Идентификация эмпирических математических моделей
Переход к эмпирическим моделям предполагает заведомый отказ от аналитических методов исследования. Поэтому эмпирические модели более разнообразны и включают в себя различные по форме математические зависимости.
При разработке эмпирической математической модели предполагается использование экспериментальных данных, полученных при испытаниях объектов. Результаты таких испытаний всегда представляют собой наборы величин, характеризующих работу объекта или системы при различных сочетаниях управляющих параметров.
Наиболее эффективным средством представления результатов экспериментов в системах математического моделирования являются эмпирические модели.
 При построении эмпирической модели обычно предполагается, что физическая теория работы объекта отсутствует или по тем или иным причинам не может быть использована.
При построении эмпирической модели обычно предполагается, что физическая теория работы объекта отсутствует или по тем или иным причинам не может быть использована.
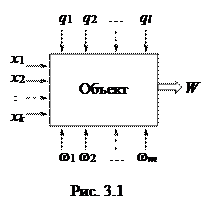
Объект идентификации представляет собой так называемый «черный ящик» с некоторым числом регулируемых (или, по крайней мере, измеряемых) входов х и одним или несколькими наблюдаемыми (измеряемыми) выходами (Рис. 3.1).
Здесь xi – управляющие переменные; wi – неопределенности (шумы); qi – ограничения; W – характеристическая функция.
Задачей идентификации является построение модели объекта по результатам наблюдений его реакции на возмущения внешней среды.
При этом необходимо учитывать ошибки, возникающие при измерении характеристик объекта.
Требуется построить зависимость (модель)
W = f(x),
которая описывает характеристики изучаемой системы.
Это уравнение называется уравнением регрессии и описывает поверхность (гиперповерхность) отклика, характеризующую эмпирическую модель.
Обычно предполагается, что имеющиеся экспериментальные данные дают достаточно информации для воссоздания математического описания объекта.
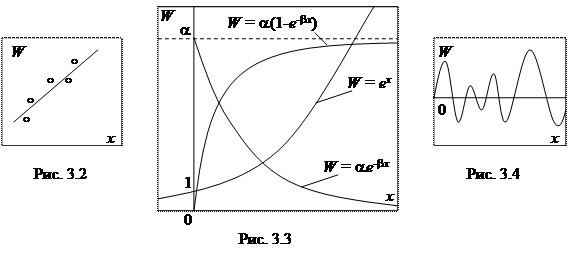
На рис. 3.2 показано решение задачи идентификации для некоторого набора данных, полученное с помощью линейной регрессионной зависимости: W = a + bx.
 |
Идентификацию модели начинают с выбора формы модели, т.е. вида функции f(x). При этом на практике может встретиться два случая:
1) Форма математической модели известна заранее, а задача идентификации сводится к определению коэффициентов этой модели. Так, описание ряда затухающих или развивающихся процессов дается зависимостями экспоненциального типа (Рис. 3.3). Задача исследования является определение коэффициентов a, b.
2) Форма математической модели заранее неизвестна. В этом случае для идентификации модели используются отрезки бесконечных рядов, а задача заключается в определение числа членов ряда и коэффициентов при этих членах. Модель может быть представлена в виде
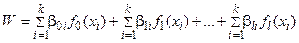 ,
,
где fq(xi) – некоторые заданные функции; bqi – коэффициенты регрессии; q = 0, 1,…, l.
В одномерном случае (k = 1) уравнение принимает вид
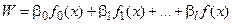 .
.
Конкретный вид модели зависит от выбора функций fq(x), по которым производится разложение W. Например, при описании колебательных процессов удобно использовать ряд Фурье 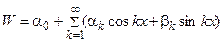 (Рис. 3.4).
(Рис. 3.4).
Часто в качестве функций f0(x), f1(x), f2(x),…, fl(x) выступают степенные функции
х0, х1, х2,…, хl. Если ограничиться первыми членами разложения, то уравнения сведутся к линейным, квадратичным и другим полиномиальным моделям. Однако пока остается не ясным, сколько членов ряда обеспечивает наилучшее описание изучаемого процесса.
 Обычно берут количество экспериментальных точек значительно больше, чем количество коэффициентов регрессии. В этом случае нельзя построить поверхность отклика, проходящую через все экспериментальные точки. Да этого и не требуется. При этом, однако, можно построить приближенную модель, обеспечивающую в некотором смысле наилучшее совпадение с экспериментальными данными.
Обычно берут количество экспериментальных точек значительно больше, чем количество коэффициентов регрессии. В этом случае нельзя построить поверхность отклика, проходящую через все экспериментальные точки. Да этого и не требуется. При этом, однако, можно построить приближенную модель, обеспечивающую в некотором смысле наилучшее совпадение с экспериментальными данными.
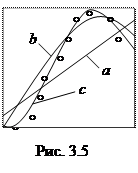
Например, прямая a построена по 10-ти экспериментальным точкам методом наименьших квадратов (Рис. 3.5); кривая b – квадратичная модель; с – полиномиальная модель 3-го порядка достаточно хорошо соответствует исходному экспериментальному материалу, хотя проходит не через все экспериментальные точки.
Таким образом, для любой экспериментальной выборки могут быть предложены различные модели идентификации. Конкретная форма модели зависит от выбора функций fq(x) и количества членов ряда.
Сама постановка задачи идентификации включает в себя элемент неопределенности, возможность множественности решений. Важно выбрать лучшее или, по крайней мере, достаточно хорошее из этих решений.
Для оценки точности модели естественно использовать величины отклонений, полученных в эксперименте величин Wj и их оценок Wmj , предсказанных моделью
ej = Wj – Wmj. (3.1)
Исключительное распространение получил метод наименьших квадратов отклонений реальных значений оцениваемой величины от значений, предсказанных моделью.
Специальные методы планирования эксперимента позволяют существенно повысить объем получаемой информации, улучшают характеристики эмпирических моделей, а также упрощают процедуру обработки экспериментальных данных. Однако на практике очень часто приходится иметь дело с неорганизованным (пассивным) экспериментом. Связано это, по крайней мере, с тремя причинами:
1) Исследователь может только наблюдать входы системы, но не может их регулировать, что полностью исключает возможность планирования эксперимента (типичная ситуация: астроном – галактика).
2) Неизвестны диапазоны возможного изменения переменных (входов), что затрудняет планирование эксперимента и исключает возможность использования ряда эффективных методов планирования.
3) Приходится строить модели идентификации на основе уже полученных ранее беспорядочных экспериментальных данных.
Дата добавления: 2018-09-24; просмотров: 1345;