Уровни изолированности пользователей
Достаточно легко убедиться, что при соблюдении двухфазного протокола синхронизационных захватов действительно обеспечивается полная сериализация транзакций. Однако иногда приложению, которое выполняет транзакцию, не столько важны точные данные, сколько скорость выполнения запросов. Например, в системах поддержки принятия решений по электронным торгам важно просто иметь представление об общей картине торгов, на основании которого принимается решение об повышении или снижении ставок и т. д. Для смягчения требований сериализации транзакций вводится понятие уровня изолированности пользователя.
Уровни изолированности пользователей связаны с проблемами, которые возникают при параллельном выполнении транзакций и которые были рассмотрены нами ранее.
Всего введено 4 уровня изолированности пользователей. Самый высокий уровень изолированности соответствует протоколу сериализации транзакций, это уровень SERIALIZABLE. Этот уровень обеспечивает полную изоляцию транзакций и полную корректную обработку параллельных транзакций.
Следующий уровень изолированности называется уровнем подтвержденного чтения — REPEATABLE READ. На этом уровне транзакция не имеет доступа к промежуточным или окончательным результатам других транзакций, поэтому такие проблемы, как пропавшие обновления, промежуточные или несогласованные данные, возникнуть не могут. Однако во время выполнения своей транзакции вы можете увидеть строку, добавленную в БД другой транзакцией. Поэтому один и тот же запрос, выполненный в течение одной транзакции, может дать разные результаты, то есть проблема строк-призраков остается. Однако если такая проблема критична, лучше ее разрешать алгоритмически, изменяя алгоритм обработки, исключая повторное выполнение запроса в одной транзакции.
Второй уровень изолированности связан с подтвержденным чтением, он называется READ COMMITED. На этом уровне изолированности транзакция не имеет доступа к промежуточным результатам других транзакций, поэтому проблемы пропавших обновлений и промежуточных данных возникнуть не могут. Однако окончательные данные, полученные в ходе выполнения других транзакций, могут быть доступны нашей транзакции. При этом уровне изолированности транзакция не может обновлять строку, уже обновленную другой транзакцией. При попытке выполнить подобное обновление транзакция будет отменена автоматически, во избежание возникновения проблемы пропавшего обновления.
И наконец, самый низкий уровень изолированности называется уровнем неподтвержденного, или грязного, чтения. Он обозначается как READ UNCOMMITED. При этом уровне изолированности текущая транзакция видит промежуточные и несогласованные данные, и также ей доступны строки-призраки. Однако даже-при этом уровне изолированности СУБД предотвращает пропавшие обновления.
В разных коммерческих СУБД могут быть реализованы не все уровни изолированности, это необходимо выяснить в технической документации.
23. Файловые структуры, используемые для хранения информации в БД
Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне. Исторически первыми системами хранения и доступа были файловые структуры и системы управления файлами (СУФ), которые фактически являлись частью операционных систем. СУБД создавала над этими файловыми моделями свою надстройку, которая позволяла организовать всю совокупность файлов таким образом, чтобы она работала как единое целое и получала централизованное управление от СУБД. Однако непосредственный доступ осуществлялся на уровне файловых команд, которые СУБД использовала при манипулировании всеми файлами, составляющими хранимые данные одной или нескольких баз данных.
Однако механизмы буферизации и управления файловыми структурами не приспособлены для решения задач собственно СУБД, эти механизмы разрабатывались просто для традиционной обработки файлов, и с ростом объемов хранимых данных они стали неэффективными для использования СУБД. Тогда постепенно произошел переход от базовых файловых структур к непосредственному управлению размещением данных на внешних носителях самой СУБД. И пространство внешней памяти уже выходило из-под владения СУФ и управлялось непосредственно СУБД. При этом механизмы, применяемые в файловых системах, перешли во многом и в новые системы организации данных во внешней памяти, называемые чаще страничными системами хранения информации. Поэтому наш раздел, посвященный физическим моделям данных, мы начнем с обзора файлов и файловых структур, используемых для организации физических моделей, применяемых в базах данных, а в конце ознакомимся с механизмами организации данных во внешней памяти, использующими страничный принцип организации.
В каждой СУБД по-разному организованы хранение и доступ к данным, однако существуют некоторые файловые структуры, которые имеют общепринятые способы организации и широко применяются практически во всех СУБД.
В системах баз данных файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом (см. рис. 1).
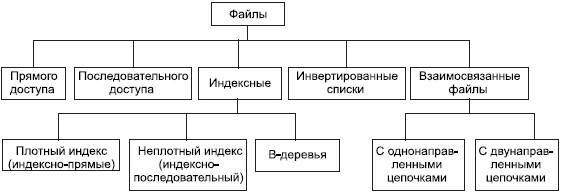 Рис. 1. Классификация файлов, используемых в системах баз данных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 2 представлена такая условная последовательность записей.
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. Не будем вдаваться в особенности физической организации внешней памяти, выделим в ней те черты, которые существенны для рассмотрения нашей темы.
В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с последовательной адресацией (магнитофоны, стримеры).
На устройствах с произвольной адресацией теоретически возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое весьма мало по сравнению со временем считывания-записи.
В устройствах с последовательным доступом для получения доступа к некоторому элементу требуется "перемотать (пройти)" все предшествующие ему элементы информации. На устройствах с последовательным доступом вся память рассматривается как линейная последовательность информационных элементов (см. рис. 3).
Рис. 1. Классификация файлов, используемых в системах баз данных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 2 представлена такая условная последовательность записей.
Так как файл — это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. Не будем вдаваться в особенности физической организации внешней памяти, выделим в ней те черты, которые существенны для рассмотрения нашей темы.
В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с последовательной адресацией (магнитофоны, стримеры).
На устройствах с произвольной адресацией теоретически возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое весьма мало по сравнению со временем считывания-записи.
В устройствах с последовательным доступом для получения доступа к некоторому элементу требуется "перемотать (пройти)" все предшествующие ему элементы информации. На устройствах с последовательным доступом вся память рассматривается как линейная последовательность информационных элементов (см. рис. 3).
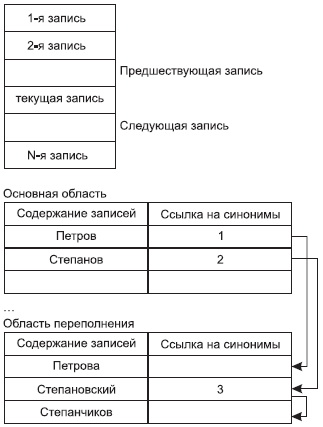 Рис. 2. Файл как линейная последовательность записей
Рис. 2. Файл как линейная последовательность записей
 Рис. 3. Модель хранения информации на устройстве последовательного доступа
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего неограниченное количество уровней иерархии в представлении внешней памяти (см. рис. 4).
Для каждого файла в системе хранится следующая информация:
Рис. 3. Модель хранения информации на устройстве последовательного доступа
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа.
В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Каждая файловая система СУФ — система управления файлами поддерживает некоторую иерархическую файловую структуру, включающую чаще всего неограниченное количество уровней иерархии в представлении внешней памяти (см. рис. 4).
Для каждого файла в системе хранится следующая информация:
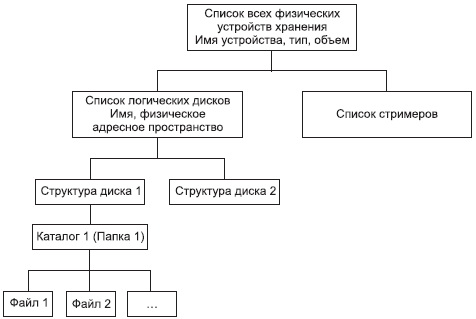 Рис. 4. Иерархическая организация файловой структуры хранения
Рис. 4. Иерархическая организация файловой структуры хранения
|
Для файлов с постоянной длиной записи адрес размещения записи с номером K может быть вычислен по формуле:
ВА + (К- 1) * LZ + 1,
где ВА — базовый адрес, LZ — длина записи.
И как мы уже говорили ранее, если можно всегда определить адрес, на который -необходимо позиционировать механизм считывания-записи, то устройства прямого доступа делают это практически мгновенно, поэтому для таких файлов чтение произвольной записи практически не зависит от ее номера. Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и их использование считается наиболее перспективным в системах баз данных.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
- Конец записи отличается специальным маркером.
| Запись 1 | X | Запись 2 | X | Запись3 | X |
- В начале каждой записи записывается ее длина.
| LZ1 | Запись1 | LZ2 | Запись2 | LZ3 | Запись3 |
3. Здесь LZN — длина N-й записи.
Файлы с прямым доступом обеспечивают наиболее быстрый способ доступа. Мы не всегда можем хранить информацию в виде файлов прямого доступа, но главное — это то, что доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ = F(K),
где NZ — номер записи, K — значение ключа, F( ) — функция.
Функция F() при этом должна быть линейной, чтобы обеспечивать однозначное соответствие (см. рис. 5).
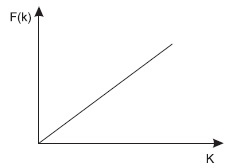
Рис. 5. Пример линейной функции пересчета значения ключа в номер записи
Однако далеко не всегда удается построить взаимно-однозначное соответствие между значениями ключа и номерами записей.
Часто бывает, что значения ключей разбросаны по нескольким диапазонам (см. рис. 6).
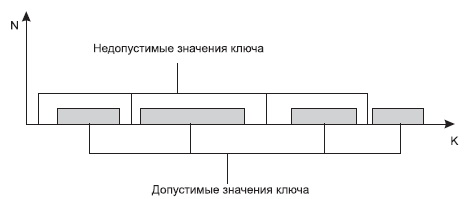
Рис. 6. Допустимые значения ключа
В этом случае не удается построить взаимно-однозначную функцию, либо эта функция будет иметь множество незадействованных значений, которые соответствуют недопустимым значениям ключа. В подобных случаях применяют различные методы хэширования (рандомизации) и создают специальные хэш- функции.
Суть методов хэширования состоит в том, что мы берем значения ключа ( или некоторые его характеристики) и используем его для начала поиска, то есть мы вычисляем некоторую хэш-функцию h(k) и полученное значение берем в качестве адреса начала поиска. То есть мы не требуем полного взаимно-однозначного соответствия, но, с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хэш-функции (то есть один адрес). Подобные ситуации называются коллизиями.Значения ключей, которые имеют одно и то же значение хэш-функции, называются синонимами.
Поэтому при использовании хэширования как метода доступа необходимо принять два независимых решения:
- выбрать хэш-функцию;
- выбрать метод разрешения коллизий.
Существует множество различных стратегий разрешения коллизий, но мы для примера рассмотрим две достаточно распространенные.
Дата добавления: 2016-06-24; просмотров: 930;