Типы параллельных вычислительных систем
Обычно компьютеры выполняют операции последовательно. Программа принимает один поток данных и выполняет один поток инструкций по обработке этих данных. Такие системы называю SISD (Single Instruction Single Data). Инструкции в них выполняются последовательно и каждая инструкция оперирует минимальным количеством данных.
Повышение производительности компьютеров может быть повышено за счет параллельного выполнения операций над параллельным потоком данных.
Параллельные вычислительные системы — это аппаратные компьютерные, а также программные системы, реализующие тем или иным способом параллельную обработку данных на многих вычислительных узлах. Идея распараллеливания вычислений основана на том, что большинство задач может быть разделено на набор меньших задач, которые могут быть решены одновременно. Обычно параллельные вычисления требуют координации действий. Параллельные вычисления существуют в нескольких формах: на уровне битов, на уровне инструкций, параллелизм данных и параллелизм задач.
1) Параллелизм на уровне битов.
Эта форма параллелизма базируется на увеличении размера машинного слова. Увеличение размера машинного слова уменьшает количество операций, необходимых процессору для выполнения действий над переменными, чей размер превышает размер машинного слова. К примеру: на 8-битном процессоре нужно сложить два 16-битных целых числа. Для этого вначале нужно сложить младшие 8 бит чисел, затем сложить старшие 8 бит и к результату их сложения прибавить значение флага переноса. Итого 3 инструкции. С 16-битным процессором можно выполнить эту операцию одной инструкцией.
Исторически 4-битные микропроцессоры были заменены 8-битными, затем появились 16-битные и 32-битные. 32-битные процессоры долгое время были стандартом в повседневных вычислениях. С появлением технологии x86-64 для этих целей стали использовать 64-битные процессоры.
2) Параллелизм на уровне инструкций
Компьютерная программа — это, по существу, поток инструкций, выполняемых процессором. Но можно изменить порядок этих инструкций, распределить их по группам, которые будут выполняться параллельно, без изменения результата работы всей программы. Данный приём известен как параллелизм на уровне инструкций. Продвижения в развитии параллелизма на уровне инструкций в архитектуре компьютеров происходили с середины 1980-х до середины 1990-х.
Классический пример пятиступенчатого конвейера на RISC-машине (IF = выборка инструкции, ID = декодирование инструкции, EX = выполнение инструкции, MEM = доступ к памяти, WB = запись результата в регистры).
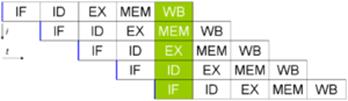
Современные процессоры имеют многоступенчатый конвейер команд. Каждой ступени конвейера соответствует определённое действие, выполняемое процессором в этой инструкции на этом этапе. Процессор с N ступенями конвейера может иметь одновременно до N различных инструкций на разном уровне законченности. Классический пример процессора с конвейером — это RISC-процессор с 5-ю ступенями: выборка инструкции из памяти (IF), декодирование инструкции (ID), выполнение инструкции (EX), доступ к памяти (MEM), запись результата в регистры (WB). Процессор Pentium 4 имеет 35-тиступенчатый конвейер.[5]
Пятиступенчатый конвейер суперскалярного процессора, способный выполнять две инструкции за цикл. Может иметь по две инструкции на каждой ступени конвейера, максимум 10 инструкций могут выполняться одновременно.

Некоторые процессоры, дополнительно к использованию конвейеров, обладают возможностью выполнять несколько инструкций одновременно, что даёт дополнительный параллелизм на уровне инструкций. Возможна реализация данного метода при помощи суперскалярности, когда инструкции могут быть сгруппированы вместе для параллельного выполнения (если в них нет зависимости между данными). Также возможны реализации с использованием явного параллелизма на уровне инструкций: VLIW и EPIC.
3) Параллелизм данных.
Основная идея подхода, основанного на параллелизме данных, заключается в том, что одна операция выполняется сразу над всеми элементами массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины. Распределением данных между процессорами занимается программа. Векторизация или распараллеливание в этом случае чаще всего выполняется уже на этапе компиляции — перевода исходного текста программы в машинные команды. Роль программиста в этом случае обычно сводится к заданию настроек векторной или параллельной оптимизации компилятору, директив параллельной компиляции, использованию специализированных языков для параллельных вычислений.
4) Параллелизм задач.
Стиль программирования, основанный на параллелизме задач, подразумевает, что вычислительная задача разбивается на несколько относительно самостоятельных подзадач и каждый процессор загружается своей собственной подзадачей.
Распределённые операционные системы.
Распределённая ОС, динамически и автоматически распределяя работы по различным машинам системы для обработки, заставляет набор сетевых машин обрабатывать информацию параллельно. Пользователь распределённой ОС, вообще говоря, не имеет сведений о том, на какой машине выполняется его работа.
Распределённая ОС существует как единая операционная система в масштабах вычислительной системы. Каждый компьютер сети, работающей под управлением распределённой ОС, выполняет часть функций этой глобальной ОС. Распределённая ОС объединяет все компьютеры сети в том смысле, что они работают в тесной кооперации друг с другом для эффективного использования всех ресурсов компьютерной сети.
Наиболее широко применяется классификация вычислительных систем, основанная на количестве потоков входных данных и количестве потоков команд, которые эти данные обрабатывают (рисунок 7.1):
- Один поток инструкций-несколько потоков данных SIMD;
- Несколько потоков инструкций-один поток данных MISD;
Несколько потоков инструкций-несколько потоков данных MIMD.
MISD (Multiple Instruction Single Data): разные потоки инструкций выполняются с одними и теми же данными. Обычно такие системы не приводят к ускорению вычислений, так как разные инструкции оперируют одними и теми же данными, в результате на выходе системы получается один поток данных. К таким системам относят различные системы дублирования и защиты от сбоев, когда, например, несколько процессоров дублируют вычисления друг друга для надёжности. Иногда к этой категории относят конвейерные архитектуры. Среди процессоров производства Intel, конвейер присутствует начиная с процессора Pentium.

|
| Рисунок 7.1 – Классификация вычислительных систем |
SIMD (Single Instruction Multiple Data): один поток инструкций выполняет вычисления одновременно с разными данными. Например, выполняется сложение одновременно восьми пар чисел. Такие компьютеры называются векторными, так как подобные операции выполняются аналогично операциям с векторами (когда, например, сложение двух векторов означает одновременное сложение всех их компонентов). Зачастую векторные инструкции присутствуют в дополнение к обычным «скалярным» инструкциям, и называются SIMD-расширением (или векторным расширением). Примеры популярных SIMD-расширений: MMX, 3DNow!, SSE и др.
MIMD (Multiple Instruction Multiple Data): разные потоки инструкций оперируют различными данными. Это системы наиболее общего вида, поэтому их проще всего использовать для решения различных параллельных задач.
MIMD-системы, в свою очередь, принято разделять на системы с общей памятью (несколько вычислителей имеют общую память) и системы с распределенной памятью (каждый вычислитель имеет свою память; вычислители могут обмениваться данными). Кроме того, существуют системы с неоднородным доступом к памяти (NUMA) — в которых доступ к памяти других вычислителей существует, но он значительно медленнее, чем доступ к «своей» памяти.
Дата добавления: 2016-02-09; просмотров: 2611;