Машине и направления его развития
Параллельное выполнение во времени фазы выполнения очередной команды и фазы выборки следующей является важной особенностью МП семейства i8086/8088, позволяющей значительно повысить их быстродействие. Такое решение называется конвейерным методом (pipelining) выполнения команд и иллюстрируется примером, приведенным на рис.4.3, где ТI обозначает холостые такты работы шины, когда очередь команд заполнена, а операционное устройство занято выполнением текущей команды и не запрашивает выполнения цикла шины /2,5,9/.
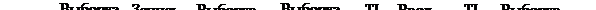
Рассмотренный пример иллюстрирует работу простейшего 2 - ступенного конвейера, реализованного в МП семейства i8086/8088.
Дальнейшее развитие конвейерного метода выполнения команд идет по пути увеличения числа ступеней командного конвейера /2,10,11/. Учитывая, что число ступеней типового командного цикла равно 5, были разработаны процессоры с 5 – ступенным конвейером, в котором в каждый момент времени одновременно выполняются 5 ступеней командного цикла 5 следующих друг за другом различных команд. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую ступень, выполненная команда покидает конвейер, а новая входит в него. Принцип работы 5 – ступенного командного конвейера поясняется рис.4.4. Хотя командам по-прежнему необходимо 5 тактов для прохождения от начала конвейера до его конца, процессор в идеальных условиях в каждом такте может заканчивать выполнение одной команды.
В современных процессорах 5 основных ступеней командного конвейера делятся на части, чтобы уменьшить сложность и время работы каждой ступени. Это позволяет увеличить тактовую частоту и, следовательно, производительность процессора. Такая организация вычислений называется суперконвейерной (superpipelining) /2,10,11/. Например, 20-28 – ступенный конвейер выполнения целочисленных команд имеет процессоры Pentium.
Конвейерное выполнение команд эффективно только на линейных участках программы, когда адрес следующей команды известен до завершения предыдущей.
1-рез. 2-рез. 3-рез.
Ступени конвейера
| Запись результата | |||||||
| Исполнение команды | |||||||
| Чтение операнда | |||||||
| Декодирование кода команды | |||||||
| Выборка кода команды |
 |
При наличии ветвлений, условных переходов, когда адрес следующей команды становится известным лишь по завершении выполнения текущей команды, эффективность конвейера резко падает. Чтобы избежать этого в процессор вводят блоки предсказания переходов (branch prediction) /2/, которые позволяют продолжать выборку и декодирование потока инструкций (команд) после выборки инструкции ветвления (условного перехода), не дожидаясь проверки самого условия. Предсказание переходов направляет поток выборки и декодирования по одной из ветвей.
Статистический метод предсказания работает по схеме, заложенной в процессор, считая, что переходы по одним условиям, вероятнее всего произойдут, а по другим – нет.
Динамическое предсказание опирается на предысторию вычислительного процесса – для каждого конкретного случая перехода в таблице ветвлений накапливается статистика поведения системы, и переход предсказывается, основываясь именно на ней.
Дальнейшим развитием метода предсказаний является исполнение инструкций по предположению (спекулятивное исполнение – speculative execution. В этом методе предсказанные после перехода инструкции (команды) не только декодируются, но и по возможности исполняются до проверки условия перехода. Если предсказание сбывается, вычисления оказываются ненапрасными и результаты используются в последующих фрагментах программы. Если предсказание не сбывается – конвейер сбрасывается и затем выполняет поток инструкций той ветви вычислительного процесса, для которой выполнены условия перехода /2,10,11/. На заполнение всех ступеней конвейера затрачивается определенное число тактов, например, 5 тактов, как показано на диаграмме работы конвейера на рис.4.4. В течение тактов заполнения результаты выполнения инструкций на выходе конвейера не выдаются (конвейер простаивает). Естественно, что такие ситуации снижают быстродействие и производительность конвейерных процессоров.
С другой стороны, статистические исследования показывают, что команды переходов сравнительно редкие, и встречаются в среднем через шесть - восемь команд i80*86.
Хотя, с одной стороны, увеличение числа ступеней конвейера повышает быстродействие микропроцессора, с другой стороны, время заполнения конвейера при его сбросе при неверно предсказанном условном переходе, также возрастает, что негативно сказывается на быстродействии процессора. Кроме того, с увеличением числа ступеней конвейера увеличивается совокупное время передач данных между ступенями конвейера, что также снижает быстродействие конвейерного процессора. Поэтому для определенного уровня быстродействия элементной базы построения микропроцессоров существует оптимальная длина конвейера.
Процессор с единственным конвейером называют скалярным. Дальнейшее увеличение быстродействия можно получить организуя в процессоре несколько конвейеров. Такие процессоры называются суперскалярными (superscalar) , и они позволяют за один такт выполнять более одной команды, как показано на рис.4.5.
Cтупени двух конвейеров Результаты 1 2 3 4 5
| Запись результата | ||||||||||||||
| Исполнение команды | ||||||||||||||
| Чтение операнда | ||||||||||||||
| Декодирование кода команды | ||||||||||||||
| Выборка кода команды | 1 2 | 3 4 | 5 6 | 7 8 | 9 10 | 11 12 | 13 14 |
 |
Например, современные процессоры фирм Intel и AMD имеют три-четыре конвейера. Хотя быстродействие и производительность суперскалярных процессоров увеличивается, но не в число раз, равное количеству конвейеров. Действительно, далеко не все команды могут обрабатываться одновременно из-за зависимости по данным, например, когда последующая команда должна использовать результат предыдущей. В процессорах типа Pentium используется упорядоченное поступление и обработка и упорядоченное завершение команд. Команды должны покидать конвейеры точно в том же порядке, в каком поступали на конвейеры. Поэтому, если в одном конвейере происходит задержка из-за команды переходов, это останавливает и другой конвейер. Это усложняет взаимную синхронизацию конвейеров и снижает быстродействие процессора.
Поэтому в состав суперскалярных (иногда называют мультискалярных) процессоров для обеспечения параллельной работы нескольких конвейеров вводят специальные программно–аппаратные средства, реализующие исполнение с изменением последовательности инструкций (out–of–order execution). При этом внутри процессора допускается изменять порядок выполнения инструкций, но внешние (шинные) операции ввода–вывода и записи в память выполняются, конечно же, в порядке, предписанным программным кодом. Цель изменения последовательности исполняемых инструкций внутри процессора – получить в последовательной программе группы инструкций (команд), которые могут выполняться параллельно во времени на разных конвейерах. Этот архитектурный подход увеличения производительности процессоров, называемый также динамическим исполнением команд /2,10,11/ применяется при организации вычислительных процессов в современных процессорах, например, процессорах фирмы Intel.
Конвейерный метод выполнения команд позволяет значительно увеличить быстродействие и производительность процессоров за счет распараллеливания вычислительных процессов. С другой стороны, организация параллельных вычислительных процессов резко увеличивает сложность процессоров, а следовательно трудоемкость изготовления и стоимость.
Для уменьшения сложности процессоров и обеспечения загрузки конвейеров разрабатывают такие компиляторы, генерация программного кода которыми производится с учетом возможности изменения порядка последовательности исполнения инструкций в процессорах /16/.
Дальнейшим развитием суперконвейерной и суперскалярной архитектуры являются многопоточная, многоядерная и мультипроцессорная архитектуры вычислительных систем /2,3,6,9/.
Дата добавления: 2016-06-13; просмотров: 843;