения, какое значение приоритета - 1 или 4 считать более приоритетным. Во избежание путаницы, во всех примерах предполагается, что большее значение соответствует меньшему приоритету, т.е. наиболее приоритетным в нашем примере является процесс p3, а наименее приоритетным — процесс p0.
Таблица 8.
| Процесс | Время появления в очереди | Продолжительность очередного CPU burst | Приоритет |
| p0 | |||
| p1 | |||
| p2 | |||
| p3 |
Как будут вести себя процессы при использовании невытесняющего приоритетного планирования? Первым для выполнения в момент времени t = 0 выбирается процесс p3, как обладающий наивысшим приоритетом. После его завершения в момент времени t = 5 в очереди процессов готовых к исполнению окажутся два процесса p0 и p1. Больший приоритет из них у процесса p1 он и начнет выполняться (табл.9). Затем в момент времени t = 8 для исполнения будет избран процесс p2 и лишь потом процесс p0.
Таблица 9.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | Г | Г | Г |
| p1 | Г | Г | Г | И | И | |||||
| p2 | Г | И | И | И | ||||||
| p3 | И | И | И | И | И |
| время | ||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | И |
| p1 | ||||||||||
| p2 | И | И | И | И | ||||||
| p3 |
Иным будет предоставление процессора процессам в случае вытесняющего приоритетного планирования (табл.10). Первым, как и в предыдущем случае, исполняться начнет процесс p3, а по его окончании процесс p1. Однако в момент времени t = 6 он будет вытеснен процессом p2 и продолжит свое выполнение только в момент времени t = 13. Последним, как и раньше будет исполнен процесс p0.
Таблица 10.
| время | ||||||||||
| p0 | Г | Г | Г | Г | Г | Г | Г | Г | Г | Г |
| p1 | Г | Г | Г | И | Г | Г | Г | Г | ||
| p2 | И | И | И | И | ||||||
| p3 | И | И | И | И | И |
| время | ||||||||||
| p0 | Г | Г | Г | Г | И | И | И | И | И | И |
| p1 | Г | Г | Г | И | ||||||
| p2 | И | И | И | |||||||
| p3 |
В рассмотренном выше примере приоритеты процессов не изменялись с течением временем. Такие приоритеты принято называть статическими. Механизмы статической приоритетности легко реализовать, и они сопряжены с относительно небольшими издержками на выбор наиболее приоритетного процесса. Однако статические приоритеты не реагируют на изменения ситуации в вычислительной системе, которые могут сделать желательной корректировку порядка исполнения процессов. Более гибкими являются динамические приоритеты процессов, изменяющие свои значения по ходу исполнения процессов. Начальное значение динамического приоритета, присвоенное процессу, действует в течение лишь короткого периода времени, после чего ему назначается новое, более подходящее значение. Изменение динамического приоритета процесса является единственной операцией над процессами, которую мы до сих пор не рассмотрели. Как правило, изменение приоритета процессов проводится согласованно с совершением каких-либо других операций: при рождении нового процесса, при разблокировке или блокировании процесса, по истечении определенного кванта времени или по завершении процесса. Примерами алгоритмов с динамическими приоритетами являются алгоритм SJF и алгоритм гарантированного планирования. Схемы с динамической приоритетностью гораздо сложнее в реализации и связанны с большими издержками по сравнению со статическими схемами. Однако их использование предполагает, что эти издержки оправдываются улучшением поведения системы.
Главная проблема приоритетного планирования заключается в том, что при ненадлежащем выборе механизма назначения и изменения приоритетов низкоприоритетные процессы могут быть не запущены неопределенно долгое время. Обычно случается одно из двух. Или они все же дожидаются своей очереди на исполнение (в девять часов утра в воскресенье, когда все приличные программисты ложатся спать). Или вычислительную систему приходится выключать, и они теряются (при остановке IBM 7094 в Массачусетском технологическом институте в 1973 году были найдены процессы, запущенные в 1967 году и ни разу с тех пор не исполнявшиеся). Решение этой проблемы может быть достигнуто с помощью увеличения со временем значения приоритета процесса, находящегося в состоянии готовность. Пусть изначально процессам присваиваются приоритеты от 128 до 255. Каждый раз, по истечении определенного промежутка времени, значения приоритетов готовых процессов уменьшаются на 1. Процессу, побывавшему в состоянии исполнение, восстанавливается первоначальное значение приоритета. Даже такая грубая схема гарантирует, что любому процессу в разумные сроки будет предоставлено право на исполнение.
Многоуровневые очереди (Multilevel Queue)
Для систем, в которых процессы могут быть легко рассортированы на разные группы, был разработан другой класс алгоритмов планирования. Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность (рис. 9). Этим очередям приписываются фиксированные приоритеты.
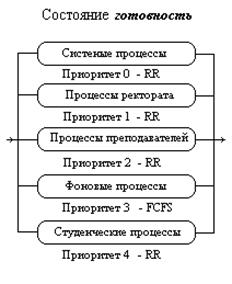
Рис. 9. Несколько очередей планирования.
Например, приоритет очереди системных процессов устанавливается больше, чем приоритет очередей пользовательских процессов. А приоритет очереди процессов, запущенных студентами, — ниже, чем для очереди процессов, запущенных преподавателями. Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению. Внутри этих очередей для планирования могут применяться самые разные алгоритмы. Так, например, для больших счетных процессов, не требующих взаимодействия с пользователем (фоновых процессов), может использоваться алгоритм FCFS, а для интерактивных процессов – алгоритм RR. Подобный подход, получивший название многоуровневых очередей, повышает гибкость планирования: для процессов с различными характеристиками применяется наиболее подходящий им алгоритм.
Многоуровневые очереди с обратной связью (Multilevel Feedback Queue)
Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи. Здесь процесс не постоянно приписан к определенной очереди, а может мигрировать из очереди в очередь, в зависимости от своего поведения.
Для простоты рассмотрим ситуацию, когда процессы в состоянии готовность организованы в 4 очереди, как на рисунке 10. Планирование процессов между очередями осуществляется на основе вытесняющего приоритетного механизма. Чем выше на рисунке располагается очередь, тем выше ее приоритет. Процессы в очереди 1 не могут исполняться, если в очереди 0 есть хотя бы один процесс. Процессы в очереди 2 не будут выбраны для выполнения, пока есть хоть один процесс в очередях 0 и 1. И, наконец, процесс в очереди 3 может получить процессор в свое распоряжение только тогда, когда очереди 0, 1 и 2 пусты. Если при работе процесса появляется другой процесс в какой-либо более приоритетной очереди, исполняющийся процесс вытесняется появившимся. Планирование процессов внутри очередей 0—2 осуществляется с использованием алгоритма RR, планирование процессов в очереди 3 основывается на алгоритме FCFS.
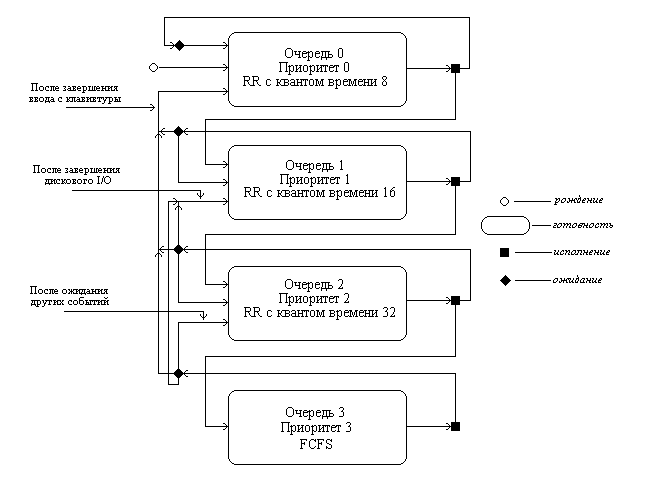
Рис. 10.Схема миграции процессов в многоуровневых очередях планирования с обратной связью. Вытеснение процессов более приоритетными процессами и завершение процессов на схеме не показано.
Родившийся процесс поступает в очередь 0. При выборе на исполнение он получает в свое распоряжение квант времени размером 8 единиц. Если продолжительность его CPU burst меньше этого кванта времени, процесс остается в очереди 0. В противном случае, он переходит в очередь 1. Для процессов из очереди 1 квант времени имеет величину 16. Если процесс не укладывается в это время, он переходит в очередь 2. Если укладывается — остается в очереди 1. В очереди 2 величина кванта времени составляет 32 единицы. Если и этого мало для непрерывной работы процесса, процесс поступает в очередь 3, для которой квантование времени не применяется, и, при отсутствии готовых процессов в других очередях, он может исполняться до окончания своего CPU burst. Чем больше значение продолжительности CPU burst, тем в менее приоритетную очередь попадает процесс, но тем на большее процессорное время он может рассчитывать для своего выполнения. Таким образом, через некоторое время все процессы, требующие малого времени работы процессора окажутся размещенными в высокоприоритетных очередях, а все процессы, требующие большого счета и с низкими запросами к времени отклика, — в низкоприоритетных.
Миграция процессов в обратном направлении может осуществляться по различным принципам. Например, после завершения ожидания ввода с клавиатуры процессы из очередей 1, 2 и 3 могут помещаться в очередь 0, после завершения дисковых операций ввода-вывода процессы из очередей 2 и 3 могут помещаться в очередь 1, а после завершения ожидания всех других событий из очереди 3 в очередь 2. Перемещение процессов из очередей с низкими приоритетами в очереди с большими приоритетами позволяет более полно учитывать изменение поведения процессов с течением времени.
Многоуровневые очереди с обратной связью представляют собой наиболее общий подход к планированию процессов из числа подходов, рассмотренных. Они наиболее трудоемки в реализации, но в то же время они обладают наибольшей гибкостью. Понятно, что существует много других разновидностей такого способа планирования помимо варианта, приведенного выше. Для полного описания их конкретного воплощения необходимо указать:
количество очередей для процессов, находящихся в состоянии готовность;
алгоритм планирования, действующий между очередями;
алгоритмы планирования, действующие внутри очередей;
правила помещения родившегося процесса в одну из очередей;
правила перевода процессов из одной очереди в другую;
Изменяя какой-либо из перечисленных пунктов, можно существенно менять поведение вычислительной системы.
Понятия об измерениях и единицах физических величин
Измерение – нахождение значения физической величины опытным путем с помощью специальных технических средств, например измерение размеров вала микрометром. За единицу физической величины принимают единицу измерения, определяемую установленным числовым значением, которое принято за исходную (основную или производную) единицу (например, метр – единица длины и т. п.).
Основное уравнение измерения имеет вид Q = qU, где Q иq– измеряемая физическая величина и ее числовое значение в принятых единицах; U– единица физической величины.
Измерения производят для установления действительных размеров изделий и соответствия их требованиям чертежа, а также для проверки точности технологической системы и подналадки ее для предупреждения брака.
Вместо определения значения физической величины часто проверяют, находится ли действительное значение этой величины (например, размер детали) в установленных пределах. Процесс получения и обработки информации об объекте (параметре детали, механизма, процесса и т. д.) с целью определения его годности или необходимости введения управляющих воздействий на факторы, влияющие на объект, называют контролем. При контроле деталей проверяют только соответствие действительных значений изометрических, механических, электрических и других параметров нормирования допускаемым значениям этих параметров, например, с помощью калибров (см. гл. 6).
Для введения единообразия в единицах измерения во всем мире на XI Генеральной конференции по мерам в 1960г. была принята Международная система единиц (СИ).
В СИ установлены семь основных единиц, используя которые, можно измерять все механические, электрические, магнитные, акустические и световые параметры, а также характеристики ионизирующих излучений и параметры в области химии. Основными единицами СИ являются: метр (м) – для измерения длины; килограмм (кг) – для измерения массы; секунда (с) – для измерения времени; ампер (А) – для измерения силы электрического тока; кельвин (К) – для измерения температуры; моль (моль) – для измерения количества вещества и кандела (кд) – для измерения силы света.
Кроме семи основных единиц, СИ устанавливает производные единицы, образованные с помощью простейших уравнений связи между физическими величинами. Так, единицу скорости образуют с помощью уравнения, определяющего скорость прямолинейно иравномерно движущейся точки: и = S/t, где u– скорость; S – длина пройденного пути: t– время движения точки. Подстановка вместо S и t их единиц СИ дает [u] = [S]/[t]= 1 м/с. Поэтому за единицу скорости СИ принят метр в секунду (м/с), равный скорости прямjлинейно и равномерно движущейся точки, при которой она за время 1 с проходит путь длиной в 1 м.
В системе СИ для обозначения десятичных кратных (умноженных на 10 в положительной степени) и дольных (умноженных на 10 в отрицательной степени) приняты следующие приставки: экса (Э) – 1018; пета (П) – 1015; тера (Т) – 1012;
гига (Г) – 109; мега (М) – 106; кило (К) – 103; гекто (г) – 102; дека (да) –101;
деци (д) – 10-1; санти (с) – 10-2; милли (м) – 10-3; микро (мк) – 10-6; нано (н) – 10-9; пико (п) – 10-12; фемто (ф) – 10-15; атто (а) – 10-18;
Дата добавления: 2015-04-01; просмотров: 1352;