Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок. 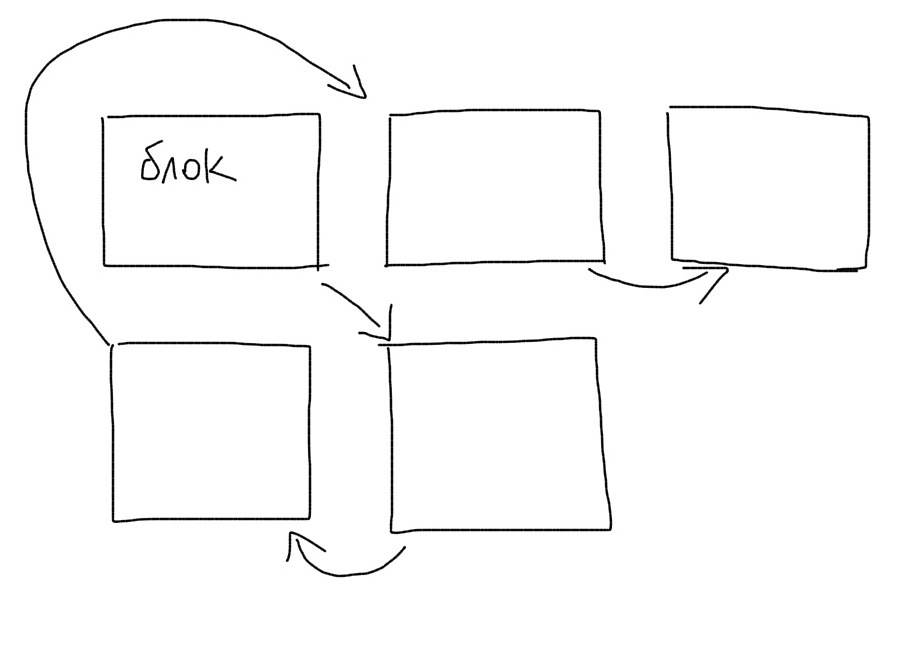
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
Поиск данных в MySQL
Таблицы MySQL — это обычные файлы. Выполним запрос такого вида:
SELECT * FROM users WHERE age = 29MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицысо значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные: 
Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения:
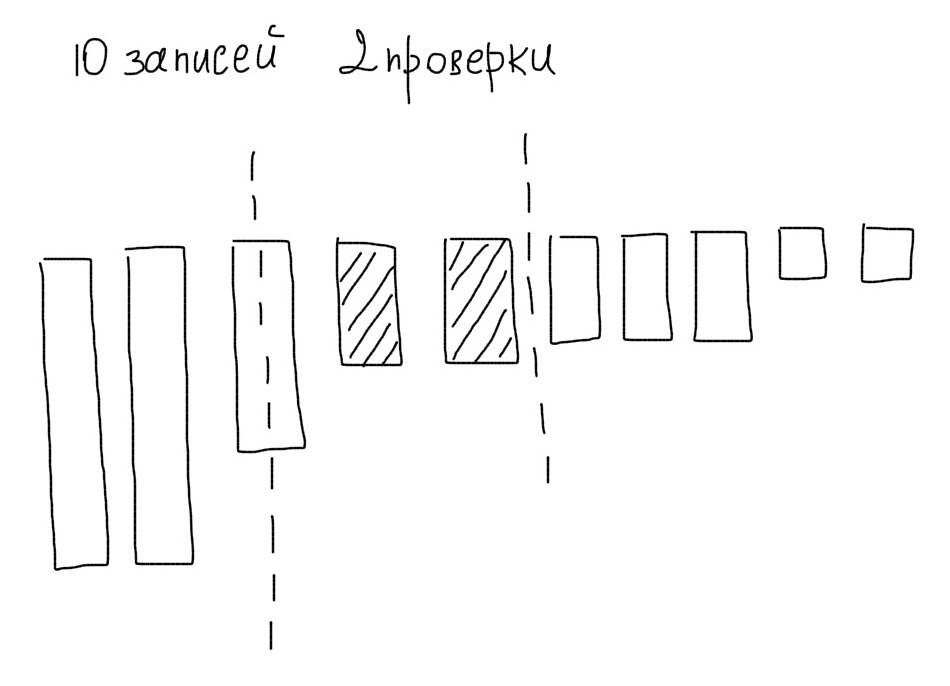
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
Индекс — это и есть отсортированный набор значений. В MySQL индексы всегда строятся для какой-то конкретной колонки. Например, мы могли бы построить индекс для колонки age из примера.
Дата добавления: 2017-08-01; просмотров: 575;