Новые подходы к анализу данных, измеренных по порядковым и номинальным шкалам
В последние годы как у нас в стране, так и за рубежом разработано довольно много математических методов, предназначенных для анализа данных, полученных с помощью измерения по номинальным п порядковым шкалам. Однако многие из них малознакомы широкому кругу социологов. В настоящем параграфе представлен краткий обзор таких методов. К сожалению, в силу сложности и большого объема материала нет возможности подробно изложить суть каждого метода и тем более описать конкретную методику его применения. Поэтому все излагаемое ниже можно рассматривать лишь как некоторое указание на то, к какой литературе необходимо обратиться для решения соответствующей задачи и какого рода вопросы необходимо поста; вить в этой связи перед математиком.
Наиболее распространенными задачами, при решении которых исследователь прибегает к помощи математических методов, являются задачи изучения связей между признаками, нахождения латентных переменных, классификации объектов.
Рассмотрим задачу изучения связей между признаками. В предыдущем разделе этой главы уже рассматривались меры связи между номинальными признаками, основанные на анализе таблиц сопряженности. Определенного рода обобщением способов измерения таких связей с помощью критерия c2 можно считать метод логлинейного анализа частотных таблиц. В отличие от упомянутых мер связи логлинейный анализ позволяет анализировать таблицы сопряженности любой размерности и проверять гипотезы о наличии сложных структур связи, состоящие из предположений о существовании связей внутри каждой из нескольких групп признаков одновременно. Принципы логлинейного анализа описаны в литературе достаточно подробно31.
В основе традиционных подходов к измерению связей между номинальными признаками лежит представление о последней как об «интегральной», т. е. о связи между рассматриваемыми признаками «в целом» (при расчете меры связи учитываются одновременно все те значения, которые эти признаки могут принимать). Однако такое понимание связи не является единственно возможным. Она может пониматься и как «локальная», т. е. как связь между отдельными значениями (одним или несколькими рассматриваемыми признаками). Наличие «интегральной» связи отнюдь не означает наличия «локальной», и наоборот. Так, вывод об отсутствии «интегральной» связи между полом и курением (например, основанный на малой величине c2) может не подтвердиться на основе «локального» анализа той же таблицы данных: т. е. можно предположить, что свойство респондента «быть мужчиной» довольно жестко определяет то, что этот человек курит (свойство «быть женщиной» в этом смысле может быть не связано с курением).
В настоящее время разработан довольно широкий круг методов анализа описанных «локальных» связей. В литературе они часто называются методами поиска детерминирующих комбинаций значений переменных (или взаимодействий последних)32. Прежде чем подробнее пояснить суть задачи и подходы к ее решению, введем некоторые обозначения.
Пусть изучается влияние каких-то I признаков (переменных), обозначаемых ниже х1, х2, ..., xi, па некоторый интересующий исследователя признак у. Признаки x2, хг, ..,, xi будем называть независимыми переменными, а признак у — зависимой переменной. Поясним, что имеется в виду под задачей поиска детерминирующих комбинаций значений переменных.
Исследователь полагает, что рассматриваемые независимые признаки в определенной степени обусловливают тип поведения изучаемых объектов, проявляющийся в том, какие значения для того, или иного объекта может принимать зависимая переменная. Другими словами, выдвигается гипотеза о соответствующей детерминации (типа поведения сочетаниями значений не зависимых переменных).
Упомянутый тип поведения может пониматься по-разному. Например, его можно определить как указание вероятностей, с которыми объект, обладающий заданным сочетанием значений ж, имеет то или иное значение. В таком случае тип поведения фактически отождествляется с распределением значений зависимого признака для объектов, имеющих рассматриваемый набор значений независимых признаков. Например, если при решении упомянутого (выше вопроса о связи пола респондента с привычкой к курению придем к выводу, что для мужчин вероятность иметь такую привычку равна 0,8, а не иметь ее — 0,2 и что для женщин аналогичные вероятности равны соответственно 0,3 и 0,7, то будем иметь основания говорить о двух типах поведения респондентов, каждый из которых определяется полом последних.
Можно тип поведения отождествить со средним арифметическим множества значений зависимой переменной для рассматриваемой совокупности объектов (в таком случае естественно предполагать, что значения у получены по интервальной шкале). Пусть, например, у — это время, затрачиваемое респондентом в течение дня на чтение газет, х — пол респондента, х2 — его образование. Если в процессе исследования мы обнаружим, что мужчины с высшим образованием тратят на чтение газет в среднем 1,5 часа в день, а женщины с начальным образованием — 0,01 часа, то можно будет говорить о двух типах поведения респондентов, каждый из которых соответствующим образом связан с рассматриваемыми независимыми признаками.
Тип поведения объекта можно отождествить и с тем, что для этого объекта у принимает определенное значение. Подчеркнем, что в любом случав упомянутая выше гипотеза о детерминации не может означать предположения о «жестком» определении значения по сочетанию значений х.
В соответствии с выдвинутой гипотезой исследователь ставит перед собой задачу выяснить, какие именно сочетания значений независимых признаков являются в интересующем его смысле детерминирующими (определяющими тип поведения объектов). Иногда к этому добавляется и задача выделения и числа независимых переменных подсовокупности признаков, наиболее информативных в том смысле, что по сочетанию именно их значений с наибольшей степенью уверенности можно судить о типе поведения объектов. В едином. Комплексе с этими задачами может решаться и задача выявления самих типов поведения, свойственных объектам изучаемой совокупности. Именно сочетание названных трех задач (может быть, без второй или третьей) и называется задачей поиска детерминирующих комбинаций значений переменных.
В соответствии с тем, как понимается тип поведения объектов, должен формироваться критерий, является ли тот или иной набор сочетаний значений х детерминирующим это поведение. Многообразие" методов поиска детерминирующих характеристик и объясняется в основном различием таких критериев.
Например, первому описанному выше пониманию типа поведения отвечает поиск такого разбиения исходной совокупности объектов (соответствующего определенному набору сочетаний значений х), что каждой выделенной подсовокупности будет соответствовать свое распределение значений у (степень различия распределений определяется в соответствии с известными статистическими критериями). Искомые детерминирующие комбинации — это те наборы сочетаний значений х, которые соответствуют выделенным подсовокупностям33.
Второму пониманию типа поведения отвечает такое разбиение исходной совокупности объектов, при котором каждая подсовокупность будет иметь свое среднее арифметическое значение у (т. е. разница между соответствующими средними значениями будет статистически значима)34. Отметим тесную связь такого подхода с, методами дисперсионного анализа, с помощью которого можно изучать влияние совокупности качественных признаков на некоторый количественный признак35. Однако дисперсионный анализ предназначен для изучения «интегральных» связей. Он исходит из априори заданных групп объектов — каждая группа соответствует одному возможному сочетанию значений независимых переменных и позволяет проверить гипотезу о совпадении типов поведения этих групп (тип поведения в дисперсионном анализе понимается именно рассматриваемым образом). Описываемые же нами методы решают более широкую задачу — они позволяют проанализировать стой же точки зрения все возможные группы объектов, соответствующие тому или иному набору сочетаний значений независимых переменных.
Подчеркнем, что при использовании описанных подходов ищутся не только сочетания значений независимых переменных, определяющих некоторые типы поведения, но и сами эти типы.
Для иллюстрации одного из возможных подходов к поиску детерминирующих комбинаций значений переменных при третьем упомянутом выше понимании типа поведения дадим некоторые определения, введенные С. В. Чесноковым36, и приведем пример из его же работы. Привлекательность методики поиска детерминирующих характеристик, предложенной этим автором, в том, что она по существу является формализацией рассуждений, наиболее часто использующихся социологом при практическом решении задач о статистической зависимости.
Рассмотрим случай, когда данные представлены таблицей 2 X 2, изучаемые объекты — респонденты, признак хпринимает значения а и b, а признак у — значения с и d. Назовем типом поведения респондента соответствующее ему значение у и ниже будем говорить о детерминации значением а тина поведения с. Очевидно, считать, что такая детерминация действительно имеет место, можно только в том случае, если достаточно велика «степень уверенности» в реализации поведения с для объекта со значением а независимой переменной. Уточним смысл такой уверенности.
Назовем интенсивностью детерминации а®с величину I(а®с), равную доле респондентов, для которых у = с в группе респондентов, удовлетворяющих условию: х=а. Интенсивность детерминации означает точность высказывания если а, то с. Назовем емкостью детерминации а®с величину с(а®с), равную доле респондентов, для которых х = а, в группе респондентов, удовлетворяющих условию у = с. Емкость детерминации измеряет долю случаев реализации поведения с, которая «объясняется» высказыванием «из а следует с». Емкость с(а®с) отражает, насколько всеобъемлюще объяснение, построенное на детерминации а®с, т. е. полноту этой детерминации.
Для обоснованности выводов о том, что «а влечет с», недостаточно знать, необходимо оценить и С.
Пример. Пусть х — пол (а — мужчина, b — женщина), а у — величина зарплаты (с — высокая, d — низкая). Предположим, что частотная таблица имеет вид
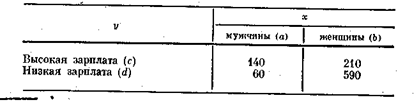
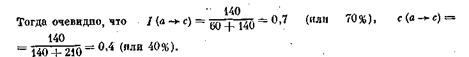
На основании того, что 70% мужчин имеют высокую зарплату, мы не можем говорить, что под детерминирует величину зарплаты. Для этого вывода необходимо еще оценить, какова доля мужчин среди лиц с высокой зарплатой. Например, если этот процент равен /, то сформулированный вывод вряд ли можно считать справедливым. Полученные же в рассматриваемом примере 40% могут способствовать обоснованию этого вывода, если исследователь сочтёт этот процент достаточно высоким.
Показатели, аналогичные введенным величинам I и С, легко можно определить и для того случая, когда количество независимых признаков более одного.
Очевидно, в отличие от тех ситуаций, когда тип понимается одним из двух описанных выше способов, в данном случае мы не выявляем типы поведения в процессе нахождения детерминирующих сочетаний. Такая задача решается отдельно для каждого значения зависимой, .переменной: фиксируя это значение (т.е. тип поведения), мы ищем такие сочетания значений независимых переменных, которые определяют его с достаточно высокими значениями I и С (смысл выражения «достаточно высокие» определяется исследователем).
Наряду с методами поиска детерминирующих комбинаций значений переменных разработаны подходы к выявлению связей между номинальными признаками, аналогичные методам регрессионного анализа. В последнее десятилетие был предложен ряд подходов к решению этого вопроса37. Опишем один из них.
Прежде всего заметим, что если все рассматриваемые переменные дихотомические, то, применяя к исходным данным технику обычного регрессионного анализа, будем получать содержательно интерпретируемые результаты38. Это связано с тем, что дихотомическую шкалу можно считать частным случаем интервальной. Приведем пример вычисления регрессионной зависимости между номинальными переменными, в котором реализуется метод, основанный на сделанном замечании.
Сначала каждая переменная, принимающая I значений, заменяется на I фиктивных дихотомических переменных: каждому исходному значению соответствует своя дихотомическая переменная.
Пусть X1 и Х2—исходные независимые номинальные переменные, принимающие каждая три значения — 1, 2, 3. Через х1, х2, x3, x4, x5, x6 обозначим вводимые фиктивные переменные (x1, х2, х3 соответствуют переменной Х1 а х4, х5, х6 — Х2). Значения, принимаемые фиктивными переменными, можно понять из следующей таблицы, где приведены значения X1 и X2 для некоторых трех объектов.

К полученным фиктивным переменным применяется обычная техника регрессионного анализа. Причем, поскольку зависимая переменная также заменена на k фиктивных переменных (если она принимает k значений), вместо одного уравнения рассчитывается k уравнений: для каждой упомянутой фиктивной переменной строится свое уравнение регрессии. Для оценивания влияния независимых переменных на зависимую в целом (а не на отдельные соответствующие ей фиктивные переменные) служит комплекс различных коэффициентов.
Аналогичный подход можно использовать и в случае, если зависимая
переменная получена по интервальной шкале39. Как уже отмечалось, помимо задачи анализа связей между переменными, довольно актуальными для социологии являются также задачи нахождения латентных переменных и классификации объектов. Правда, эти задачи очень часто можно рассматривать как частный случай задачи изучения связей: латентные факторы обычно находятся именно на основе анализа связей между наблюдаемыми признаками, а для осуществления классификации, как правило, анализируются связи между объектами. Но тем не менее названные задачи имеют и свою специфику, обусловленную их ролью в изучении интересующих социолога вопросов. Это обусловливает и определенную специфику соответствующих математических методов. Поэтому имеет смысл сказать несколько слов о путях решения обеих задач, когда изучаемые объекты характеризуются значениями номинальных или порядковых признаков40.
Поиск латентных переменных может осуществляться с помощью методов латентно-структурного анализа. Кроме того, возможны различные подходы к использованию традиционных методов факторного анализа для анализа данных, полученных по порядковой и номинальной шкалам41.
Основная проблема, встающая перед исследователем, желающим применить математические методы классификации к объектам, заданным значениями номинальных и порядковых признаков,— это проблема выбора меры близости между этими объектами. Большинство традиционных мер рассчитано на признаки, измеренные по интервальной шкале. Однако известны и такие меры, которые могут быть применены в интересующем нас случае. Выбор подходящей меры близости обеспечивает возможность использования многих методов классификации42.
Далее рассмотрим несколько разработанных советскими авторами общих подходов к задаче анализа качественных данных.
Первый подход предложен Г. С. Лбовым43. Автор предполагает, что исходные признаки могут быть измерены по любой шкале, и следующим образом вводит понятие логического высказывания, являющегося основным во всех предложенных им алгоритмах.
Если признак Хi измерен по номинальной шкале и а1i, а2i, ..., ali— его значения, то назовем элементарным высказыванием выражение вида xi= = аji (j=1, ..., р). Если признак xi измерен по шкале, тип которой не ниже порядковой шкалы, b и с — произвольные его возможные значения и b < с, то назовем элементарным высказыванием выражение вида b < хi < с.
Приведем пример логической закономерности. Пусть х1 — пол, принимающий два значения: 0 (мужчина) и 1 (женщина); хг — удовлетворенность респондента своей работой, измеренная по порядковой шкале с градациями 1 ..., 5; x3 — зарплата респондента, измеренная по шкале отношений (в руб.). Примером логического высказывания может служить выражение (х1 = 0) Ç (3 < х2 <=5) Ç (100 < x3 <=120). Ясно, что каждое логическое высказывание задает определенную область рассматриваемого признакового пространства.
Разработанный Г. С. Лбовым подход к анализу исходных данных, полученных по разным шкалам, с успехом позволяет решать задачи, подобные описанным выше задачам поиска детерминирующих комбинаций значений признаков. А именно автор предлагает алгоритм, согласно которому при любом разбиении исходной совокупности объектов па классы (это разбиение может быть осуществлено, в частности, в соответствии со значениями некоторого зависимого признака) для каждого такого класса может быть осуществлен поиск логических высказываний, выполняющихся (т. е. истинных) на принадлежащих ему объектах. Выполнение понимается в некотором статистическом смысле. Грубо говоря, выполнение высказывания для объектов какого-либо класса означает, что это высказывание истинно для большинства объектов этого класса.
Но тот же подход позволяет решать и гораздо более широкий круг встающих перед социологом задач: задачу автоматической классификации исходных объектов (грубо говоря, в разные классы попадают объекты, для которых выполняются разные логические высказывания); задачу построения логических решающих правил, т. е. «границ» между классами, если задано, в какой класс каждый объект входит (такие правила также определяются в терминах логических высказываний); задачу динамического прогнозирования (алгоритм использует логические решающие правила), и т. д.
Второй подход разработан группой исследователей под руководством Б. Г. Миркина44. Авторы этого подхода предлагают рассматривать каждый признак как некоторое отношение на множестве изучаемых объектов и задавать его в виде булевой матрицы, т. е. матрицы, элементы которой могут принимать только два значения, например 0 и 1. Приведем пример.
Пусть для некоторых четырех респондентов заданы значения признаков; пол (0 — мужчина, 1 — женщина) и профессия (принимающая значения 1, 2, 3, 4) и пусть соответствующая матрица «объект — признак» имеет вид
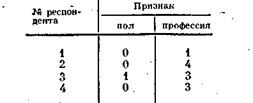
Тогда рассматриваемым признакам будут соответствовать следующие булевы матрицы:

На пересечении i-го столбца и j-й строки стоит единица, если значения рассматриваемых признаков для i-го и j-гообъектов совпадают, и 0 — в противоположном случае.
Авторы рассматриваемого подхода предлагают основанные на использовании описанного способа представления исходных данных методы решения широкого круга задач, в том числе и социологических: классификация объектов, изучение связей между признаками, выявление латентных переменных и т. д. Например, в качестве латентного фактора, объясняющего связи между несколькими исходными признаками, заданными матрицами, подобными описанным выше, будет выступать признак, заданный матрицей, в определенном смысле близкой ко всем исходным матрицам одновременно (первым шагом решения соответствующей задачи будет поиск таких групп исходных матриц, для каждой из которых подобную «среднюю» матрицу можно найти).
Интересный подход к анализу структуры связей между рассматриваемыми переменными в тех случаях, когда эти переменные измерены по произвольным шкалам, предложен Ю. Н. Гаврильцом45. Этот подход позволяет учитывать, что связь может быть прямой и опосредованной, тесной и слабой и т. д., что изменение значений части признаков может менять характер распределения у другой части признаков, в то время, как распределение третьей части признаков остается прежним. Основные принципы представления исходной информации, лежащие в основе этого подхода, являются слишком сложными для того, чтобы их можно было сформулировать в настоящем параграфе.
Последний подход к анализу информации, полученной по номинальной или порядковой шкале, о котором нам хотелось бы упомянуть,— это так называемая метризация используемых шкал («Оцифровка» значений признаков). Это — приписывание исходным шкальным значениям таких «меток», чисел, что отношения между получающимися интервалами начинают иметь содержательный смысл. К настоящему времени разработано довольно много способов такого превращения номинально» либо порядковой шкалы в интервальную46. Однако использовать их надо с большой осторожностью, поскольку каждый из этих способов предполагает довольно сильные и часто трудно проверяемые свойства исходных шкальных значений (эти предположения могут быть как содержательными, так и формальными).
В заключение настоящего раздела отметим, что большинство описанных в этой главе методов реализовано в имеющихся в различных научных центрах нашей страны комплексах программ для ЕС ЭВМ. Методы дискриптивной статистики, вычисления всевозможных мер связи, методы регрессионного анализа и другие методы многомерного статистического анализа, в том числе методы поиска детерминирующих характеристик значений независимых признаков, реализованы в системе «Социолог», применяемой в ИСИ АН СССР. Алгоритм поиска детерминационных характеристик, основанный на методе С. В. Чеснокова, представлен в системе, разработанной во ВНИИ системных исследований ГКНТ и АН СССР. Упомянутые выше алгоритмы, предложенные Г. С. Лбовым, реализованы в пакете программ ОТЕКС Института математики СО АН СССР.
Литература для дополнительного чтения
Вайнберг Дж.,Шумекер Дж. Статистика. М.: Статистика,1979.389 с.
Гласе Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс, 1976. 495 с.
Крамер Г. Математические методы статистики. М.: Мир, 1975.648 с.
Лбов Г. С. Методы обработки разнотипных экспериментальных данных. Новосибирск: Наука, 1981. 160 с.
Математические методы в социологическом исследовании Отв. ред. Т. В. Рябушкин и др. М.: Наука, 1981. 332 с.
Миркин Б. Г. Анализ качественных признаков и структур. М.: Статистика, 1980. 166 с.
Елисеева И. И., Рукавишников В. О. Группировка, корреляция, распознавание образов. М.: Статистика, 1977. 144 с.
Рунион Р. Справочник по непараметрической статистике. М.: Финансы и статистика, 1982. 198 с.
Рябушкин Т, В. Теория и методы экономической, статистики. М.: Наука, 1977. 511 с.
Статистические методы анализа информации в социологических исследованиях Отв. ред. Г. В. Осипов и др. М.: Наука, 1979. 319 с.
Типология и классификация в социологических . исследованиях Отв. ред.
В. Г. Андреенков, Ю. Н. Толстова, М.: Наука, 1982. 296 с.
Тюрин Ю. Н. Непараметрические методы статистики. М.: Знание, 1978. 62 с.
Дата добавления: 2015-02-19; просмотров: 1261;