Защита данных при статистической обработке
Процедуры статистической обработки позволяют получить агрегированную информацию о подмножествах некоторого множества объектов (вычислении сумм, получении средних и т. п.). Рассмотрим только процедуры статистической обработки, реализующие вычислительные функции с арифметическими операциями: сложение, вычитание, умножение и деление.
Кроме обычных проблем предотвращения несанкционированного доступа к БД для статистических процедур существуют свои специфические проблемы защиты данных. Во многих случаях допускаются запросы типа «Подсчитать средний возраст сотрудников отдела», в то время как доступ к анкетным данным любого конкретного сотрудника отдела запрещен без специального разрешения.
Для решения этой проблемы в состав ЯМД вводятся специальные агрегатные функции для вычисления сумм и средних. Тогда в рабочие поля агрегатных функций попадают конкретные исходные данные, а в рабочие поля прикладных программ – значения сумм и средних. Однако агрегатные функции не решают вопрос полностью, поскольку, применяя одну и ту же функцию несколько раз и видоизменяя состав подмножества обсчитываемых объектов, можно путем сравнения получить интересующее конкретное данное к решению задачи.
Первый подход защиты данных заключается в том, что если и не исключить полностью возможность раскрытия индивидуальных данных, то по крайней мере сделать эту возможность достаточно трудной. Рассмотрим базу данных, содержащую п. записей. Пусть V={v1, v2, …, vn} – множество значений некоторого неключевого поля этих записей. Линейным запросом называется сумма 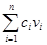 ,
,
где сi – произвольные действительные числа.
 Наиболее важными случаями линейных запросов являются суммы по множеству записей S, когда
Наиболее важными случаями линейных запросов являются суммы по множеству записей S, когда
если запись i принадлежит множеству S,
если запись i не принадлежит множеству S.
Если допускаются линейные запросы, продуцирующие (обрабатывающие) не менее т элементов (записей), и никакие два запроса не могут иметь более k общих элементов (общих записей) и если m>>k, то для вычисления некоторого неизвестного элемента (значения поля в интересующей нас записи) необходимо сделать не менее m/k запросов. Стратегия защиты заключается в увеличении этого отношения. Если ввести ограничения на структуру запросов, то можно исключить возможность раскрытия конкретных данных.
(Ограничить min размер группы и min количество общих элементов в группах).
Второй подход заключается в следующем. Если ключ записи состоит из х полей и в запросе допускается специфицировать не более у(у<х) полей ключа (т. е. выполняется поиск по частичному соответствию ключа), то никакая статистическая функция, использующая только операции сложения, вычитания, умножения и деления, не позволит определить значение данного в конкретной записи.
(Запрет выборки по полному ключу).
Дата добавления: 2015-02-10; просмотров: 864;