Метрики связности по данным
Л. Отт и Б. Мехра разработали модель секционирования класса [55]. Секционирование основывается на экземплярных переменных класса. Для каждого метода класса получают ряд секций, а затем производят объединение всех секций класса. Измерение связности основывается на количестве лексем данных (data tokens), которые появляются в нескольких секциях и «склеивают» секции в модуль. Под лексемами данных здесь понимают определения констант и переменных или ссылки на константы и переменные.
Базовым понятием методики является секция данных. Она составляется для каждого выходного параметра метода. Секция данных — это последовательность лексем данных в операторах, которые требуются для вычисления этого параметра.
Например, на рис. 14.1 представлен программный текст метода SumAndProduct. Все лексемы, входящие в секцию переменной SumN, выделены рамками. Сама секция для SumN записывается как следующая последовательность лексем:
N1 • SumN1 • I1 • SumN2 • O1 • I2 • 12 • N2 • SumN3 SumN4 • I3.

Рис. 14.1.Секция данных для переменной SumN
Заметим, что индекс в «12» указывает на второе вхождение лексемы «1» в текст метода. Аналогичным образом определяется секция для переменной ProdN:
N1 • ProdN1 • I1 • ProdN2 •11 • I2 • 12 • N2 • ProdN3 • ProdN4 • I4
Для определения отношений между секциями данных можно показать профиль секций данных в методе. Для нашего примера профиль секций данных приведен в табл. 14.1.
Таблица 14.1.Профиль секций данных для метода SumAndProduct
| SumN | ProdN | Оператор |
| procedure SumAndProduct | ||
| (Niinteger; | ||
| varSumN, ProdNiinteger) | ||
| var | ||
| l:integer; | ||
| begin | ||
| SumN:=0 | ||
| ProdN:=1 | ||
| for l:=1 to N do begin | ||
| SumN:=SumN+l | ||
| ProdN:=ProdN*l | ||
| end | ||
| end; |
Видно, что в столбце переменной для каждой секции указывается количество лексем из i-й строки метода, которые включаются в секцию.
Еще одно базовое понятие методики — секционированная абстракция. Секционированная абстракция — это объединение всех секций данных метода. Например, секционированная абстракция метода SumAndProduct имеет вид
SA(SumAndProduct) = {N1 ∙ SumN1 ∙ I1 ∙ SumN2 ∙ 01 ∙ I2 ∙ I2 ∙ N2 ∙ SumN3 ∙ SumN4 ∙ I3,
N1 ∙ ProdN1 ∙ I1 ∙ ProdN2 ∙ I1 ∙ I2 ∙ I2 ∙ N2 ∙ ProdN3 ∙ ProdN4 ∙ I4}.
Введем главные определения.
Секционированной абстракцией класса (Class Slice Abstraction) CSA(C) называют объединение секций всех экземплярных переменных класса. Полный набор секций составляют путем обработки всех методов класса.
Склеенными лексемами называют те лексемы данных, которые являются элементами более чем одной секции данных.
Сильно склеенными лексемами называют те склеенные лексемы, которые являются элементами всех секций данных.
Сильная связность по данным (StrongData Cohesion) — это метрика, основанная на количестве лексем данных, входящих во все секции данных для класса. Иначе говоря, сильная связность по данным учитывает количество сильно склеенных лексем в классе С, она вычисляется по формуле:
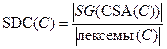 ,
,
где SG(CSA(C)) — объединение сильно склеенных лексем каждого из методов класса С, лексемы(С) — множество всех лексем данных класса С.
Таким образом, класс без сильно склеенных лексем имеет нулевую сильную связность по данным.
Слабая связность по данным (Weak Data Cohesion) — метрика, которая оценивает связность, базируясь на склеенных лексемах. Склеенные лексемы не требуют связывания всех секций данных, поэтому данная метрика определяет более слабый тип связности. Слабая связность по данным вычисляется по формуле:
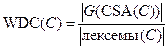 ,
,
где G(CSA(C)) — объединение склеенных лексем каждого из методов класса. Класс без склеенных лексем не имеет слабой связности по данным. Наиболее точной метрикой связности между секциями данных является клейкость данных (Data Adhesiveness). Клейкость данных определяется как отношение суммы из количеств секций, содержащих каждую склеенную лексему, к произведению количества лексем данных в классе на количество секций данных. Метрика вычисляется по формуле:
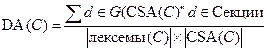 .
.
Приведем пример. Применим метрики к классу, профиль секций которого показан в табл. 14.2.
Таблица 14.2.Профиль секций данных для класса Stack
| array top size | Класс Stack |
| class Stack {int *array, top, size; | |
| public: | |
| Stack (int s) { | |
| 2 2 | size=s; |
| 2 2 | array=new int [size]; |
| top=0;} | |
| int IsEmpty () { | |
| return top==0}; | |
| int Size (){ | |
| return size}; | |
| intVtop(){ | |
| 3 3 | return array [top-1]; } |
| void Push (int item) { | |
| 2 2 2 | if (top= =size) |
| printf ("Empty stack. \n"); | |
| else | |
| 3 3 3 | array [top++]=item;} |
| int Pop () { | |
| if (IsEmpty ()) | |
| printf ("Full stack. \n"); | |
| else | |
| --top;} | |
| }; |
Очевидно, что CSA(Stack) включает три секции с 19 лексемами, имеет 5 сильно склеенных лексем и 12 склеенных лексем.
Расчеты по рассмотренным метрикам дают следующие значения:
SDC(CSA(Stack)) = 5/19 = 0,26
WDC(CSA(Stack)) = 12/19 = 0,63
DA(CSA(Stack)) =(7*2 + 5*3)/(19*3) = 0,51
Дата добавления: 2015-03-07; просмотров: 1299;