Сортировка слиянием. Сортировка слиянием является намного более эффективным алгоритмом сортировки по сравнению с ранее рассмотренными
Сортировка слиянием является намного более эффективным алгоритмом сортировки по сравнению с ранее рассмотренными. Предположим, имеется случайный набор целых чисел, требующий сортировки:

Разобьем данный массив на две равные половины:

А затем каждую из половин разобьем еще надвое:

И т.д., пока не дойдет до массивов, состоящих не более чем из двух элементов:

Отсортировать такие массивы из двух элементов не составляет никакого труда - достаточно сравнить 2 числа и переставить их местами, если это необходимо:

Далее следует объединить (“слить”) соседние массивы таким образом, чтобы получить один вдвое больший отсортированный массив вместо двух. Поскольку две объединяемые части к этому моменту уже отсортированы, слияние осуществляется выбором наименьшего из значений в двух массивах при последовательном проходе:

Слияние следует повторить на следующем уровне:

И т.д, пока не будет получен отсортированный массив исходного размера:

Оценим вычислительную сложность данного алгоритма. В общем виде, алгоритм разбивает задачу на 2 подзадачи равного размера и вызывает для их обработки сам себя рекурсивно, а затем осуществляет процедуру слияния двух массивов в один больший. Т.е.:
TSORT(N)=2TSORT(N/2)+TMERGE
Процедура слияния последовательно проходит два отсортированных массива-операнда, и, очевидно, обладает линейной вычислительной сложностью. Соответственно, рекуррентное соотношение выше имеет следующий вид:
TSORT(N)=2TSORT(N/2)+N
Аналогично процессу раскрытия, предложенному при разъяснении алгоритма бинарного поиска, предположим, что существует некоторое число M, такое что 2M=N. Тогда:
TSORT(2M)=2TSORT(2M-1)+2M
Разделив левую и правую часть уравнения на 2M, получим:
TSORT(2M)2M=2TSORT(2M-1)2M+1=TSORT(2M-1)2M-1+1=TSORT(2M-2)2M-2+2=...
Поэтапно раскрывая рекурсию шаг за шагом, получим следующее соотношение:
TSORT(2M)2M=MTSORT(2M)=2MM
Возвращаясь к оригинальному количеству элементов, получим линейно-логарифмическую вычислительную сложность, что существенно лучше квадратичной сложности предыдущих рассмотренных алгоритмов сортировки:
TSORT(N)=Nlog2(N)
Если количество входных данных невелико, скажем, N<10, простейшие алгоритмы сортировки будут выполняться за меньшее время, чем алгоритм слияния, однако при возрастании N выигрыш слияния станет очевиден. Этот факт можно использовать для комбинирования алгоритмов. Если в результате разбиения исходного массива на одном из уровней получен массив с длиной до 10 элементов, можно применить другой алгоритм сортировки, например, сортировку выбором. Это позволит повысить производительность сортировки слиянием в целом.
Ниже представлена программная реализация данного подхода:
// Вспомогательная функция слияния двух отсортированных массивов в один
voidmergeSorted ( const int* _pFirst, int_firstSize,
const int* _pSecond, int_secondSize,
int* _pTarget )
{
// Поддерживаем 3 текущих индекса:
// - индекс в целевом массиве (targetIndex)
// - индекс в первом массиве-операнде (firstIndex)
// - индекс во втором массиве-операнде (secondIndex)
// Проходим по массивам-операндам и формируем целевой массив
intfirstIndex = 0, secondIndex = 0, targetIndex = 0;
while( firstIndex < _firstSize && secondIndex < _secondSize )
{
// Если число из первого массива не больше числа из второго - оно идет первым
if( _pFirst[ firstIndex ] <= _pSecond[ secondIndex ] )
{
_pTarget[ targetIndex ] = _pFirst[ firstIndex ];
++ firstIndex;
}
// Иначе берется число из второго массива
Else
{
_pTarget[ targetIndex ] = _pSecond[ secondIndex ];
++ secondIndex;
}
++ targetIndex;
}
// Возможно второй массив был короче. Дописываем оставшиеся элементы 1-го в конец
if( firstIndex < _firstSize )
memcpy( _pTarget + targetIndex,
_pFirst + firstIndex,
sizeof( int) * ( _firstSize - firstIndex )
);
// Аналогично для случая, если первый массив был короче.
else if( secondIndex < _secondSize )
memcpy( _pTarget + targetIndex,
_pSecond + secondIndex,
sizeof( int) * ( _secondSize - secondIndex )
);
}
// Основная функция сортировки слиянием
voidmergeSort ( int* _pData, int_N )
{
// Для малых N используем сортировку выбором
if( _N < 10 )
selectionSort( _pData, _N );
Else
{
// Вычислияем размеры половин (могут отличаться на 1 при нечетном N)
inthalfSize = _N / 2;
intotherHalfSize = _N - halfSize;
// Формируем первую половину в дополнительном массиве N/2
int* pFirstHalf = new int[ halfSize ];
memcpy( pFirstHalf, _pData, sizeof( int) * halfSize );
// Формируем вторую половину в дополнительном массиве N/2
int* pSecondHalf = new int[ otherHalfSize ];
memcpy( pSecondHalf, _pData + halfSize, sizeof( int) * otherHalfSize );
// Сортируем половины рекурсивно
mergeSort( pFirstHalf, halfSize );
mergeSort( pSecondHalf, otherHalfSize );
// Осуществляем слияние отсортированных половин в единый массив
mergeSorted( pFirstHalf, halfSize, pSecondHalf, otherHalfSize, _pData );
// Освобождаем временные массивы
delete[] pFirstHalf;
delete[] pSecondHalf;
}
}
Ниже приведены результаты измерения производительности сортировки данной реализации, подтверждающие существенное превосходство над простейшими методами:
| Размер массива | Случайные данные | Отсортированные данные | Данные в обратном порядке |
| 500 000 | 0,235s | 0,166s | 0,172s |
| 200 000 | 0,104s | 0,073s | 0,074s |
| 100 000 | 0,050s | 0,036s | 0,036s |
| 50 000 | 0,025s | 0,017s | 0,017s |
| 20 000 | 0,012s | 0,008s | 0,008s |
| 10 000 | 0,006s | 0,004s | 0,004s |
Если отключить использование сортировки выбором для нижних уровней разбиения, а пользоваться идеей базового алгоритма, очевидно падение производительности, что подтверждает изначально выдвинутую гипотезу для малых N:
| Размер массива | Случайные данные | Отсортированные данные | Данные в обратном порядке |
| 500 000 | 0,520s | 0,452s | 0,458s |
| 200 000 | 0,247s | 0,221s | 0,217s |
| 100 000 | 0,121s | 0,111s | 0,108s |
| 50 000 | 0,064s | 0,055s | 0,053s |
| 20 000 | 0,026s | 0,019s | 0,020s |
| 10 000 | 0,014s | 0,011s | 0,010s |
Недостатком алгоритма сортировки слиянием является дополнительный расход памяти для хранения временных массивов-половин. Преимуществом - стабильное время выполнения на любом наборе входных данных.
Быстрая сортировка
Еще одним алгоритмом, в среднем выполняющимся с вычислительной сложностью O(Nlog2(N)), является быстрая сортировка. По сравнению с сортировкой слиянием, преимуществом быстрой сортировки является отсутствие необходимости в значительном объеме дополнительной памяти для хранения временных массивов. Быстрая сортировка модифицирует исходный массив непосредственно (in-place).
Суть алгоритма сводится к следующему:
- Тем или иным образом выбирается некоторый опорный элемент (pivot) в исходном массиве. Например, в качестве опорного элемента может быть случайная позиция, либо серединная позиция.
- Все элементы, меньшие опорного, располагаются левее, а все элементы большие опорного - правее.
- Массив условно разбивается на 2 части по опорному элементу, которые сортируются рекурсивно тем же алгоритмом.
- Как и в сортировке слиянием, по достижению некоторого граничного количества элементов, например N < 10, вместо дальнейшей рекурсии имеет смысл использовать простейший алгоритм сортировки, такой как сортировка выбором.
Продемонстрируем работу данного алгоритма в графической форме, используя тот же самый массив, что и в примере сортировки слиянием. Для упрощения восприятия, не будем применять сортировку выбором при N < 10, а доведем разбиение до минимального количества элементов. В качестве опорного элемента в данном случае будем брать серединную позицию. Итак, для исходного массива из 16 элементов серединной позицией является 8 со значением 12.

Необходимо переупорядочить элементы массива таким образом, чтобы слева от выбранного опорного значения 12 находились все значения, меньшие 12, а правее - большие. Начнем двигаться одновременно слева и справа:

Передвинем индекс слева на ближайшую позицию, в которой находится число, большее или равное опорному. В данном случае, самое первое число уже удовлетворяет данному критерию. Аналогично, найдем позицию для правого индекса с числом, которое меньше опорного элемента. В данном случае, таким числом является 11:

Переставим эти элементы местами:

Продолжим аналогичную процедуру. Следующим ближайшим значением слева, большим или равным опорному, является 17. А ближайшим большим или равным 12, является 5:

Поменяем эти значения местами:

Продолжим процедуру аналогичным образом, пока индексы не пересекутся между собой:

Переставим местами очередную пару:

Продолжим перестановки, и, наконец, достигнем ситуации, в которой индексы пересекутся:



В результате всех приведенных шагов, получены 2 части массива - элементы с индексами от 0 до 4 меньше опорного значения 12, а элементы с индексами от 5 до 15 - больше либо равны 12. Далее процесс следует продолжить рекурсивно на этих частях (при этом массивы нужно разделить лишь логически, копирования не потребуется):

Обработаем аналогично первую часть массива. Серединным элементом является 12:

Потребуются следующие перестановки:
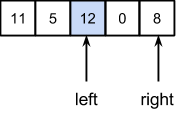
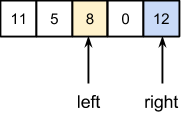
Далее индексы пересекутся, и придется обрабатывать части 11, 5, 8, 0 и 12 отдельно друг от друга. С частью, состоящей из одного элемента 12, делать ничего не нужно. Далее приведено пошаговое выполнение над первой частью из 4 элементов с серединой 8:
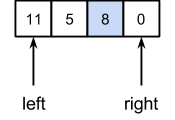
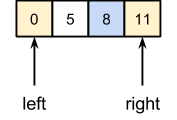
Далее массив уже является отсортированным. Итак, возвращаемся на предыдущий уровень, и получим отсортированную часть массива:

Проведем аналогичные действия с оставшейся частью массива:



Далее от массива отколется элемент 14, и сортировка продолжится с серединным элементом 41:
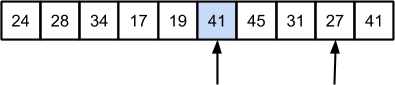
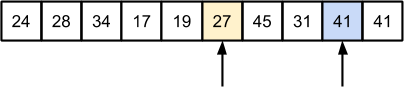
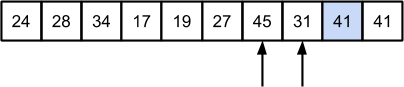
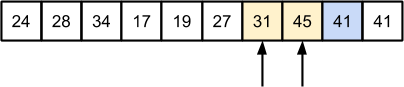
Далее, разделяем массив на две части для рекурсивной обработки:

С правой частью задача сводится к элементарной:


В левой части потребуется большее число шагов:




Значение 17 “откалывается”, аналогичная ситуация произойдет со следующим значением 19:

Далее серединным значением является 28:
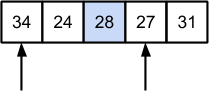

Дальнейшее разбиение и обработка частей массивов очевидны. В результате будет получен отсортированный фрагмент:

Возвращаясь по рекурсии вверх, логически сформируем итоговый отсортированный массив - физически никаких итоговых действий по слиянию не потребуется:




Оценим вычислительную сложность данного алгоритма. Предположим, что выбор опорного элемента разбивает исходный массив на 2 приблизительно равные части. В таком случае время сортировки определяется временем разбиения + двукратным временем сортировки половин:
TSORT(N)=TPARTITION+2TSORT(N/2)
Алгоритм разбиения обладает линейной сложностью, т.к. индексы движутся навстречу друг другу и проходят элементы не более 1 раза. Таким образом, получим рекуррентное соотношение, аналогичное оценке алгоритма сортировки слиянием:
TSORT(N)=N+2TSORT(N/2)
Выше уже было доказано, что такое соотношение раскрывается как линейно-логарифмическое:
TSORT(N)=Nlog2(N)
Как это было наглядно продемонстрировано в примере, предположение о разбиении массива на 2 равные половины является чересчур оптимистичным. В худшем случае, от массива на каждом очередном шаге может “откалываться” лишь одно число, что существенно видоизменит рекуррентное соотношение:
TSORT(N)=N+1+TSORT(N-1)
Раскрывая рекурсию, получим следующий ряд:
TSORT(N)=(N+1)+(N-1+1)+TSORT(N-2)=2N+1+TSORT(N-2)=... =
=(N-1)N+1+1
Из чего, делаем вывод, что в самом худшем случае, вычислительная сложность быстрой сортировки стремится к квадратичной:
TSORT(N)=N2
На практике, время выполнения быстрой сортировки в среднем случае находится между линейно-логарифмической и квадратичной функцией от N, однако можно подобрать случаи комбинаций входных данных, при которых поведение будет близким к квадратичному. Это делает этот привлекательный алгоритм нестабильным.
Фактически, все определяется выбором качественного опорного элемента, разбивающего массив на максимально равные части. Предсказать такую позицию без сложной обработки невозможно, поэтому рациональной стратегией является выбор позиции случайным образом. Это вносит вероятностную составляющую во время выполнения алгоритма, однако, приводит к неплохим результатам для подавляющего большинства сортируемых наборов данных.
Существуют и другие стратегии выбора опорного элемента - например, подсчет среднего значения, выбор наибольшего из двух первых или последних значений, среднее из трех случайных позиций.
Ниже представлена программная реализация описанного алгоритма, при чем при выборе опорного элемента используется случайная позиция от 0 до N - 1:
voidquickSort ( int* _pData, int_N )
{
// На малом количестве элементов используем алгоритм сортировки выбором
if( _N < 10 )
{
selectionSort( _pData, _N );
return;
}
intleftIndex = -1, rightIndex = _N;
// Случайным образом выбираем опорный элемент
intpivotIndex = rand() % _N;
intpivot = _pData[ pivotIndex ];
// Цикл перераспределения данных вокруг опорного элемента
while( true)
{
// Двигаем индекс слева до позиции, равной или превышающей опорный элемент
while( leftIndex < _N && _pData[ ++ leftIndex ] < pivot );
// Двигаем индекс справа в обратном направлении до меньшего опорному значения
while( rightIndex >= 0 && pivot < _pData[ --rightIndex ] )
if( rightIndex == leftIndex ) // Прерываемся при пересечении индексов
break;
// Перераспределение завершено
if( leftIndex >= rightIndex )
break;
// Меняем местами элементы, стоящие не на своих позициях
int temp = _pData[ leftIndex ];
_pData[ leftIndex ] = _pData[ rightIndex ];
_pData[ rightIndex ] = temp;
}
// Особый случай - вытеснение опорного элемента в крайнее положение
if( leftIndex == 0 )
leftIndex = 1;
else if( leftIndex == _N )
leftIndex = _N - 1;
// Рекурсивно сортируем две части массива отдельно
quickSort( _pData, leftIndex );
quickSort( _pData + leftIndex, _N - leftIndex );
}
Несмотря на возможную деградацию алгоритма быстрой сортировки до квадратичной вычислительной сложности, именно его используют на практике наиболее часто. В частности, средства сортировки в стандартной библиотеке C (функция qsort) и С++ (алгоритм std::sort) основаны именно на алгоритме быстрой сортировки. В среднем, быстрая сортировка опережает сортировку слиянием, т.к. не использует копирование данных во временные массивы. Ниже представлены эквивалентные замеры производительности, подтверждающие данный вывод:
| Размер массива | Случайные данные | Отсортированные данные | Данные в обратном порядке |
| 500 000 | 0,165s | 0,087s | 0,098s |
| 200 000 | 0,063s | 0,026s | 0,030s |
| 100 000 | 0,031s | 0,012s | 0,014s |
| 50 000 | 0,015s | 0,006s | 0,007s |
| 20 000 | 0,006s | 0,002s | 0,002s |
| 10 000 | 0,002s | 0,001s | 0,001s |
Сравнение же быстрой сортировки с простейшими методами с квадратичной сложностью для достаточно больших N окончательно убеждает в важности выбора правильного алгоритма. Так для N=100000 элементов, разница между этими двумя алгоритмами для случайного набора данных составляет 23.156 / 0,031 ~= 747 раз!
Дата добавления: 2016-01-29; просмотров: 2671;