Каждый атрибут таблицы зависит от ключа, от всего ключа, ни от чего, кроме ключа.
Индексы
Общие сведения
Индексирование таблиц – это способ отсортировать данные по определенной колонке. Когда список отсортирован, намного проще производить поиск необходимых данных.
Представьте себе большую книгу, в которой Вам необходимо найти информацию о каком-нибудь предмете, например, варианты приготовления блюда. Можно попробовать быстро пролистать всю книгу и отыскать все необходимые рецепты, однако логичнее открыть предметный указатель, найти нужное название, страницы, на которых оно упоминается, и читать уже только эти страницы.
Почему с предметным указателем работать быстрее, чем просто перебирать всю книгу? Во-первых, в указателе описаны только нужные параметры, те, по которым ищут чаще всего. Например, заголовки тем или названия блюд. Во-вторых, данные в указателе отсортированы в алфавитном порядке, что сильно ускоряет поиск.
Индексы устроены по такому же принципу. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке. При поиске происходит последовательный просмотр таблицы строка за строкой, это может занимать очень много времени. Если создать индекс – упорядоченный набор ссылок на строки таблицы – поиск данных может стать значительно быстрее.
Итак, индекс – это упорядоченный набор значений из индексированного столбца (или нескольких столбцов) с указателями на места физического размещения строк в структуре базы данных.
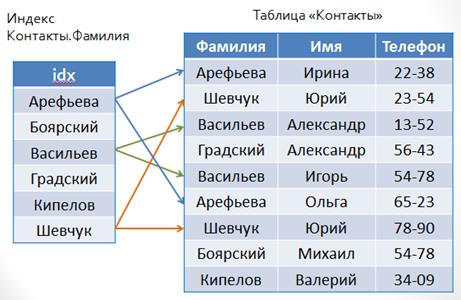
Индекс – это отдельный объект базы данных, который привязывается к конкретным столбцам таблицы (индексируемым столбцам).
Индексы бывают кластерными (CLUSTERED) и не кластерными (NONCLUSTERED).
Кластерные индексы
Для начала разберемся, как физически хранятся данные в БД.
· Данные хранятся небольшими блоками – страницами. Каждая страница данных в SQL Server содержит 8 килобайт информации. Группа из восьми стоящих рядом страниц называется пространством.
· Строки данных не хранятся в каком-либо определенном порядке, также нет определенного порядка для последовательности страниц.
· Когда строка вставляется в страницу и страница переполнена, страница разделяется.
· Неотсортированный набор страниц данных, содержащих строки одной таблицы, называется кучей.
Рассмотрим таблицу «Контакты». Данные хранятся в страницах безо всякой сортировки.
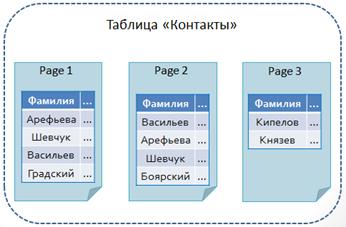
При определении кластерного индекса строки физически сортируются на диске в соответствии с индексируемым полем. Кластерный индекс в таблице может быть только один (нельзя же одновременно физически отсортировать данные по двум полям).
При добавлении новой строки в таблицу, она дописывается не в конец списка, а в нужное место таблицы, соответствующее ей по сортировке. При необходимости происходит также перестроение верхних уровней индекса.
В SQL Server индексы хранятся в виде B-деревьев (B-tree). «B» означает «сбалансированное» (не путать с бинарным), т.е. длина любых двух путей в дереве от корня (верхнего уровня) до листов (нижних уровней) различается не более, чем на единицу.
Рассмотрим процесс добавления данных в таблицу «Контакты» (для таблицы уже определен кластерный индекс). Изначально таблица содержит три записи, которые физически отсортированы по столбцу «Фамилия» (на схеме отображен только этот столбец). Будем считать, что в одной странице данных можно разместить не более 4 записей. Тогда при добавлении 4 новых строк страница с данными разделяется на две, причём в том узле (на той странице), где раньше были данные, теперь располагается индекс, охватывающий обе новые страницы. Один элемент индекса указывает на одну страницу данных.
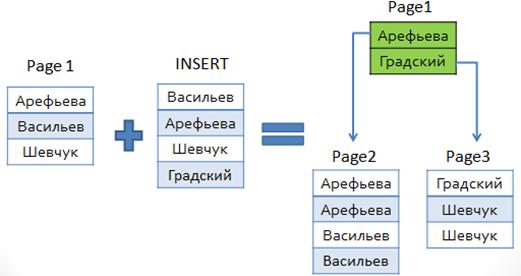
При дальнейшем добавлении данных в таблицу индекс разрастается, появляются новые уровни. Использование кластерного индекса подразумевает, что в его листьях хранятся записи таблиц (а не ссылки на них).
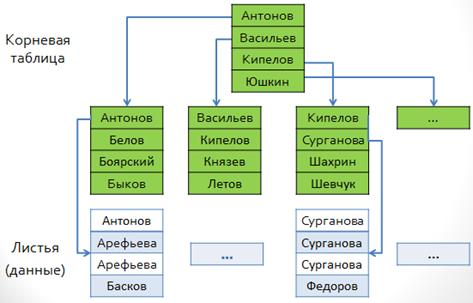
При создании в таблице первичного ключа (PRIMARY KEY) сервер автоматически создает для него кластерный индекс, если его не существовало ранее или если при определении ключа не был явно указан другой тип индекса.
Дата добавления: 2018-09-24; просмотров: 748;