Архитектура систем оперативного анализа данных
Современные системы поддержки принятия решений и информационные системы руководителей основаны на применении специализированных информационных хранилищ (ИХ) и технологий оперативного анализа данных (ОLАР)
ИХ представляет собой базу обобщенной информации, формируемую из множества внешних и внутренних источников, на основе которой выполняются статистические группировки и интеллектуальный анализ данных. По сравнению с базами данных для оперативной обработки транзакций (транзакционных БД) ИХ обеспечивают более гибкое и простое формирование произвольных справочно-аналитических запросов, а также применение специализированных методов статистического и интеллектуального анализа данных.
В основе информационного хранилища лежит понятие многомерного информационного пространства или гиперкуба (рис. 12.7), в ячейках которого хранятся анализируемые числовые показатели (например, объемы оборота, издержек, инвестиций и т.д.). Измерениями (осями) гиперкуба являются признаки анализа (например, время, группа продукции, регион, тип процесса, тип клиента и др.). При хранении признаки анализа отделяются от фактических данных, образуя так называемую инвертированную организацию хранения данных или структуру данных типа «звезда».
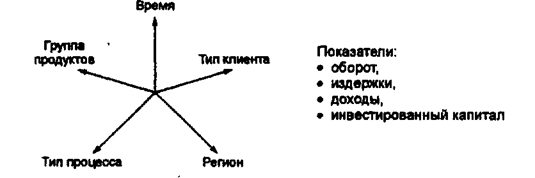
Рис. 2.1. Многомерная организация информационного хранилища
К особенностям хранимой информации в ИХ относятся:
• интеграция или обобщение данных в ИХ из транзакционных баз данных по всем бизнес-процессам и структурным подраз делениям предприятия в виде единого многомерного информационного пространства. Например, организуется хранение показателей объемов производства, сбыта, сервиса и т.д. в продуктовом, территориальном, отраслевом, временном и других разрезах;
• произвольность агрегации данных на основе отделения от фактических данных независимых и равноправных измерений информационного пространства (признаков анализа информации, разрезов) в виде иерархий агрегации. Например, региональный признак анализа представляется в виде иерархии агрегации: «область - район - город -'село», временной признак «год - квартал - месяц -день» и т.д.;
• обязательное хранение временного признака в данных1, дающего возможность отслеживать динамику изменения показателей в течение длительного периода времени;
• непротиворечивость данных во всех используемых источниках в течение определенного периода времени (например, дня), которая позволяет обеспечить единую точку зрения всех пользователей на экономическую систему;
• обеспечение множества представлений структуры информационного хранилища для различных категорий пользователей: руководителей, аналитиков, менеджеров направлений деятельности. Отбор набора показателей и признаков анализа определяет предметную ориентированность информационного хранилища или организацию витрин данных.
С технологической точки зрения к архитектуре ИХ предъявляются общие требования:
• Единообразно определенная структура многомерных данных с равноправными измерениями информационного пространства.
• Пользователь не должен знать о том, где хранятся данные, как они организованы и как обрабатываются.
• Поддержка многопользовательского режима оперативного анализа в среде «клиент-сервер».
• Легкая адаптация к новым информационным потребностям путем добавления новых показателей и измерений.
• Автоматическое обновление информации из оперативных баз данных.
• Выполнение запросов без ограничений на количество измерений и уровней их агрегации примерно с одинаковым временем реакции на запрос.
• Удобный, «интуитивный» интерфейс пользователя, обеспечивающий простоту манипулирования данными.
Архитектура системы оперативного анализа данных представлена на рис. 2.
Рассмотрим состав основных подсистем информационного хранилища.
1) Подсистема хранения данных
Многомерное хранилище данных может быть организовано в виде одной из следующих структур:
• физической структуры, называемой МОLАР (Multidimensional ОLАР), в которую с определенной периодичностью загружаются данные из файлов источников, принадлежащих базам оперативных данных (например, один раз в день). Типичным инструментальным средством, поддерживающим МОLАР, являются Огас1е Ехргеss (Огас1е), Роwег Р1ау (Соgnos Согр), DataDirect (Intersolv);
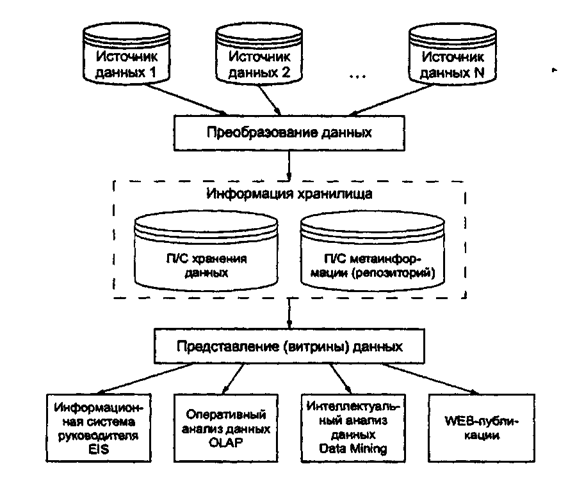
Рис. 2. Архитектура информационного хранилища
• виртуальной структуры, называемой RОLАР (Rе1аtional ОLАР), которая динамически используется при запросах, вызывающих физическое манипулирование с файлами-источниками из реляционных баз оперативных данных (формирование ответа на запрос к ИХ «на лету»). RОLАР-система рассматривается просто как надстройка над реляционными базами данных, обеспечивающая удобный интерфейс пользователя. Типичными инструментальными средствами, поддерживающими RОLАР, являются МеtaCube (Informix), Business-Objects
и др.;
• гибридной структуры, называемой НОLАР (Нybrid ОLАР), которая используется при построении многоуровневых информационных хранилищ, применяемых на разных уровнях управления больших корпораций. Типичным инструментальным средством, поддерживающим НОLАР, является SAS System (SAS Institute).
Анализ параметров использования МОLАР и RОLАР информационных хранилищ показывает, что внедрение и эксплуатация RОLАР-систем являются более простыми и дешевыми по сравнению с МОlАР-системами, но уступают последним в эффективности оперативного анализа данных.
2) Подсистема метаннформации (репознторий)
Репозиторий представляет собой описание структуры информационного хранилища: состава показателей, иерархий агрегации измерений, форматов данных, используемых функций, физического размещения на сервере, прав доступа пользователей, частоты обновления.
Важнейшей функцией репозитория является представление схем отображения структуры данных файлов-источников на структуре данных ИХ, в соответствии с которой осуществляется периодическая загрузка МОLAP-хранилища или непосредственная реализация запросов «на лету» в MОLАР-хранилищах.
В репозитории задается также схема отображения структуры ИХ на схемах представлений данных пользователей или витринах данных. Через репозитории осуществляется интерпретация запросов к ИХ на проведение оперативного анализа данных.
Отображение данных между источниками данных и ИХ, ИХ и представлением данных осуществляется либо через механизм межуровневого взаимодействия, либо через процедуры преобразования данных.
3) Подсистема преобразования данных (загрузки хранилища)
Подсистема загрузки ИХ создается только для МОLАР-систем. Для RОLАР-систем в процессе выполнения запросов осуществляется преобразование данных из файлов-источников. В том и другом случае требуется выполнение следующих основных функций:
• сбор данных (Data Acquisition);
• очистка данных (Data Cleaning);
• агрегирование данных (Data Concolidation).
Сбор данных предполагает передачу данных из источников в ИХ в соответствии со схемой отображения, представленной в репозитории.
В процессе очистки данных осуществляются проверка непротиворечивости (целостности), исключение дублирования данных, отбраковка шумовых (случайных) данных, восстановление отсутствующих данных, приведение данных к единому формату.
В случае необходимости агрегирования данных осуществляется суммирование итогов по заданным в репозитории признакам агрегации.
4) Подсистема представления данных (организации витрин данных)
Под витриной данных (Data Mart) понимается предметно-ориентированное хранилище, как правило, агрегированной информации, предназначенное для использования группой пользователей обычно из 10 - 15 человек в рамках конкретного вида деятельности предприятия, например маркетинга, инжиниринга, финансового менеджмента и т.д.
Как правило, витрины данных являются подмножествами общего хранилища компании, которое служит для них источником. В принципе витрины данных Ъюгуг создаваться независимо друг от друга и общего хранилища, однако в этом случае возникает проблема согласования множества представлений данных. Обычно общее информационное хранилище и витрины данных разрабатываются параллельно.
5) Подсистема оперативного анализа данных
Подсистема оперативного анализа, как правило, используется лицами, подготавливающими информацию для принятия решений, путем выполнения различных статистических группировок исходных данных.
В рамках пользовательского интерфейса для оперативного анализа данных используются следующие базовые операции.
· Поворот. Добавление нового признака анализа.
· Проекция. Выборка подмножества по задаваемой совокупности измерений. При этом значения в ячейках, лежащих на осипроекции, суммируются.
· Раскрытие (drill-down). Осуществляется декомпозиция признака агрегации на компоненты, например, признак года разбивается на кварталы. При этом автоматически детализируются числовые показатели.
· Свертка (го11-uр/drill-uр). Операция, обратная раскрытию. При этом значения детальных показателей суммируются в агрегируемый показатель.
· Сечение (slicе-and-dicе). Выделение подмножества данных по конкретным значениям одного или нескольких измерений.
6) Подсистема интеллектуального анализа данных (извлечения знаний)
Подсистема интеллектуального анализа данных используется специальной категорией пользователей-аналитиков, которые на основе ИХ обнаруживают закономерности в деятельности предприятия и на рынке, используемые в дальнейшем для обоснования стратегических или тактических решений. Интеллектуальный анализ требует применения более сложных методов анализа по сравнению со статистическими группировками и выполняется путем проведения множества сеансов.
Типичными задачами интеллектуального анализа данных являются:
• установление корреляций, причинно-следственных связей и временных связей событий, например определение местоположения прибыльных предприятий;
• классификация ситуаций, позволяющая обобщать конкретные события в классы, например определение типичного профиля покупателя конкретных видов продукции;
• прогнозирование развития ситуаций, например прогнозирование цен, объемов продаж, производства.
К основным методам интеллектуального анализа данных относятся:
• методы многомерного статистического анализа;
• индуктивные методы построения деревьев решений;
• нейронные сети.
7) Подсистема «Информационная система руководителя»
Информационная система руководителя предназначена для лиц, непосредственно принимающих решения. Поэтому интерфейс таких систем должен быть в наибольшей степени упрощенным. Обычно в качестве интерфейса руководителям предприятий предлагается набор стандартных отчетов и графиков, настраиваемых на потребности руководителя через систему меню. Часто в качестве интерфейса предлагаются диаграммы Ишикава («скелета рыбы»), представляющие собой саморазворачивающееся дерево показателей, в котором листья ветвей раскрашиваются в разные цвета, символизирующие характер состояния показателя (нормальный, тревожный, кризисный). Лист любой ветви дерева показателей может быть развернут в таблицу значений показателя или графив. Подобные диаграммы применяются в таких корпоративных ЭИС, как R/3 и ВААN IV.
8) Подсистема WEB-публикации
Подсистема WEB-публикации предполагает преобразование полученной из ИХ информации в НТМL-вид, доступный для ее просмотра удаленными клиентами с помощью широко распространенных броузеров Интернета.
2.2 Технология проектирования ИХ
Интеграция множества источников данных в рамках единого информационного хранилища представляет собой трудоемкую и дорогостоящую проектную задачу. Поэтому к процессу проектирования систем оперативного анализа данных на основе информационного хранилища в наибольшей степени относятся требования: очередности внедрения компонентов ИХ, обеспечивающей быструю отдачу от внедрения, и адаптивности логической и физической структуры ИХ к изменяющимся в ходе проектирования и эксплуатации информационным потребностям. Рассмотрим технологическую сеть проектирования информационного хранилища (рис. 3).
П1. Идентификация проблемной области
На основе материалов предпроектного обследования (Д1) осуществляется параметризация проекта создания информационного хранилища и выделяются все необходимые материальные, финансовые, людские и временные ресурсы на выполнение проектных работ, т.е. составляются техническое задание (Д2) и технико-экономическое обоснование проекта (ДЗ). В частности, в рамках технического задания в разрезе конкретных видов деятельности или бизнес-процессов формулируются цели и задачи, области применения и пользователи ИХ, устанавливаются источники исходных данных, определяются информационные потребности пользователей.
Цели и задач». Цели построения информационного хранилища во многом определяют характер используемых источников данных, направлений и методов анализа извлекаемой информации. В качестве целей создания ИХ могут выступать:
• реинжиниринг и непрерывный инжиниринг процессов и структуры управления предприятием;
• повышение качества и оперативности обоснования управленческих решений на стратегическом, тактическом и оперативном уровнях;
• упрощение управленческого документооборота для процесса принятия управлеческих решений и др.
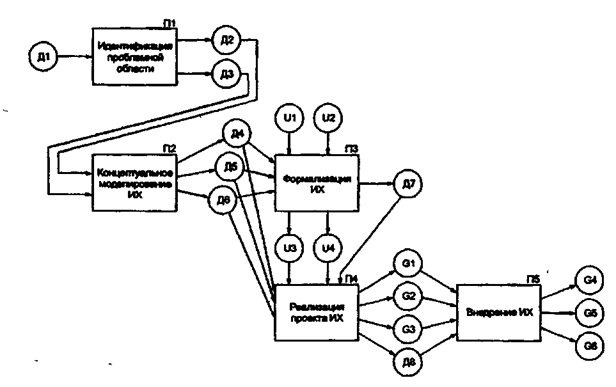
Рис. 3. Технологическая сеть проектирования информационного хранилища:
Д1 - материалы предпроектного обследования; Д2 - техническое задание; ДЗ - технико-экономическое обоснование проекта;
Д4 - логическая структура данных ИХ; Д5- схема преобразования данных; Д6 - логическая структура данных витрин; Д7 - схема размещения ИХ в сетевой вычислительной среде; Д8 - проектная документация; U1 - универсум программных средств; U2 - универсум технических средств; U3 - универсум программных средств реализации ИХ; U4 - универсум технических средств реализации ИХ; G1 - репознторий; G2 - настройка или процедуры инструментальных средств; GЗ – наполнение информационного хранилища для МОLАР-структуры; G4 - модифицированный репозиторий; G5 - модифицированные настройки или процедуры инструментальных средств; G6 - модифицированное информационное хранилище для МОLАР-структуры
К важнейшим задачам, которые решаются с помощью ИХ, относятся:
· бизнес-планирование-обоснование принятия стратегических '' решений;
· контроллинг - анализ финансово-хозяйственной деятельности и выявление резервов совершенствования бизнес-процессов предприятия;
· оперативный мониторинг и сравнительный анализ (bench-marking) важнейших показателей деятельности предприятия.
Круг пользователей: руководители; референты руководителей, подготавливающие информацию для принятия решений; менеджеры функциональных подразделений; аналитики.
Области применения: анализ и прогнозирование осуществления основных бизнес-процессов в разрезах типов клиентов, продуктов, используемых технологий, каналов распределения, направлений функциональной деятельности (продаж, производства, закупок, финансов, персонала) и др.
Перечень источников данных:
• внутренние источники: базы оперативных данных об объемах продаж, производства, закупок, издержках по центрам затрат, состоянии материальных, финансовых, людских ресурсов;
• внешние источники: официальные статистические данные о деятельности отрасли, смежных отраслях, состоянии финансов; нормативная государственная информация; маркетинговая информация о зондировании рынка, состоянии конкурентов; коммерческие базы данных специализированныхкомпаний в области информационного бизнеса, например Reuters.
Для каждого источника данных определяются параметры: территориальное расположение, административное подчинение, периодичность обновления, конфиденциальность и достоверность хранимой информации, форматы данных и характеристики программно-технической среды, объемы данных.
Информационные потребности пользователей. Для обоснования информационных потребностей выполняется анализ функций работников в рамках конкретных видов деятельности (бизнес-процессов), например бизнес-планирования, бюджетирования, маркетинга и т.д. В результате выявляется перечень регламентированных информационно-справочных документов и предполагаемых направлений формирования произвольных запросов.
П2. Разработка концептуальной модели ИХ
Этап разработки концептуальной модели ИХ соответствует этапу логического проектирования, который выполняется на основе технического задания Д2 и технико-экономического обоснования ДЗ. На выходе этого этапа получаются логическая структура данных ИХ Д4, схема преобразования данных Д5, логическая структура данных витрин Д6 и схема представления данных Д7.
Проектирование логической структуры ИХ осуществляется на основе анализа статистики использования конкретных информационно-справочных документов в процессе решения основных задач принятия решений. В результате выполнения операции производятся:
· отбор признаков анализа;
· построение схем агрегации показателей;
· построение схем обобщения признаков;
· определение временного горизонта хранения показателей;
· отбор первичных и производных показателей для хранения;
· выбор типа логической структуры ИХ;
· распределение показателей по типам логической структуры.
Основными методами выполнения операции отбора и структуризации показателей и признаков являются матричные, графо-аналитические и тезаурусные методы, описанные в п. 4,1. В частности, большое значение имеет формирование объемно-частотных характеристик использования типов показателей и признаков их группировки в различных типах информационно-справочных запросов. На этой операции происходит также обобщение непосредственно сформулированных пользователями типов запросов к ИХ.
Сложность структуры данных показателей предопределяет выбор ее типа: «звезды» с однородной структурой признаков для всех показателей или «расширенной снежинки» с применением нескольких типов хранилищ показателей. В последнем случае осуществляется распределение показателей по типам хранилищ.
Проектирование процессов извлечения и схемы преобразования данных производится путем анализа выявленных на этапе идентификации проблемной области источников данных. На выходе операции формируется уточненный состав источников данных с определенными схемами фильтрации и агрегации данных для помещения в ИХ.
В частности, на этом этапе осуществляется анализ альтернативных источников данных, например выбор из числа коммерческих баз данных, а также устанавливаются схемы преобразований исходных данных в хранимые структуры ИХ. Сложность схем отображения источников данных в структуру хранилища предопределяет выбор типа ИХ: МОLАР, RОLАР, НОLАР.
Проектирование логической структуры витрин и схемы представления данных предполагает распределение показателей вместе с измерениями по витринам данных на основе выявленных информационных потребностей пользователей. Для витрин данных точно так же, как и для информационных хранилищ, проектируется структура данных и устанавливается схема отображения структуры ИХ на структуры витрин.
Данная операция может предшествовать разработке структуры информационного хранилища, когда сначала создаются структуры витрин данных, например, по основным видам деятельности или структурным подразделениям, а затем эти структуры данных интегрируются в общую структуру ИХ.
В рамках логически спроектированных витрин данных осуществляется выбор методов анализа данных для конкретных категорий пользователей. В частности, выявляется потребность в применении определенных видов статистического и интеллектуального анализа данных.
П3. Формализация ИХ
Этап формализации завершает техническое проектирование информационного хранилища. На основе спроектированной на предшествующей операции архитектуры ИХ (Д4 – Д6) и универсумов программно-технических средств (U1-U2) осуществляется выбор схемы размещения ИХ в сетевой вычислительной среде (Д7) и программно-технических средств реализации ИХ (U3-U4).
Выбор схемы размещения ИХ в сетевой вычислительной среде осуществляется в зависимости от выбранного типа организации и предполагает определение числа уровней хранения:
• структура данных реализована централизованно на одном МОLАР-сервере;
• структура данных распределена на нескольких серверах в соответствии с
ROLАР-организацией;
• наиболее оперативные и агрегированные данные хранятся на быстродействующем МОLАР-сервере, а детальные данные в RОLАР-хранилище - на менее производительных серверах.
Определение требований к конфигурации и числа клиентских мест выполняется на основе структуры витрин данных, выявленных категорий пользователей и используемых методов интеллектуального анализа, которые в совокупности определяют требования подключения к ОLАР-серверу. Для каждого пользователя устанавливаются права доступа к ИХ.
Выбор программно-технических средств ИХ (серверов, клиентских мест, телекоммуникационного оборудования, инструментальных программных средств) выполняется на основе требований к физической конфигурации системы в части объемов памяти, быстродействия, надежности и выбранной клиент-серверной архитектуры ИХ.
Расчет объемов ИХ осуществляется путем суммирования объемов хранимых данных на всех МОLАР-серверах с учетом необходимого индексирования (специальных, индексирующих таблиц для доступа к основным данным), а также объемов метаинформации репозитория для МОLАР и RОLАР-организации. Объемы ИХ рассчитываются на текущий момент времени и на перспективу с учетом внедрения всех компонентов системы.
П4. Реализация проекта ИХ
Этап реализации проекта ИХ выполняется на основе выбранных программных (U3) и технических средств (U4), а также построенных на этапе концептуального моделирования компонентов ИХ (Д4 – Д6) и схемы размещения ИХ (Д7) путем наполнения репозитория (G1), настройки или программирования других инструментальных средств (G2), наполнения информационного хранилища для МОLАР- структуры (GЗ), создания проектной документации (Д8).
Наполнение репозитория ИХ осуществляется путем ввода определений:
· структуры ИХ, источников и витрин данных;
· правил ввода данных в ИХ из одного источника, из нескольких источников, при отсутствии данных;
· правил преобразования форматов при поступлении данных из источника и при выводе данных в предоставление пользователю;
· параметров использования методов интеллектуального анализа данных.
Разработка и отладка программных компонентов производятся в основном путем параметрической настройки ППП. В случае функциональной неполноты выбранного инструментального программного средства в части процедур начальной и периодической загрузки данных, а также процедур анализа данных выполняется программирование отдельных программных модулей.
Наполнение ИХ предполагает автоматическую загрузку информации из источников данных в ИХ с МОLАР-организацией, которая повторяется с заданной в репозитории периодичностью. Эта операция в последующем предполагает очистку ИХ от ненужных и устаревших данных; управление данными на различных уровнях хранения; автоматическое обновление агрегированных данных.
П5. Внедрение и опытная эксплуатация
Заключительный этап создания ИХ предполагает комплексное тестирование всех компонентов ИХ (G1 - GЗ) с исправлением всех возникающих ошибок (G4 – G6), последующим обучением пользователей и постоянным администрированием в соответствии с установленными правилами и документацией проекта (Д8).
| <== предыдущая лекция | | | следующая лекция ==> |
| Структура услуг и приложений | | |
Дата добавления: 2016-02-04; просмотров: 1643;