Структуры данных файловой системы UNIX
Дисковый том UNIX состоит из следующих основных областей, показанных (не в масштабе) на рис. 3‑5:

Рис. 3‑5
· блок начальной загрузки (BOOT-сектор); его структура определяется не UNIX, а архитектурой используемого компьютера;
· суперблок – содержит основные сведения о дисковом томе в целом (размер логического блока и количество блоков, размеры основных областей, тип файловой системы, возможные режимы доступа), а также данные о свободном месте на диске;
· массив индексных дескрипторов, каждый из которых содержит полные сведения об одном из файлов, хранящихся на диске (кроме имени этого файла);
· область данных, состоящая из логических блоков (кластеров), которые используются для хранения файлов и каталогов (в UNIX используется сегментированное размещение файлов).
В отличие от системы FAT, где основные сведения о файле содержались в каталожной записи, UNIX использует более изощренную схему.
Запись каталога не содержит никаких данных о файле, кроме только имени файла и номера индексного дескриптора этого файла.
В ранних версиях UNIX каждая запись имела фиксированную длину 16 байт, из которых 14 использовались для имени и 2 для номера. В более современных версиях запись имеет переменный размер, что позволяет использовать длинные имена файлов.
Как и в системе FAT, в каждом каталоге первые две записи содержат специальные имена «..» (ссылка на родительский каталог) и «.» (ссылка на данный каталог).
Точнее, это в FAT сделано по примеру UNIX.
Нулевое значение номера соответствует удаленной записи каталога.
Все сведения о файле, кроме имени, содержатся в его индексном дескрипторе (inode). Такая схема делает возможными жесткие связи, описанные выше: любое количество записей из одного каталога или из разных каталогов может относиться к одному и тому же файлу. Для этого надо только, чтобы эти записи содержали один и тот же номер inode.
Индексные дескрипторы хранятся в массиве, занимающем отдельную область диска. Размер этого массива задается при форматировании, этот размер определяет максимальное количество файлов, которое можно разместить на данном томе.
Дескриптор содержит, прежде всего, счетчик жестких связей файла, т.е. число каталожных записей, ссылающихся на данный дескриптор. Этот счетчик изменяется при создании и удалении связей, его нулевое значение говорит о том, что файл перестал быть доступным и должен быть удален.
В дескрипторе содержатся тип и атрибуты файла, описанные выше. Наконец, здесь же содержатся данные о размещении файла, имеющие весьма оригинальную структуру (см. рис. 3‑6).
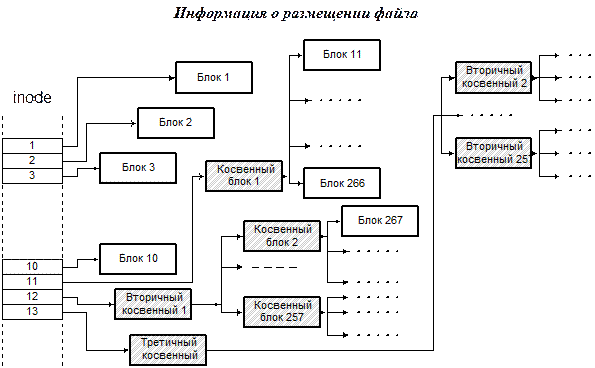
Рис. 3‑6
Размещение блоков файла задается массивом из 13 (в некоторых версиях 14) элементов, каждый из которых может содержать номер блока в области данных. Пусть, для определенности, блок равен 1 Кб, а его номер занимает 4 байта (обе эти величины зависят от версии файловой системы). Первые 10 элементов массива содержат номера первых 10 блоков от начала файла. Если размер файла превышает 10 Кб, то в ход идет 11-й элемент массива. Он содержит номер косвенного блока – такого блока в области данных, который содержит номера следующих 256 блоков файла. Таким образом, использование косвенного блока позволяет работать с файлами размером до 266 Кб, используя для этого один дополнительный блок. Если файл превышает 266 Кб, то в 12-ом элементе массива содержится номер вторичногокосвенного блока, который содержит до 256 номеров косвенных блоков, каждый из которых… Ну, вы поняли. Наконец, для очень больших файлов будет задействован 13-й элемент массива, содержащий номер третичного косвенного блока, указывающего на 256 вторичных косвенных.
Подсчитайте, какой максимальный размер файла может быть достигнут при такой схеме адресации блоков.
Недостатком описанной схемы является то, что доступ к большим файлам требует значительно больше времени, чем к маленьким. Если расположение первых 10 Кб данных файла записано непосредственно в индексном дескрипторе, то для того, чтобы прочитать данные, отстоящие, скажем, на 50 Мб от начала файла, придется сперва прочитать третичный, вторичный и обычный косвенные блоки.
Еще один важный вопрос для любой файловой системы – способ хранения данных о свободном месте. Для UNIX следует различать два вида свободных мест – свободные блоки в области данных и свободные индексные дескрипторы, которые бывают нужны при создании новых файлов. Количество тех и других может быть очень большим. В суперблоке UNIX имеются массивы для хранения некоторого количества номеров свободных блоков и свободных дескрипторов. Если исчерпаны номера свободных дескрипторов в суперблоке, то UNIX просматривает массив дескрипторов, находит в нем свободные и выписывает их номера в суперблок.
Сложнее обстоит дело со свободными блоками данных. Первый элемент размещенного в суперблоке массива номеров свободных блоков указывает на блок в области данных, который содержит продолжение этого массива и, в первом элементе, указатель на следующий блок продолжения. Когда системе нужны блоки дисковой памяти, она берет их из основного массива в суперблоке, а при исчерпании массива читает его продолжение в суперблок. При освобождении блоков происходит обратный процесс: их номера записываются в массив, а при переполнении массива все его содержимое переписывается в один из свободных блоков, номер которого заносится в первый элемент массива как адрес продолжения списка. На рис. 3‑7 показана структура списка свободных блоков.

Рис. 3‑7
Как нетрудно понять, из сказанного вытекает, что блоки диска распределяются «по стековому принципу»: блок, освобожденный последним, будет первым снова задействован.
Дата добавления: 2015-09-07; просмотров: 817;