Индуктивные системы
Обобщение примеров по принципу от частного к общему сводится к выявлению подмножества примеров, относящихся к одним и тем же подклассам, и определению для них значимых признаков.
Процесс классификации примеров осуществляется следующим образом:
1. Выбирается признак классификации из множества заданных признаков (последовательно или по какому-либо правилу, например в соответствии с максимальным числом получаемых подмножеств).
2. По значению выбранного признака множество примеров разбивается на подмножества.
3. Проверяется принадлежность каждого подмножества одному подклассу.
4. Если какие-то подмножества принадлежат одному подклассу, т. е. у всех подмножеств совпадает значение классообразующего признака, то процесс классификации заканчивается (при этом остальные признаки классификации не рассматриваются).
5. Для подмножеств с несовпадающим значением классообразующего признака процесс классификации продолжается, начиная с пункта 1. (Каждое подмножество становится классифицирующим множеством).
Процесс классификации может быть представлен в виде "дерева" решений, в котором в промежуточных узлах находятся значения признаков последовательной классификации, а в конечных узлах – значения признака принадлежности определенному классу. Пример построения "дерева" решений на основе фрагмента таблицы (табл. 1.1) показан на рис. 1.10.
Таблица 1.1
| Классообразующий признак | Признаки Классификации | |||
| Цена | Спрос | Конкуренция | Издержки | Качество |
| Низкая | Низкий | Маленькая | Маленькие | Низкое |
| Высокая | Низкий | Маленькая | Большие | Высокое |
| Высокая | Высокий | Маленькая | Большие | Низкое |
| Высокая | Высокий | Маленькая | Маленькие | Высокое |
| Высокая | Высокий | Маленькая | Маленькие | Низкое |
| Высокая | Высокий | Маленькая | Большие | Высокое |

Рис. 1.10. Фрагмент "дерева" решений
Анализ новой ситуации сводится к выбору ветви "дерева", которая полностью определяет эту ситуацию. Поиск решения осуществляется в результате последовательной проверки признаков классификации. Каждая ветвь “дерева” соответствует одному правилу решения:
Если Спрос=“низкий” и Издержки =“маленькие”,
То Цена =“низкая”
Нейронные сети
Функция, называемая по аналогии с элементарной единицей человеческого мозга – нейроном, отображает зависимость значения выходного признака (Y) от взвешенной суммы (U) значений входных признаков (Xi), в которой вес входного признака (Wi) показывает степень влияния входного признака на выходной:
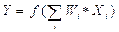 .
.
В результате обучения на примерах строятся математические решающие функции (передаточные функции или функции активации), которые определяют зависимости между входными (Xi) и выходными ( Yi) признаками (сигналами) (рис. 1.11).
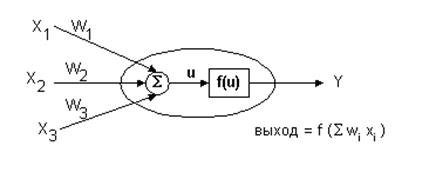
Рис. 1.11. Решающая функция – "нейрон"
Решающие функции используются при решении задач классификации на основе сопоставления их значений при различных комбинациях значений входных признаков с некоторым пороговым значением. В случае превышения заданного порога считается, что нейрон “сработал” и таким образом распознал некоторый класс ситуаций. Нейроны используются и в задачах прогнозирования, когда по значениям входных признаков после их подстановки в выражение решающей функции получается прогнозное значение выходного признака.
Функциональная зависимость может иметь линейную форму но, как правило, используется сигмоидальная (логистическая) форма, которая позволяет вычленять более сложные пространства значений выходных признаков (рис. 1.12).
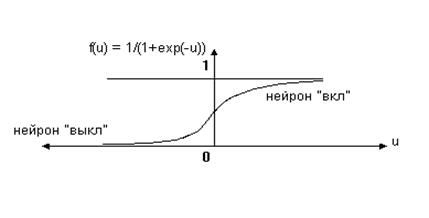
Рис. 1.12. Сигмоидальная (логистическая) функция
Нейроны могут быть связаны между собой, когда выход одного нейрона является входом другого. Таким образом строится нейронная сеть (рис. 1.13), в которой нейроны, находящиеся на одном уровне, образуют слои.

Рис. 1.13. Нейронная сеть
Обучение нейронной сети сводится к определению связей (синапсов) между нейронами и установлению силы этих связей (весовых коэффициентов). Алгоритмы обучения нейронной сети упрощенно сводятся к определению зависимости весового коэффициента связи двух нейронов от числа примеров, подтверждающих эту зависимость.
Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки. Целевая функция по этому алгоритму должна обеспечить минимизацию квадрата ошибки в обучении на основе примеров:
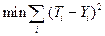 ,
,
где Ti – заданное значение выходного признака по i-му примеру;
Yi – рассчитанное значение выходного признака по i-му примеру.
Сущность алгоритма обратного распространения ошибки сводится к следующему:
1. Задать произвольно небольшие начальные значения весов связей нейронов.
2. Для всех обучающих пар "значения входных признаков – значения выходных признаков" (примеров из обучающей выборки) вычислить выход сети (Y).
3. Выполнить рекурсивный алгоритм, начиная с выходных узлов по направлению к первому скрытому слою, пока не будет достигнут минимальный уровень ошибки.
Вычислить веса на (t + 1)-м шаге по формуле:
 ,
,
где 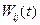 – вес связи от скрытого i-го нейрона (или от входа)
– вес связи от скрытого i-го нейрона (или от входа)
к j-му нейрону на шаге t;
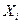 – выходное значение i-го нейрона;
– выходное значение i-го нейрона;
 – коэффициент скорости обучения;
– коэффициент скорости обучения;
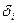 – ошибка для j-го нейрона.
– ошибка для j-го нейрона.
Если j-й нейрон – выходной, то
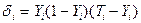 .
.
Если j-й нейрон находится в скрытом внутреннем слое, то
 ,
,
где к – индекс всех нейронов в слое, расположенном вслед за слоем с j-м нейроном.
Достоинством нейронных сетей перед индуктивным выводом является возможность решения не только классифицирующих, но и прогнозных задач. Нелинейный характер зависимости позволяет строить более точные классификации.
Процесс решения задач в силу проведения матричных преобразований протекает очень быстро. Фактически в нейронной сети имитируется параллельный процесс вычислений в отличие от последовательного в индуктивных системах. Нейронные сети могут быть реализованы и аппаратно в виде нейрокомпьютеров с ассоциативной памятью.
В последнее время нейронные сети стремительно развиваются и очень активно используются в финансовой области. В качестве примеров внедрения нейронных сетей можно назвать:
· "Система прогнозирования динамики биржевых курсов для Chemical Bank" (фирма Logica).
· "Система прогнозирования для Лондонской фондовой биржи" (фирма SearchSpace).
· "Управление инвестициями для Mellon Bank" (фирма NeuralWare) и др.
Среди инструментальных средств разработки нейронных сетей следует выделить такие: NeurOn-line (фирма GENSYM), NeuralWorks Professional II/Plus (фирма NeuralWare), отечественную разработку FOREX-94 (Уралвнешторгбанк) и др.
Системы, основанные на прецедентах(Case-based reasoning)
В этих системах база знаний содержит описания не обобщенных ситуаций, а собственно сами ситуации или прецеденты ситуаций. Поиск решения сводится к поиску по аналогии (абдуктивный вывод), т.е. от часного к частному и включает следующие шаги:
1. Получение подробной информации о текущей проблеме.
2. Сопоставление полученной информации со значениями признаков прецедентов из базы знаний.
3. Выбор наиболее близкого к рассматриваемой проблеме прецедента из базы знаний.
4. В случае необходимости выполняется адаптация выбранного прецедента к текущей проблеме.
5. Проверка корректности каждого полученного решения.
6. Внесение детальной информации о полученном решении в базу знаний.
Так же, как и для индуктивных систем, прецеденты описываются множеством признаков, на основе которых определяются индексы быстрого поиска. Но в отличие от индуктивных систем допускается нечеткий поиск с получением множества допустимых альтернатив, каждая из которых оценивается некоторым коэффициентом уверенности. Далее наиболее подходящие решения адаптируются по специальным алгоритмам к реальным ситуациям. Обучение системы сводится к запоминанию каждой новой обработанной ситуации с принятыми решениями в базе прецедентов.
Системы, основанные на прецедентах, применяются как системы распространения знаний с расширенными возможностями или как системы контекстной помощи.
В качестве примера инструментального средства поддержки баз знаний прецедентов, распространяемого в России, можно привести систему CBR-Express Inference (дистрибьютор фирма "Метатехнология").
Информационные хранилища(Data Warehouse)
В отличие от интеллектуальной базы данных информационное хранилище предназначено для оперативного анализа данных (реализация OLAP-технологии), т.е. извлечение из оперативной базы данных значимой информации. Извлечение знаний из баз данных осуществляется регулярно, например ежедневно.
Типичными задачами оперативного ситуационного анализа являются:
· Определение профиля потребителей конкретного товара.
· Предсказание изменений ситуации на рынке.
· Анализ зависимостей признаков ситуаций (корреляционный анализ) и др.
Для извлечения значимой информации из баз данных используются специальные методы (Data Mining или Knowledge Discovery):
· метод многомерных статистических таблиц;
· индуктивный метод построения деревьев решений;
· нейронные сети.
Формулирование запроса осуществляется в результате применения интеллектуального интерфейса, позволяющего в диалоге гибко определять значимые признаки анализа.
Информационные хранилища на практике все в большей степени демонстрируют необходимость интеграции интеллектуальных и традиционных информационных технологий, комбинированного использования различных методов представления и вывода знаний, усложнения архитектуры информационных систем.
Разработкой и распространением информационных хранилищ в настоящее время занимаются известные компьютерные фирмы, такие как IBM (Intelligent Miner), Silicon Graphics (MineSet), Intersolv (DataDirect, SmartData), Oracle (Express), SAS Institute (SAS/Assist) и др.
Дата добавления: 2015-10-13; просмотров: 2479;