Лабораторная работа 7 ТЕХНОЛОГИИ И СИСТЕМЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
7.1. Характеристика информационно-аналитической
платформы «Deductor»
«Deductor» является аналитической платформой – основой для создания приложения СППР (системы поддержки принятия решений).
Платформа «Deductor» состоит из двух частей – многомерного хранилища данных «Deductor Warehouse» и аналитического приложения «Deductor Studio».
Хранилище данных предназначено для хранения информации, необходимой для анализа и выработки управленческих решений. При загрузке данных в хранилище автоматически выполняются все следующие действия:
· данные преобразовываются из плоских таблиц в многомерное представление;
· исключаются все дублирующиеся данные для уменьшения объемов базы данных;
· обеспечивается непротиворечивость информации;
· проводятся все необходимые манипуляции, позволяющие в 10–100 раз увеличить скорость извлечения необходимых данных из хранилища.
«Deductor Studio» – аналитическое ядро платформы «Deductor». В приложение «Deductor Studio» включены средства, позволяющие получить информацию из произвольного источника данных, провести полный цикл обработки (очистку, трансформацию данных, построение моделей), отобразить полученные результаты наиболее удобным образом (кросс-таблицы (кубы), таблицы, диаграммы, деревья решений) и экспортировать результаты в другие приложения, например, MS Word.
Типовой сценарий работы в платформе «Deductor» включает четыре процедуры:
· импорт данных;
· обработка;
· визуализация;
· экспорт данных.
Для вызова этих процедур используются специальные мастера: мастер импорта, мастер обработки, мастер визуализации, мастер экспорта.
В результате импорта данные приводятся к виду, пригодному для последующего анализа. В программе используются как механизмы прямого доступа к наиболее популярным базам данных, так и универсальные механизмы доступа ADO, ODBC. Импорт в приложение «Deductor Studio» осуществляется из файлов СУБД MS Access, MS SQL, Oracle, текстовых файлов, файлов MS Excel. Поддерживается работа с многомерным хранилищем данных «Deductor Warehouse».
Под обработкой в приложении «Deductor Studio» подразумевается любое действие, связанное с преобразованием данных, например, очистка, восстановление пропусков, фильтрация, построение модели и прочее. Набор механизмов обработки, реализованный в приложении «Deductor Studio», приведен в таблице 20.
Таблица 20 – Методы обработки в составе приложения «Deductor Studio»
| Метод | Описание |
| Нейронные сети | Предназначены для решения задач регрессии и классификации. Мощный современный самообучающийся механизм, способный решать нелинейные задачи |
| Деревья решений | Метод машинного обучения, позволяющий автоматически извлекать из данных закономерности, отображаемые в виде иерархической системы правил, легко интерпретируемых человеком. Предназначен для решения задач классификации |
| Самоорганизующиеся карты Кохонена | Одна из разновидностей нейронных сетей, реализующих обучение «без учителя». Позволяет кластеризовать данные и отображать их в виде специальных карт. При помощи карт легко находить группы схожих объектов, оценивать значимость факторов и выявлять зависимости |
Окончание таблицы 20
| Метод | Описание |
| Линейная регрессия | Классический линейный метод решения задачи регрессии |
| Автокорреляция | Нахождение линейной автокорреляционной зависимости. Метод применяется для обработки временных рядов для обнаружения периодичности, сезонности |
| Группировка/разгруп- пировка | Два взаимосвязанных метода обработки. Группировка позволяет объединять записи по полям-измерениям и агрегировать данные в полях-фактах. Разгруппировка разбивает полученные общие итоги в соответствии с рассчитанными пропорциями |
| Вычисляемые данные | Добавление полей, рассчитанных по заданным формулам |
| Фильтрация | Отбор записей в таблице по заданным условиям |
| Дубликаты и противоречия | Обнаружение и фильтрация дубликатов и противоречий |
| Квантование | Преобразование непрерывных данных в дискретные |
| Дата и время | Выделение из дат любого временного интервала (год, месяц, квартал и т. д.) |
| Скользящее окно | Трансформация временного ряда к скользящему окну |
| Комплексная обработка | Понижение размерности и устранение незначащих факторов |
| Парциальная обработка | Заполнение пропусков, редактирование аномалий, сглаживание, вычитание шума |
| Прогнозирование | Построение прогноза на основе модели, построенной любым способом. Например, при помощи нейросети или линейной регрессии |
Визуализация (отображение) результатов в приложении «Deductor Studio» проводится на любом этапе обработки. Пользователю предлагается широкий выбор способов визуализации, представленный в таблице 21.
Таблица 21 –Способы визуализации результатов анализа
| Способ | Описание |
| OLAP (Online Analytical Proces- sing) | Многомерное представление данных. Любые данные, используемые в программе, можно посмотреть в виде кросс-таблицы и кросс-диаграммы. Операции манипуляции многомерными данными – группировка, фильтрация, произвольное размещение измерений, детализация, выбор любого способа агрегации, отображение в абсолютных числах и в процентах |
| Таблица | Стандартное табличное представление с возможностью фильтрации данных |
| Диаграмма | График изменения любого показателя |
| Гистограмма | График разброса показателей |
| Статистика | Статистические показатели выборки |
| Диаграмма рассеяния | График отклонения прогнозируемых при помощи модели значений от реальных. Может быть построен только для непрерывных величин и только после использования механизмов построения модели, например, нейросети или линейной регрессии |
| Таблица сопряженности | Предназначена для оценки результатов классификации вне зависимости от используемой модели. Таблица сопряженности отображает результаты сравнения категориальных значений исходного выходного столбца и категориальных значений рассчитанного выходного столбца |
| Что-если | Позволяют «прогонять» через построенную модель любые интересующие пользователя данные и оценить влияние того или иного фактора на результат |
| Обучающая выборка | Выборка, используемая для построения модели. Выделяются данные, попавшие в обучающее, тестовое и валидационное множество с возможностью фильтрации |
| Диаграмма прогноза | Применяется после использования метода обработки Прогнозирование. Прогнозные значения выделяются цветом |
| Граф нейросети | Визуальное отображение весов обученной нейросети |
| Дерево решений | Отображение дерева решений, полученного при помощи соответствующего алгоритма. Имеется возможность посмотреть детальную информацию по любому узлу и фильтровать попавшие в него данные |
| Карта Кохонена | Отображение карт, построенных при помощи алгоритма Кохонена. Широкие возможности настройки – выбор количества кластеров, фильтрация по узлу (кластеру), выбор отображаемых полей |
| Описание | Текстовое описание параметров импорта (обработки, экспорта) в дереве сценариев обработки |
7.2. Нейронные сети в пакете «Deductor»
Нейронные сети – это вычислительные структуры, моделирующие простые биологические процессы, аналогичные процессам, происходящим в человеческом мозге. Нейросети способны к адаптивному обучению. В основе построения сети лежит элементарный преобразователь, называемый «искусственным нейроном».
Нейросеть состоит из нескольких слоев: входной, выходной и внутренние (скрытые) слои.
Входной слой реализует связь с входными данными, выходной – с выходными. Внутренних слоев может быть от одного и больше. В каждом слое содержится несколько нейронов. Структура многослойной нейронной сети показана на рисунке 53.
|
|
|
|
|
|
|
|
|
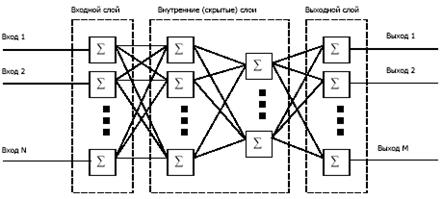
Рисунок 53 – Структура многослойной нейронной сети
Нейросеть способна имитировать какой-либо процесс. Любое изменение входов нейросети ведет к изменению ее выходов. Причем выходы нейросети однозначно зависят от ее входов.
Перед тем как использовать нейросеть, ее необходимо обучить. Для обучения следует подготовить таблицу с входными значениями и соответствующими им выходными значениями – обучающую выборку. По такой таблице нейросеть находит зависимости выходных полей от входных. Далее эти зависимости можно использовать, подавая на вход нейросети некоторые значения. На выходе будут восстановлены зависимые от них значения.
Нейронные сети используются для решения задач прогнозирования, классификации, кластеризации.
Задание 7.1.С помощью нейросети постройте модель ценообразования стоимости жилья в новостройках.
Задание выполните в следующем порядке:
1. Подготовьте обучающую выборку средствами табличного процессора MS Excel. Названия столбцов следует писать без пробелов. Сохраните файл цены.xls. Исходные данные представлены в таблице 22.
Таблица 22 – Исходные данные для обучения нейросети
| Этаж | Плошадь_ квартиры | Наличие_ балкона | Наличие_ телефона | Наличие_ отделки | Цена |
| Нет | Нет | Черновая | 18 000 | ||
| Да | Да | Частичная | 19 000 | ||
| Да | Да | Под ключ | 21 000 | ||
| Нет | Нет | Черновая | 36 000 | ||
| Да | Да | Частичная | 37 000 | ||
| Да | Да | Под ключ | 38 000 | ||
| Да | Да | Черновая | 18 000 | ||
| Нет | Да | Частичная | 17 500 | ||
| Да | Да | Под ключ | 21 000 | ||
| Нет | Нет | Черновая | 36 500 | ||
| Да | Да | Частичная | 37 500 | ||
| Да | Да | Под ключ | 39 000 |
2. Импортируйте данные из файла цены.xls в пакет «Deductor».
На панели инструментов Сценарии щелкните кнопку Мастер импорта. В окне Мастер импорта выберите в качестве источника MS Excel и щелкните кнопку Далее.
На втором шаге Мастера импорта в поле База данных укажите путь к файлу цены.xls, а в поле Таблица в базе данных укажите Лист1$. Щелкните кнопку Далее.
На третьем шаге Мастера импорта щелкните кнопку Пуск, а после завершения процесса – кнопку Далее.
На четвертом шаге Мастера импорта настройте назначение полей:
· Этаж – входное, Вид данных – непрерывный;
· Площадь_квартиры – входное, Вид данных – непрерывный;
· Наличие_балкона – входное;
· Наличие_телефона – входное;
· Наличие_отделки – входное;
· Цена – выходное.
Перейдите к следующему шагу мастера по кнопке Далее.
Выберите способы отображения данных Таблица, Куб.Щелкните кнопку Далее.
На шестом шаге Мастера импорта настройте назначение полей в кубе:
· Этаж – измерение;
· Площадь_квартиры – измерение;
· Наличие_балкона – измерение;
· Наличие_телефона – измерение;
· Наличие_отделки – измерение;
· Цена – факт.
На седьмом шаге мастера настройте предварительное размещение полей в кросс-таблице так, как показано на рисунке 54.
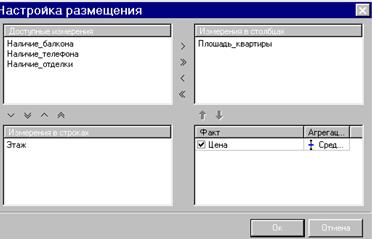
Рисунок 54 – Настройка размещения полей для OLAP-отчета
Введите имя для ветви сценария Цены_Жилье и щелкните кнопку Готово.
3. Постройте и обучите нейросеть.
Запустите Мастер обработки на панели Сценарии.
Выберите алгоритм Многослойная нейронная сеть и щелкните Далее.
На втором шаге Мастера обработки проведите настройку нормализации: целью нормализации значений полей является преобразование данных к виду, наиболее подходящему для обработки алгоритмом. Преобразуйте непрерывные значения полей Этаж и Площадь_квартиры к диапазону [0, 1]. Дискретные данные преобразуйте к набору уникальных индексов, упорядочив значения по принципу «лучшие – худшие».
На третьем шаге Мастера обработки укажите разбиение обучающей выборки на обучающее – 80% и на тестовое – 20%.
На четвертом шаге Мастера обработки опишите структуру нейросети:
· количество нейронов во входном слое – 5;
· скрытых слоев – 2;
· тип функции – сигмоида;
· крутизна – 1.
На пятом шаге Мастера обработки параметры настройки процесса обучения нейросети оставьте без изменений.
На шестом шаге мастера обработки установите следующие параметры:
· Считать пример распознанным, если ошибка меньше 0,05;
· По достижении эпохи – 1 000.
На седьмом шаге Мастера обработки нажмите кнопку Пуск и проследите за процессом обучения сети. Процесс обучения будет остановлен по достижении 1 000 повторов, желательно, чтобы процент распознанных примеров составлял 100.
На восьмом шаге Мастера обработки установите флажки для следующих способов отображения:
· Граф нейросети;
· Что-если;
· Обучающий набор;
· Диаграмма рассеяния.
На завершающем шаге Мастера обработки нажмите Готово.
Сохраните проект в своей папке под именем Прогноз_Жилье.
Проанализируйте и объясните полученные результаты.
С помощью визуализатора «Что-если» проверьте, какая прогнозируемая цена ожидается на квартиру площадью 36 м2 на пятом этаже, без балкона, с телефоном, частичным ремонтом.
Отобразите полученные результаты на диаграмме.
Задание 7.2. Постройте и обучите нейронную сеть для выдачи экспертного заключения о том, как поступать с акциями банков.
Сущность задачи заключается в следующем: имеется мнение эксперта, который на основе изучения соотношения затрат и прибыли финансовых учреждений рекомендует акционерам банков купить акции, придержать их или продать. Экспертные оценки занесены в таблицу – обучающую выборку. Нейронная сеть обучается на этих данных и учится самостоятельно формировать соответствующие выводы в случае предоставления ей новых данных.
Исходные данные представлены в таблице 23. Сформирован файл банки.xls.
Таблица 23 – Исходные данные для обучающей выборки
| Номер_Банка | Затраты | Прибыль | Рекомендации |
| 10,0 | 8,0 | Продать | |
| 15,0 | 17,0 | Купить | |
| 12,0 | 14,0 | Купить | |
| 14,0 | 15,0 | Купить | |
| 11,5 | 14,0 | Купить | |
| 13,0 | 12,5 | Держать | |
| 16,0 | 16,0 | Держать | |
| 14,6 | 17,0 | Купить | |
| 18,0 | 20,0 | Купить | |
| 16,5 | 17,0 | Держать | |
| 14,0 | 14,0 | Держать | |
| 15,0 | 12,0 | Продать | |
| 12,0 | 13,0 | Купить | |
| 11,0 | 12,0 | Купить | |
| 16,2 | 18,0 | Купить | |
| 14,8 | 14,0 | Держать | |
| 20,0 | 22,0 | Купить | |
| 17,0 | 15,0 | Продать | |
| 18,0 | 15,0 | Продать | |
| 14,0 | 14,0 | Держать |
Задание выполните в следующем порядке:
1. Загрузите пакет «Deductor Studio».
2. Запустите Мастер импорта, нажав клавишу F6. Загрузите обучающую выборку для нейросети путем импорта данных из файла банки.xls. В окне Мастер импорта (шаг 2) укажите путь к базе данных и имя таблицы Лист1$. Нажмите Пуск для запуска процесса на шаге 3.
3. В настройках импорта (шаг 4 Мастера импорта) установите типы полей:
· Номер банка – информационное;
· Затраты – входное;
· Прибыль – входное;
· Рекомендации – выходное.
4. Выберите способ отображения данных Таблица (шаг 5 Мастера импорта). На шаге 6 Мастера импорта нажмите кнопку Готово.
5. Переименуйте ветвь сценария, задав Данные по банкам.
6. Создайте и обучите нейросеть.
Запустите Мастер обработки, нажав клавишу F7.
Выберите метод Data Mining Нейросеть.
В окне Мастер обработки (шаг 2) проверьте назначение полей:
· Номер банка – информационное;
· Затраты – входное;
· Прибыль – входное;
· Рекомендации – выходное.
При необходимости проведите настройку нормализации полей, щелкнув по кнопке Настройка нормализации.
В окне Мастер обработки (шаг 3) настройте обучающую выборку, разбив ее на два множества – обучающее и тестовое. Обучающее множество составят 95% записей (это записи, которые будут использоваться непосредственно для обучения сети), остальные 5% войдут в тестовое множество (записи, используемые для проверки результатов обучения). Способ разделения исходного множества – случайно.
В окне Мастер обработки (шаг 4) настройте структуру нейросети:
· количество нейронов во входном слое – 2;
· количество скрытых слоев – 1;
· количество нейронов в скрытом слое – 2;
· количество нейронов в выходном слое – 1;
· тип активационной функции – сигмоида.
В окне Мастер обработки (шаг 5) выберите алгоритм обучения нейросети:
· Метод Resilent Propogation (Rprop) – эластичное распространение. Алгоритм использует так называемое «обучение по эпохам», когда коррекция весов происходит после предъявления сети всех примеров из обучающей выборки. Преимущество данного метода заключается в том, что он обеспечивает сходимость, а, следовательно, и обучение сети в 4–5 раз быстрее, чем алгоритм обратного распространения.
· Шаг спуска 0,5 (коэффициент увеличения скорости обучения при недостижении алгоритмом оптимального результата).
· Шаг подъема 1,2 (коэффициент уменьшения скорости обучения в случае пропуска алгоритмом оптимального результата).
В окне Мастер обработки (шаг 6) задайте условия, при выполнении которого обучение будет прекращено:
· считать пример распознанным, если ошибка меньше 0,05;
· по достижении эпохи (циклов обучения) – 1 000.
В окне Мастер обработки (шаг 7) щелкните кнопку Пуск для запуска процесса обучения нейросети.
В окне Мастер обработки (шаг 8) установите флажки для выбора визуализаторов Граф нейросети, Что-если, Обучающий набор, Таблица сопряженности. Нажмите Далее и Готово.
7. Изучите полученные результаты, рассмотрев результаты на имеющихся визуализаторах. Выясните, какой процент случаев распознан на обучающем и тестовом множествах. Примените нейросеть, чтробы определить, какое решение следует принять, если:
· прибыль и затраты по 20;
· прибыль 15, затраты 17;
· прибыль 18, затраты 14.
Дата добавления: 2014-12-24; просмотров: 4824;