Статистические взаимосвязи и их анализ
Понятие о статистической зависимости. Исходя из известного положения исторического материализма о всеобщей взаимозависимости и взаимообусловленности явлений общественной жизни, социолог-марксист не может ограничиться изучением отдельно взятого явления изолированно от других процессов и событий, а должен стремиться по возможности охватить весь комплекс явлений, относящихся к тому или иному социальному процессу и изучить существующие между ними зависимости.
Различают два вида зависимостей: функциональные (примером которых могут служить законы Ньютона в классической физике) и статистические.
Закономерности массовых общественных явлений складываются под влиянием Множества причин, которые действуют одновременно и взаимосвязанно. Изучение такого рода закономерностей в статистике и называется задачей о статистической зависимости. В этой задаче полезно различать два аспекта: изучение взаимозависимости между несколькими величинами и изучение зависимости одной или большего числа величин от остальных. В основном первый аспект связан с теорией корреляции (корреляционный анализ), второй — с теорией регрессии (регрессионный анализ). Основное внимание в этом параграфе уделено изучению взаимозависимостей нескольких признаков, а основные принципы регрессионного анализа рассмотрены очень кратко.
В основе регрессионного анализа статистической зависимости ряда признаков лежит представление о форме, направлении и тесноте (плотности) взаимосвязи.
В табл. 7 приведено эмпирическое распределение заработной платы рабочих в зависимости от общего стажа работы (условные 
данные) для выборки в 25 человек, а на рис. 9 эти численные данные представлены в виде так называемой диаграммы рассеяния, или разброса. Вообще говоря, визуально не всегда можно определить, существует или нет значимая взаимосвязь между рассматриваемыми признаками и насколько она значима, хотя очень часто уже на диаграмме просматривается общая тенденция в изменении значений признаков и направление связи между изучаемыми признаками. Уравнение регрессии. Статистическая зависимость одного или большего числа признаков от остальных выражается спомощью уравнений регрессии. Рассмотрим две величины х и у, такие, например, как на рис. 9. Зафиксируем какое-либо значение переменной х, тогда у принимает целый ряд значений. Обозначим у среднюю величину этих значений у при данном фиксированном х. Уравнение, описывающее зависимость средней величины ух от x называется уравнением регрессии у по х:
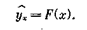
Аналогичным образом можно дать геометрическую интерпретацию регрессионному уравнению22
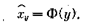
Уравнение регрессии описывает числовое соотношение между величинами, выраженное в виде тенденции к возрастанию (или убыванию) одной переменной величины при возрастании (убывании) другой. Эта тенденция проявляется на основе некоторого числа наблюдений, когда из общей, массы выделяются, контролируются, измеряются главные, решающие факторы.
Характер связи взаимодействующих признаков отражается в ее форме. В этом отношении полезно различать линейную и нелинейную регрессии. На рис. 10, 11 приведены графики линейной и криволинейной форм линий регрессии и их диаграммы разброса для случая двух переменных величин.
Направление и плотность (теснота) линейной связи между двумя переменными измеряются с помощью коэффициента корреляции.
Меры взаимозависимости для интервального уровня измерения.Наиболее широко известной мерой связи служит коэффициент корреляций Пирсона (или, как его иногда называют, коэффициент корреляции, равный произведению моментов). Одно из важнейших предположений, на котором покоится использование коэффициента г, состоит в том, что регрессионные уравнения для изучаемых переменных имеют линейную форму23, т. е.

где у — среднее арифметическое для переменной у; х — среднее арифметическое для переменной х; b1 и b2 - некоторые коэффициенты.
Поскольку вычисление коэффициента корреляции и коэффициентов регрессии b1 и b2 проводится по схожим формулам, то, вычисляя r, получаем сразу же и приближенные регрессионные модели24.

Выборочные коэффициенты регрессии и корреляции вычисляются по формулам
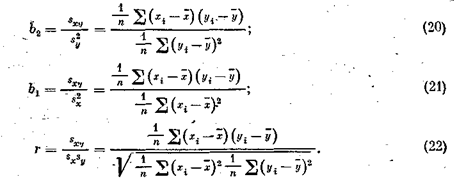
Здесь s2x —дисперсия признака х; s2x— дисперсия признака у.Величина sxy, называется ковариацией х и у.
Расчет r для не с группированных данных. Для вычислительных целей эти выражения в случае не сгруппированных данных можно переписать в следующем виде:
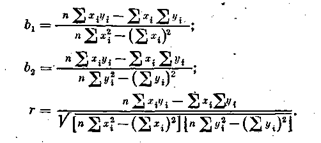
Рассчитаем коэффициент корреляции и коэффициенты регрессии для данных табл. 7:
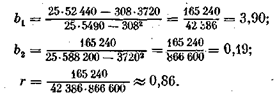
Тогда уравнение регрессии имеет вид
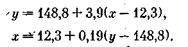
Линии регрессии y = F(x) изображены на рис. 10-. Отсюда видно, что между заработной платой и общим стажем работы существует прямая зависимость: по мере увеличения общего стажа работы на предприятии растет и заработная плата. Величина коэффициента корреляции довольно большая и свидетельствует о положительной связи между переменными величинами. Следует отметить, что вопрос о том, какую переменную в данном случае принимать в качестве зависимой величины, а какую — в качестве независимой, исследователь решает на основе качественного анализа и профессионального опыта. Коэффициент корреляции по определению является симметричным показателем связи: rxy = ryx. Область возможного изменения коэффициента корреляции г лежит в пределах от +1 до —1.
Вычисление r для сгруппированных данных. Для сгруппированных данных примем ширину интервала по каждой переменной за единицу (если по какой-либо переменной имеются неодинаковые размеры интервала, то возьмем из них наименьший). Выберем также начало координат для каждой переменной где-нибудь возле среднего значения, оцененного на глаз.
Для условных данных, помещенных в табл. 8, за нулевую точку отсчета выберем значение у, равное 64, а по x — значение 134,5.
Тогда коэффициент корреляции определяется по следующей формуле:
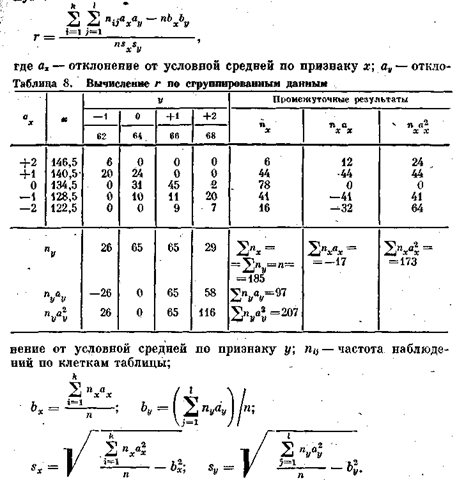
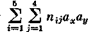
Для вышеприведенного примера порядок вычислений представлен в табл. 9. Для определения Snijaxby вычислим последовательно все произведения частоты в каждой клетке таблицы на ее координаты. Так
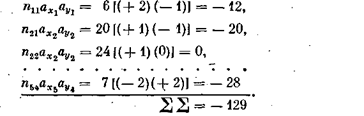

В соответствии с формулой вычисляем

Таким образом, величина связи достаточно велика, как, впрочем, и следовало ожидать на основе визуального анализа таблицы.
Статистическая значимость r. После вычисления коэффициента корреляции возникает вопрос, насколько показателен этот коэффициент и не обусловлена ли зависимость, которую он фиксирует, случайными отклонениями. Иначе говоря, необходимо проверить гипотезу о том, что полученное значение r значимо отличается от 0.
Если гипотеза H0 (r = 0) будет отвергнута, говорят, что величина коэффициента корреляции статистически значима (т. е. эта величина не обусловлена случайностью) при уровне значимости a.
Для случая, когда п < 50, применяется критерий t, вычисляемый по формуле
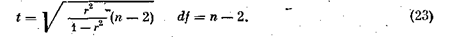
Распределение t дано в табл. В приложения.
Если п > 50, то необходимо использовать Z-критерий

В табл. А приложения приведены значения величины ZKp для соответствующих a.
Вычислим величину Z для коэффициента корреляции по табл. 7 (вычисление проделаем лишь для иллюстрации, так как число наблюдений п — 25 и нужно применять критерий t). Величина r (см. табл. 7) равна 0,86. Тогда
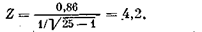
Для уровня значимости a = 0,01 ZKp = 2,33 (см. табл. А приложения).
Поскольку Z > ZKp, мы должны констатировать, что коэффициент корреляции г = 0,86 значим и лишь в 1 % случаев может оказаться равным нулю. Аналогичный результат дает и проверка по критерию t для а = 0,01 (односторонняя область); tкр— 2,509, tвыборочное равно 8,08.
Другой часто встречающейся задачей, является проверка равенства на значимом уровне двух коэффициентов корреляции. i = г2 при заданном уровне а, т. е. различия между r1 и r2 обусловлены лишь колебаниями выборочной совокупности.
Критерий для проверки значимости следующий:
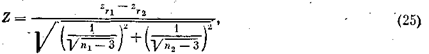
где значения zrj и zr находят по табл. Д приложения для r1 и r2.
Значения ZКp определяют по табл. А. приложения аналогично вышеприведенному примеру.
Частная и множественная регрессия и корреляция. Ранее нами было показано, как можно по опытным данным найти зависимость одной переменной от другой, а именно как построить уравнение регрессии вида у = а + bх. Если исследователь изучает влияние нескольких переменных х1, х2, ..., хk результатирующий признак y, то возникает необходимость в умении строить регрессионное уравнение более общего вида, т. е.
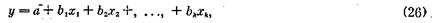
где a, b1,. b2, ..., bk — постоянные коэффициенты, коэффициенты регрессии.
В связи с уравнением (26) необходимо рассмотреть следующие вопросы: а) как по эмпирическим данным вычислить коэффициенту регрессии а, b1, b2…bк ; б)какую интерпретацию можно приписать этим коэффициентам; в) оценить тесноту связи между у и каждым из Xi в отдельности (при элиминировании действия остальных); г) оценить тесноту связи между у и всеми переменными х1, ..., xк в совокупности.
Рассмотрим этот вопрос на примере построения двухфакторного регрессионного уравнения. Предположим, что изучается зависимость недельного бюджета свободного времени (у) от уровня образования (хi) и возраста (х2) определенной группы трудящихся по данным выборочного обследования. Будем искать эту зависимость в виде линейного уравнения следующего вида:

При расчете коэффициентов уравнения множественной регрессии полезно преобразовать исходные эмпирические данные следующим образом. Пусть в результате обследования п человек получены эмпирические значения, сведенные в следующую таблицу (в каждом столбце представлены не сгруппированные данные):

Каждое значение переменной в таблице преобразуем по формулам
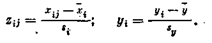
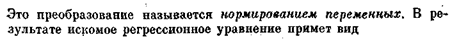
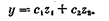
Коэффициенты с1 и сг находятся по следующим формулам

с1 и с2 называются стандартизированными коэффициентами регрессии. Следовательно, зная коэффициенты корреляции между изучаемыми признаками, можно подсчитать коэффициенты регрессии. Подставим конкретные значения rij из следующей таблицы25;

Коэффициенты исходного регрессионного уравнения b0, b1 и b2 находятся по формулам
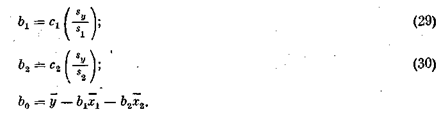
Подставляя сюда данные из вышеприведенной таблицы, получим b1= 3,13; b2= -0,17; b0= - 8,56.
Как же следует интерпретировать это уравнение? Например, значение b2 показывает, что в среднем недельный бюджет свободного времени при увеличении возраста на один год и при фиксированном признаке Xi уменьшается на 0,17 час. Аналогично интерпретируется b1. (Исходные эмпирические данные можно изобразить на диаграмме рассеяния аналогично тому, как это сделано на рис. 10, но уже в трехмерном пространстве (у, xt, х2).
Коэффициенты х1 и х2 можно в то же время рассматривать и как показатели тесноты связи между переменными у и, например, Xi при постоянстве хг.
Аналогичную интерпретацию можно применять и к стандартизированным коэффициентам регрессии сi. Однако поскольку ci вычисляются исходя из нормированных переменных, они являются безразмерными и позволяют сравнивать тесноту связи между переменными, измеряемыми в различных единицах. Например, в вышеприведенном примере Xi измеряется в классах, a x2 — в годах. C1и с2 позволяют сравнить, насколько z1 теснее связан с у, чем хг26.
Поскольку коэффициенты biи сi измеряют частную одностороннюю связь, возникает необходимость иметь показатель, характеризующий связь в обоих направлениях. Таким показателем является частный коэффициент корреляции
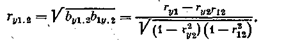
Для рассматриваемого примера ry1.2 = 0,558, rу2.1 i = —0,140.
Для любых трех переменных x1, х2, х3частный коэффициент корреляции между двумя из них при элиминировании третьей строится следующим образом:

Аналогично можно определить и частные коэффициенты корреляции для большего числа переменных (r12, 34 ...). Однако ввиду громоздкости вычисления они применяются достаточно редко.
Для характеристики степени связи результатирующего признака у с совокупностью независимых переменных служит множественный коэффициент корреляции R2y , который вычисляется по формуле (иногда он выражается в процентах)
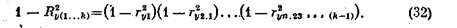
Так, для вышеприведенного примера он равен
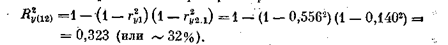
Множественный коэффициент корреляции показывает, что включение признаков х1 и х2 в уравнение

на 32% объясняет изменчивость результатирующего фактора. Чем больше Rt, тем полнее независимые переменные х2 ..., xk описывают признак у. Обычно служит критерием включения или исключения новой переменпой в регрессионное уравнение. Если Л мало изменяется при включении новой переменной в уравнение, то такая переменная отбрасывается.
Корреляционное отношение. Наиболее общим показателем связи при любой форме зависимости между переменными является корреляционное отношение h2. Корреляционное отношение h2у/х определяется через отношение межгрупповой дисперсии к общей дисперсии по признаку у:

где уi — среднее значение i-ro y-сечения (среднее признака у для объектов, у которых x=xi, т. е. столбец «г»); xi —среднее значение i-го x-сечения т. е. строка «i» nyi —число наблюдений в y сечении; nXi — число наблюдений в x-сечении; у — среднее значение у.
Величина h2у/х показывает, какая доля изменчивости значений у обусловлена изменением значения х. В отличие от коэффициента корреляции h2у/х не является симметричным показателем связи, т. е, h2у/х не равно h2х/y. Аналогично определяется корреляционное отношение х по у27.
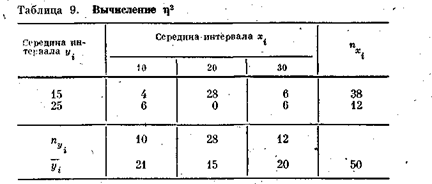
Пример.По данным таблицы сопряженности (табл. 9) найдем h2у/х. Вычислим общую среднюю

Сравнение статистических показателей r и h2у/х. Приведем сравнительную характеристику коэффициента корреляции (будем сравнивать r2) и корреляционного отношения h2у/х.
а) r2 = 0, если x и у независимы (обратное утверждение неверно);
б) r2 =h2у/х =1 тогда и только тогда, когда имеется строгая линейная функциональная зависимость у от х.
в) r2 = r\y/x<i тогда и только тогда, когда регрессия х и у строго линейна, но нет функциональной зависимости;
г) r2 <h2у/х < 1 указывает на то, что нет функциональной зависимости и существует нелинейная кривая регрессии.
Дата добавления: 2015-02-19; просмотров: 1152;