РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ
Данные могут храниться в регистрах процессора, в области статической памяти, в области организованной как стек и в динамической памяти.
Статическая память - данные размещаются в ней после компиляции и хранятся до конца. В стеке - временно.
Размещением данных управляет программист. Адрес любого участка памяти состоит из смещения и сегмента. Это 16-ти разрядные числа.
Полный адрес получается : сегмент * 16 + смещение.
Существует 4 специальных регистра для хранения адресов сегмента CS, DS, SS, ES. Для оптимизации управления памятью имеется 6 моделей памяти.
Динамическая память "куча" используется в зависимости от выбранной модели памяти. Различают "ближнюю кучу" - неиспользованную часть сегмента стека и "дальнюю кучу" - оставшаяся свободная память машины. В начале блока выделяемой памяти записывается его размер. Он затем используется при удалении.
МОДЕЛИ ПАМЯТИ
C++ поддерживает 6 моделей памяти: tiny, small, medium, compact, large, huge. Для каждой модели различается количество сегментов отведенных под код программы и данных. Рассмотрим эти модели.
1. Крошечная модель tiny
CS,DS,SS

SP
2. Малая модель small
 CS
CS
DS,SS
SP
3. Средняя модель medium

CS
DS,SS
SP
4. Компактная модель Compact
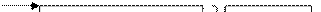 CS
CS
DS
SS
SP
5.Большая модель large
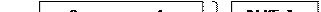
CS
DS
SS
SP
6. Гигантская модель huge

CS
DS
SS
SP
Организация процессора I8086 накладывает ограничения на размер статистической памяти программы - размер кодов функций и размер статических данных. Размер данных не более 64 Кб в одном сегменте, т.к. размер адресуемой памяти ПЭВМ равен 1 Мб.
Существует 2 варианта построения программы:
А) весь исходный текст компилируется сразу;
Б) программа собирается из нескольких фрагментов (модулей), которые компилируются отдельно. В любом таком модуле свои сегмент данных и сегмент кода. Объединение сегментов может происходить по-разному – в зависимости от используемого метода настройки сегментных регистров CS и DS. Может быть так, что независимо от количества модулей настройка CS,DS выполняется только однажды - тогда размер кода < 64 Кбайт.
Размер кода или данных ограничен адресной памятью (1 Мбайт).
tiny 64 Кб всего
small 64 Кб кода и 64 Кб данные
medium 1Мб код, 64 Кб данные
compact 64 Кб код, 1Мб данные
large 1Мб код, 1Мб данные
huge тоже что large, но размер статических данных может превышать 64 Кб.
В huge для статистических данных выделяют более 1 сегмента.
Распределение данных по сегментам и управление перехода от
сегмента к сегменту берет на себя компилятор. Для каждого модуля можно выделить более одного сегмента статических данных.
ES - дополнительный сегмент регистр в любой модели памяти.
int far array [30000];
char far a [70000]; - ошибка более 64кб.
char huge b[70000]; -верно.
Для "малых" моделей все указатели типа near, для больших - far. Для указателей на функции near для tiny, small,compact, far в остальных. DS для near указывает на данные, CS -для near указывает на функции.
Размер кода тоже не может превышать 64кб. Для любого модуля заводится свой сегмент кода. Общий размер памяти выделяется для хранения кода не более 1 Мб для medium, large, huge.
Если все функции в одном файле, то все указатели типа near. Если несколько модулей, но они не обращаются друг к другу, тоже самое. Но если есть обращения функций одного модуля к функциям другого, они должны быть описаны как far функции.
void near fn (int arg);
fn (1);
SP: смещение адреса
SP + 2: arg.
void far ff(int arg);
ff(2);
SP: смещение адреса
SP + 2: сегмент
SP + 4: arg.
huge fn - настройка регистра DS на сегмент статических данных того модуля, которому принадлежит функция. Для far функции значения DS меняется.
Для совместной компляции нескольких модулей создается файл-проект. Проект создается через пункт меню Project - проект, где указываются все компилируемые файлы. Для этого используется подпункт меню:
Open Project -> Insert - добавить модуль
Delete - удалить модуль
Дата добавления: 2016-02-02; просмотров: 1227;