Виды моделей данных
Ядром любой БД является модель данных. Модель данных – это совокупность структуры данных и операций их обработки.
Кратко рассмотрим основные виды моделей данных и выявим их основные преимущества и недостатки, при этом будем учитывать факторы, характеризующие принципиальные особенности моделей, а также факторы, связанные с реализацией этих моделей на ЭВМ.
1. Иерархическая модель данных. Представляет собой совокупность элементов, связанных по строго определенным правилам. Объекты, связанные иерархическими отношениями образуют ориентированный граф. Основными понятиями иерархической модели данных являются: уровень, узел (или элемент) и связь. Такая модель данных обладает следующими свойствами:
· каждый узел связан только с одним вышестоящим узлом, кроме вершины;
· иерархическая модель данных имеет только одну вершину, узел не подчинен более никаким узлам;
· от каждого узла существует единственный путь к вершине;
· связь не может быть установлена между объектами, находящимися через уровень;
· связь между узлами первого уровня не определяется.
Примеры.
1) Файловая структура организации информации.
2) Структура организации (директор, заместитель, руководители отделов, сотрудники) (рис.1.3).
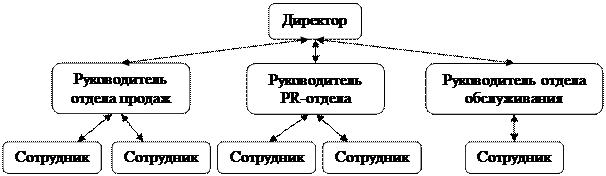
Рис. 1.3. Иерархическая структура данных
Преимущества:
1. Простота.
2. Минимальный расход памяти.
Недостатки:
1. Отсутствие универсальности – не всякую информацию можно выразить в иерархической модели данных.
2. Исключительно навигационный принцип доступа к данным.
3. Доступ к данным только через корневой элемент.
2. Сетевая модель данных. Элементами этой модели являются: уровень, узел, связь. Отличия в том, что элемент одного уровня может быть связан с любым количеством элементов соседнего уровня, и не существует подчиненности уровней друг другу.
Свойства сетевой модели:
· связь не может быть установлена между объектами, находящимися через уровень;
· связь между узлами первого уровня не определяется.
Пример. Рассмотрим работу над проектами: можно выделить три вида объектов – сотрудники, проекты, заказчики (рис.1.4).
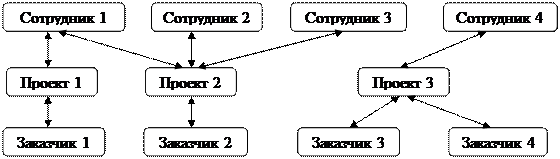
Рис. 1.4. Сетевая структура данных
Преимущества:
1. Универсальность.
2. Возможность доступа к данным через значения нескольких отношений.
Недостатки:
1. Сложность – обилие понятий, вариантов их взаимосвязей и способов реализации.
2. Допустимость только навигационного принципа доступа к данным.
3. Реляционная модель данных (табличная). Это способ представления данных в виде таблиц. Элементы: поле (столбец), запись (строка) и таблица (отношение). В дальнейшем мы будем рассматривать именно реляционную модель данных, которая используется в реляционных системах. Под реляционной системой понимается система, основанная на следующих принципах:
· данные пользователя представлены только в виде таблиц;
· пользователю предоставляются операторы, генерирующие новые таблицы из старых (для выборки данных).
Пример. Рассмотрим отношения Студенты и Группы:
Students:
| StudentID | LastName | FirstName | MiddleName | GroupID |
| Казаков | Петр | Владимирович | ||
| Васильев | Иван | Аркадьевич | ||
| Шишкина | Дарья | Сергеевна |
Groups:
| GroupID | Supervisor |
| Царев С.М. | |
| Пестов Д.Н. |
Преимущества:
1. Простота. В такой модели всего одна информационная конструкция, формализующая табличное представление. Она наиболее привычна для пользователя.
2. Теоретическое обоснование. Существуют строгие методы нормализации данных в таблицах (будет подробно рассмотрено в лекциях 10-11).
3. Независимость данных. При изменении БД, ее структуры необходимы бывают лишь минимальные изменения прикладных программ.
Недостатки:
1. Низкая скорость, т.к. требуются операции соединения.
2. Большой расход памяти в силу организации всех данных в виде таблиц.
4. Система инвертированных списков – система индексов. Систему инвертированных списков можно рассматривать как частный случай сетевой модели данных, которая имеет два уровня. Основные элементы: основной файл, инвертированный список (файл), список связей. В такой системе имеется несколько основных файлов, имеющих единую сквозную нумерацию.
Пример. Рассмотрим объекты Сотрудники и Зарплата.
Сотрудники:
| Сотрудник | Должность |
| 01 Иванов | программист |
| 02 Сидоров | лаборант |
| 03 Шишкин | преподаватель |
| 04 Васильев | преподаватель |
Зарплата:
| Сотрудник | Дата | Сумма |
| 05 Иванов | 1.10.2008 | |
| 06 Сидоров | 5.10.2008 | |
| 07 Иванов | 3.12.2008 | |
| 08 Шишкин | 3.12.2008 | |
| 09 Васильев | 25.01.2009 | |
| 10 Васильев | 27.01.2009 |
Инвертированный список может быть сформирован по любому полю основных списков, в нем каждому значению сопоставляется список номеров (индексов).
Пример: инвертированный список Должность:
· программист – 01;
· лаборант – 02;
· преподаватель – 03, 04
Список связей составляется только по основным столбцам.
Пример: рассмотрим два списка связей:
· Сотрудники – Зарплата:
o 01 – 05, 07
o 02 – 06
o 03 – 08
o 04 – 09, 10
· Зарплата – Сотрудники:
o 05 – 01
o 06 – 02
o 07 – 01
o 08 – 03
o 09 – 04
o 10 – 04
Инвертированные списки являются основой для создания информационно-поисковых систем (ИПС). В ИПС ключевые атрибуты соответствуют ключевым словам, определяющим тематику поиска.
Так как недостатки реляционной модели данных компенсируются ростом быстродействия и ресурсов современных компьютеров, то в настоящее время именно такие модели получили наибольшее распространение.
Архитектура БД
Существует архитектура БД, предложенная исследовательской группой ANSI/SPARC[1] и называется архитектурой ANSI/SPARC.
Каждая система баз данных не обязана соответствовать этому определению, например, «малые» системы, весьма вероятно, не будут поддерживать все функции предложенной архитектуры. Тем не менее, рассматриваемая архитектура с достаточной точностью описывает большинство систем (и не только реляционных).
Принято выделять три уровня в архитектуре СУБД.
1. Внутренний уровень (называемый также физическим) наиболее близок к физическому хранилищу информации, т.е. связан со способами хранения информации на физических устройствах. Внутренний уровень отображает физические элементы для хранения информации. Он представляет собой бесконечное адресное пространство, из которого информация проецируется на внешние носители.
2. Внешний уровень (называемый также пользовательским) наиболее близок к пользователям, т.е. связан со способами представления данных для отдельных пользователей (прикладной программист или конечный пользователь). Для каждого пользователя может существовать свой язык СУБД. Для прикладного программиста – это язык программирования, а для конечного пользователя – это язык, основанный на меню, формах и т.д. Но все эти языки включают язык данных, встроенный в СУБД. Для каждого отдельного пользователя может быть интересна некоторая отдельная часть БД. Такие части, с которыми работает пользователь, называются внешним представлением.
3. Концептуальный уровень (называемый также логическим) является «промежуточным» уровнем между двумя первыми. Это представление всей информации БД в более абстрактной форме. На этом уровне хранятся собственно данные, независимые от формы их представления. Концептуальное представление состоит из множества экземпляров данных. Данные здесь представлены в виде концептуальной схемы. Кроме самих данных в эту схемы могут быть включены определения дополнительных средств, например, правила обеспечения целостности.
Подробная схема архитектуры системы баз данных представлена на рис. 1.5.
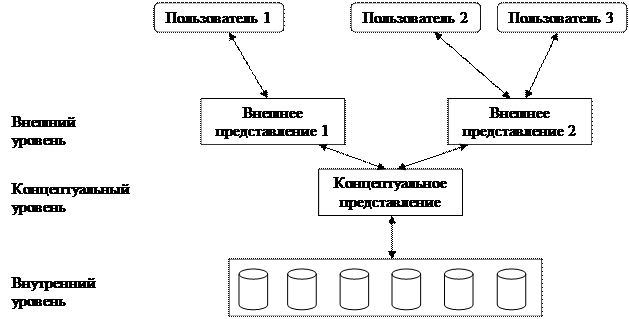
Рис. 1.5. Уровни архитектуры систем баз данных
Классификация БД
Базы данных классифицируют по различным признакам, рассмотрим основные из них.
1. По технологии обработки.
· Централизованные. Хранятся в памяти одной вычислительной системы.
· Распределенные. Состоят из нескольких, возможно пересекающихся частей, хранящихся в различных узлах вычислительной сети.
2. По способу доступа к данным.
· С локальным доступом. Характеризуется тем, что к такой БД имеется доступ пользователя одной ЭВМ.
· С удаленным (сетевым) доступом. Доступно для всех пользователей сети.
3. По архитектуре.
· Файл-сервер. Предполагает выделение одной машины в сети в качестве центральной (сервер файлов), на ней хранится централизованная БД, которая используется совместно.
· Клиент-сервер. Предполагается выделение сервера БД, который кроме хранения осуществляет обработку данных. Систему БД можно рассматривать как систему, состоящую из двух частей: сервер и набор клиентов. Сервером БД называется собственно СУБД, а клиентами – различные приложения, которые выполняются над СУБД.
4. По содержимому.
· Географические.
· Исторические.
· Научные.
· Мультимедийные.
· и т.д.
Краткие итоги. Рассмотрены основные понятия баз данных, представлены различные классификации систем управления базами данных. Определены основные модели данных, которые используются в конкретных реализациях СУБД: иерархическая, сетевая, реляционная и система индексов.
[1] ANSI/SPARC (American National Standards Institute / Standards Planning and Requirements Committee – Американский национальный институт стандартов / Комитет планирования стандартов) – исследовательская группа в рамках Американского национального института стандартов. Архитектура ANSI/SPARC была предложена в 1975 году.
Дата добавления: 2017-02-20; просмотров: 22691;