Кодирование аудио: основные идеи
Кодирование аудио выполняется очень похоже на кодирование видео (рис. 3.19): здесь мы также встречаем DCT и энтропийное кодирование. Но есть и существенные отличия. В частности, кодирование производится в границах узких полос частот (всего этих полос 32), "вырезаемых" из сигнала полосовыми фильтрами. Кодирование внутри каждой такой "полосы" производится отдельно, с параметрами, определяемыми "блоком управления" на основании психоакустической модели.
Разбиение на полосы позволяет очень гибко кодировать звук в разных диапазонах частот. Как мы помним, не все частоты человеческое ухо одинаково хорошо воспринимает — поэтому "плоховоспринимаемые" частоты можно кодировать с большим сжатием и худшим качеством, что позволяет получить более низкий битрейт для всего сигнала в целом.
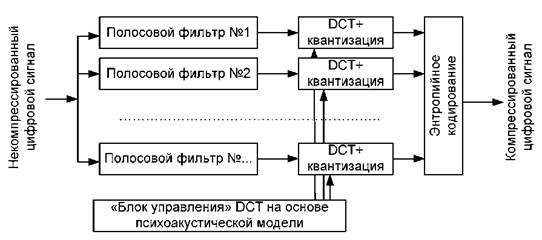
Рис. 3.19. Упрощенная схема кодера звука
После разбиения на полосы, каждая такая полоса преобразуется при помощи дискретно-косинусного преобразования (DCT), которое мы встречали ранее, когда говорили о видеокомпрессии.
Звуковой сигнал представляет собой сложное колебание в диапазоне частот от 20 Гц до 20 000 Гц. Математиками доказано, что такое сложное колебание может быть представлено как сумма синусоидальных и косинусоидальных колебаний разных частот и амплитуд. Совокупность этих колебаний называется спектром. Суть преобразования DCT для звука и состоит в том, что исходное колебание преобразуется в набор частот и амплитуд колебаний спектра. Таким образом, отпадает необходимость передавать через канал связи само колебание — можно передать только числа, характеризующие спектр: список частот и амплитуд колебаний спектра, сумма которых и даст исходное звуковое колебание. Когда мы рассматривали компрессирование изображения, мы на самом деле делали то же самое, только для случая двумерного (т. е. графически представляемого на плоскости) сигнала.
После разбиения на участки выполняется энтропийное кодирование, подобное описанному ранее для компрессии видео.
Дата добавления: 2015-10-19; просмотров: 1107;